大模型量化简介
本文记录下学习大模型量化过程中的过程,本文不涉及高深的各种量化策略以及量化效果对比,只是记录对量化过程的探索。量化的含义本质上很简单,即将模型的存储数据从浮点数转换为整数,从而降低显存使用,那这个过程中必然有数值的转换、模型保存、加载。但是在研究量化的过程中所用时间超过了之前的LoRA,因为实际过程中有很多坑,光看网上文章是不会理解的,具体来说,起码有下面几个:
- transformers自身支持的量化方案,也就是 load_in_8bit 参数需要依赖 bitsandbytes,这个库在Windows上支持很不友好,也依赖GPU。
- 直接使用quanto库进行量化有问题,需要optimum-quanto
- 量化效果不显著,是因为量化通常来说只量化Linear以及Norm层,很多层都不量化,比如用GPT2测试,就会有很多层不会量化
- 使用quanto的quantize进行量化之后,还需要freeze才会将weight改成INT8类型
下面开始对量化的探索。
量化简介
大模型量化指的是将模型参数从高精度(比如FP32, 4字节)转换为低精度(比如INT8, 1字节)的方法。下面这个图(来自:Huggingface 的量化基础)展示了量化的核心思想:
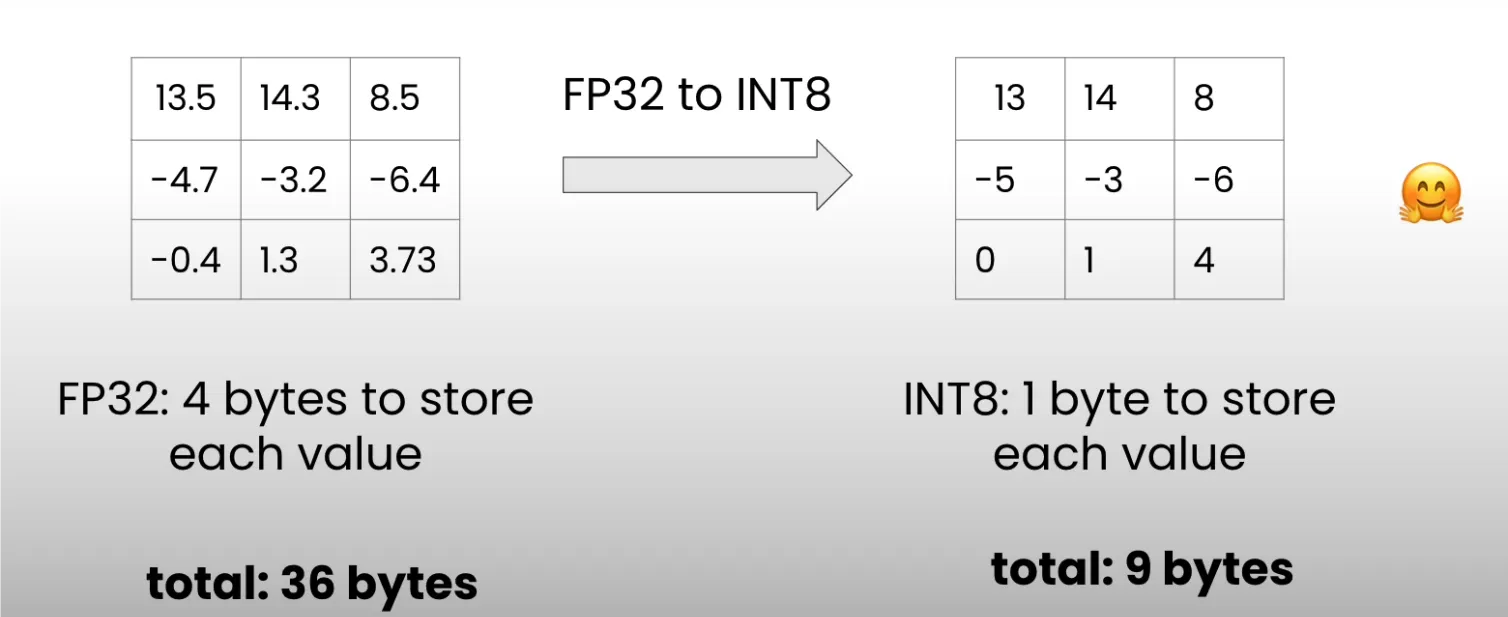
可以看到,量化之后使用的内存减少到了四分之一。
量化的核心就是怎么做这个映射,使得低精度的模型尽可能的准确。这里只介绍最简单的对称量化absmax。下面的图(来自:大模型量化总结 )展示了其基本思想,本质上就是将输入的最大值的绝对值映射到127上,从而将整个数据映射到-127到127之间,并且原始的高精度的0映射到低精度的0.
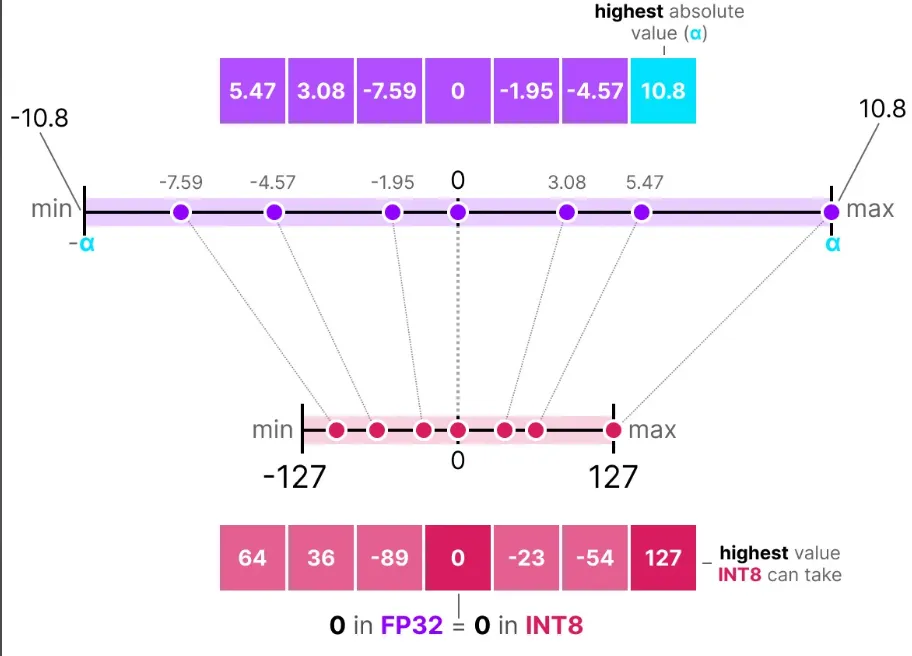
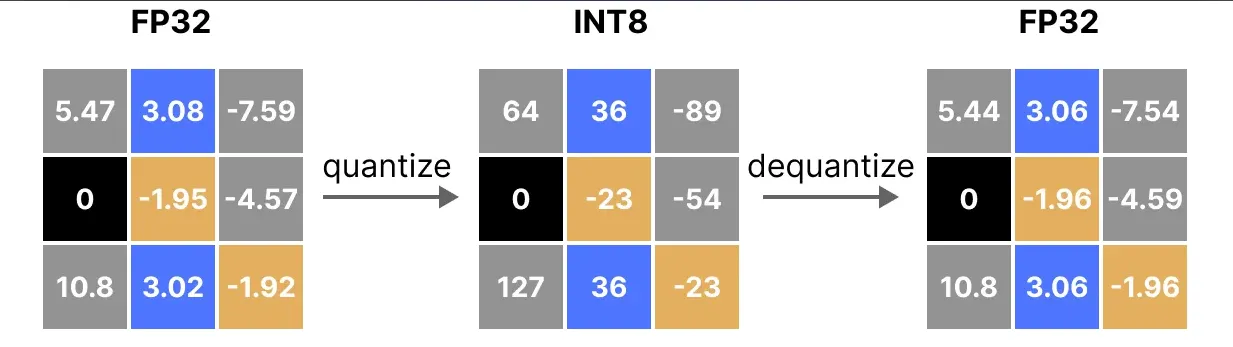
在反量化之后可以看到,精度有所丢失。
手动量化
参考 大语言模型量化原理和GPT-2量化实战 中的示例,这里手动进行abxmax量化实验。
def absmax_quantize(X):
# 计算比例因子
scale = 127 / torch.max(torch.abs(X))
# 量化
X_quant = (scale * X).round()
# 反量化
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequant
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
# 设置设备为cpu
device = 'cpu'
# 加载模型和分词器
model_id = 'gpt2'
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 打印模型大小
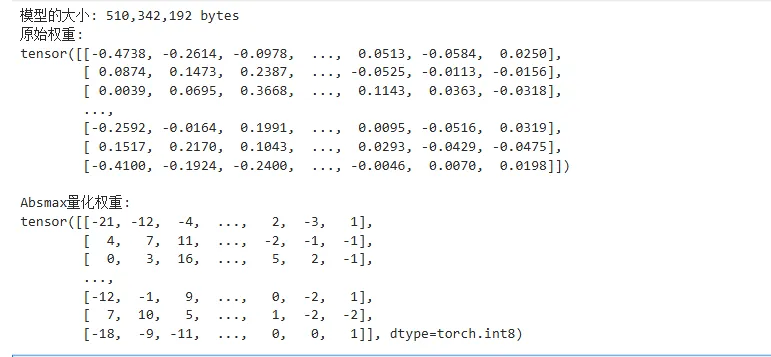
print(f"模型的大小: {model.get_memory_footprint():,} bytes")
# 提取第一个注意力层的权重
weights = model.transformer.h[0].attn.c_attn.weight.data
print("原始权重:")
print(weights)
# 用 absmax 方法量化
weights_abs_quant, _ = absmax_quantize(weights)
print("\nAbsmax量化权重:")
print(weights_abs_quant)
下面的输出可以看到,模型已经从高精度转换为低精度了。
下面直接使用GPT2进行量化:
import numpy as np
from copy import deepcopy
# 保存原始权重
weights = [param.data.clone() for param in model.parameters()]
# 创建量化模型副本
model_abs = deepcopy(model)
# 量化所有模型权重
weights_abs = []
for param in model_abs.parameters():
_, dequantized = absmax_quantize(param.data)
param.data = dequantized
weights_abs.append(dequantized)
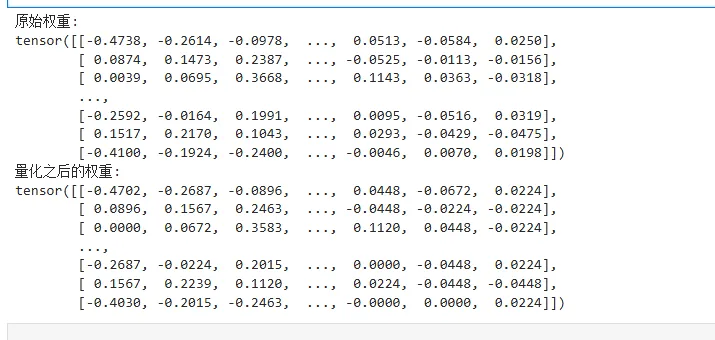
weights = model.transformer.h[0].attn.c_attn.weight.data
print("原始权重:")
print(weights)
weights1 = model_abs.transformer.h[0].attn.c_attn.weight.data
print("量化之后的权重:")
print(weights1)
注意absmax_quantize返回值的第二部分是量化之后反量化到对应精度的值,跟原始的高精度值会有一些区别,可以看到使用量化之后的INT8类型再反量化得到的精度跟原始精度有一些差异。
使用quanto库量化
下面研究使用quanto库进行量化
pip install optimum-quanto
量化并保存量化之后的模型,这里用Qwen2-0.5B-Instruct测试。
from transformers import AutoModelForCausalLM
from optimum.quanto import QuantizedModelForCausalLM, qint8
model = AutoModelForCausalLM.from_pretrained('Qwen/Qwen2-0.5B-Instruct')
qmodel = QuantizedModelForCausalLM.quantize(model, weights=qint8, exclude='lm_head')
qmodel.save_pretrained('./Qwen2-0.5B-Instruct-quantized')
加载量化模型,并且对比输出。
from optimum.quanto import QuantizedModelForCausalLM
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
model = AutoModelForCausalLM.from_pretrained('Qwen/Qwen2-0.5B-Instruct')
qmodel = QuantizedModelForCausalLM.from_pretrained('./Qwen2-0.5B-Instruct-quantized')
input_text = "Hello, who are you? "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = qmodel.generate(input_ids)
print(tokenizer.decode(outputs[0]))
outputs2 = model.generate(input_ids)
print(tokenizer.decode(outputs2[0]))

这里我们先看看量化之后在模型文件中是怎么提现的,然后分析量化模型的加载过程。从大小来看,数量确实小了,但也没有小多少,因为量化之后的文件还要存放额外的数据。
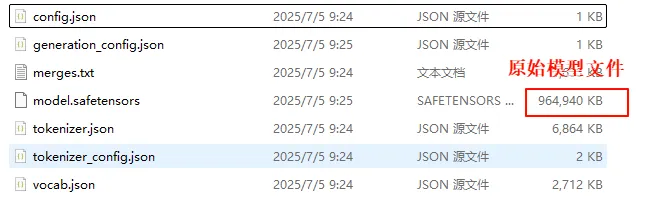
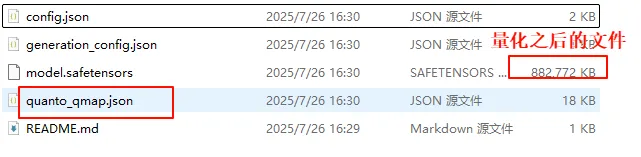
注意,量化之后的目录里面还有个quanto_qmap.json,这个文件保存了各个weight的配置,比如使用的量化方案。
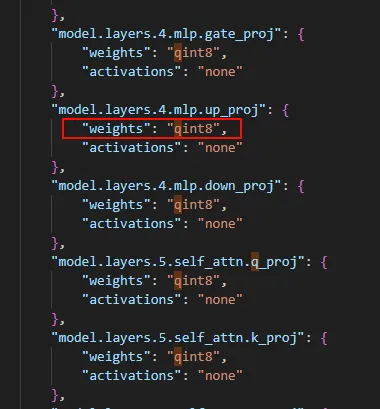
打开量化前后的model.saftensors文件,可以看到,量化前是BF16,量化后变为了I8
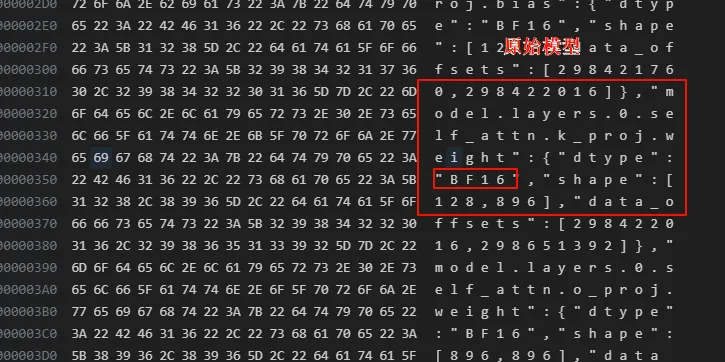
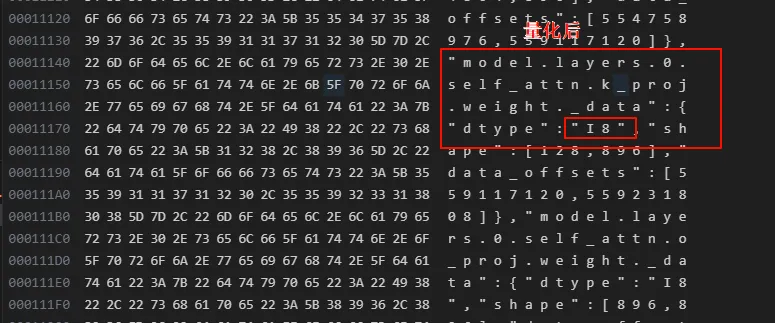
可以看到权重的dtype变了,并且所在的位置也不一样,一个直接是xxx.weight,一个是xxx.weight._data。 那为啥模型的大小没有小多少呢,可以看到量化之后的模型文件有很多的input_scale和output_scale,这个是用来在加载量化模型时候需要的。当然这个只是quanto这个库的行为,其他的量化方案可能采用不同的存储方案。
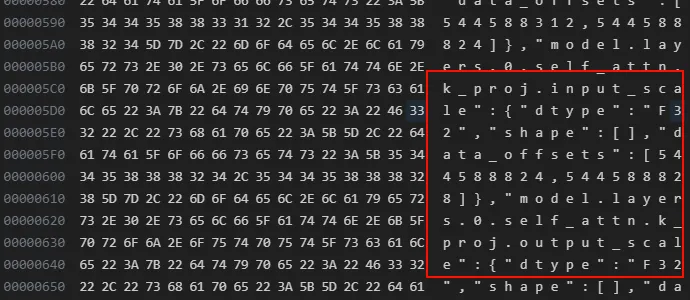
接下来调试量化模型的加载过程。首先通盘看一下量化前后的模型:
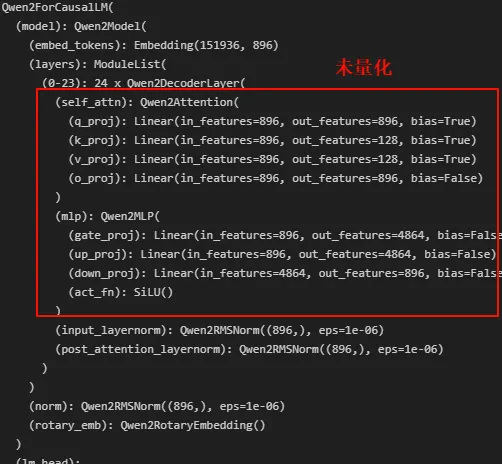
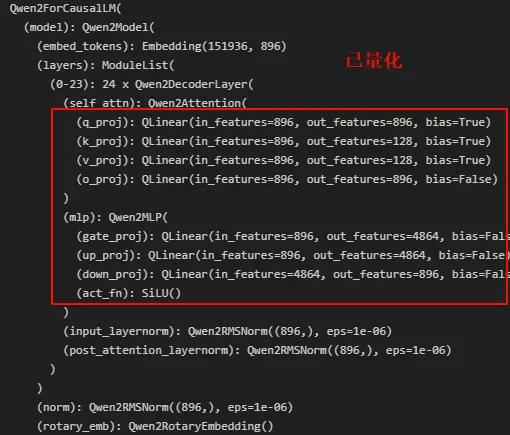
这里只量化了Linear层,变成了QLinear。接下来看看weight。
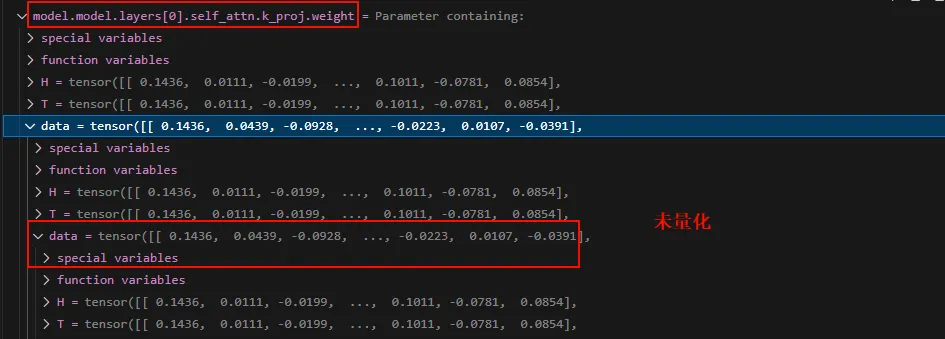
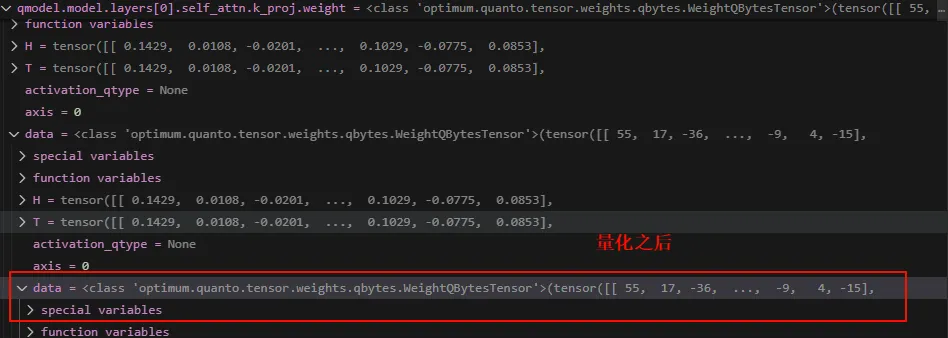
可以看到量化之后的weight是INT8的整数。 我们先直观看看量化前后在计算自注意力的时候的值,以layer 0的q计算为例。先看量化之后的:
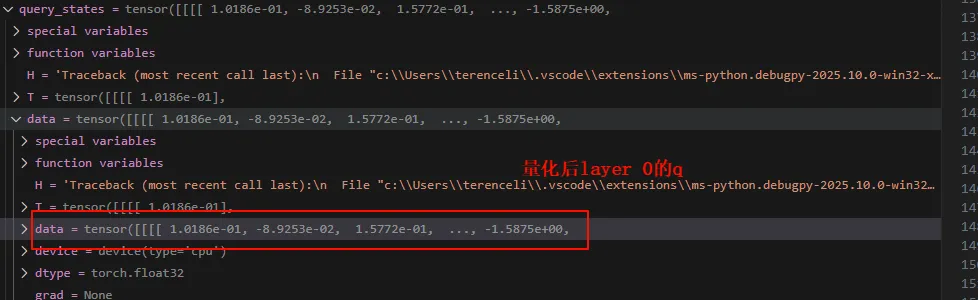
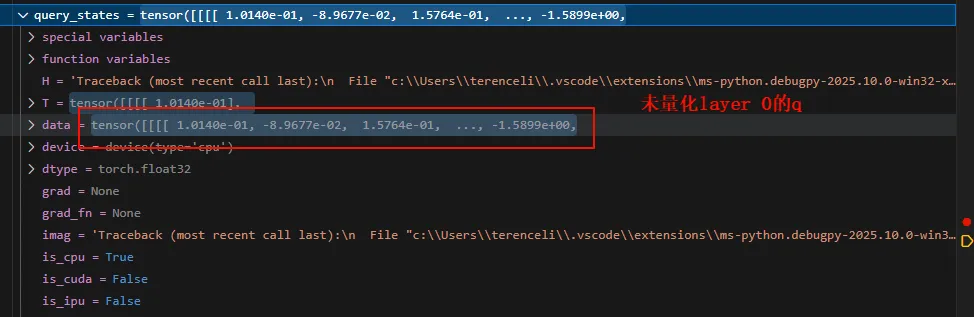
可以看到有差距,但是差距很小。 但是从前面的模型可以看到,量化之后的weight是INT8类型的,那为啥这里的计算是反量化之后的呢?答案隐藏在QLinear的forward中。 此时的input是输入的token(prefill阶段)经过embedding之后的矩阵,self.qweight是量化之后的weight。
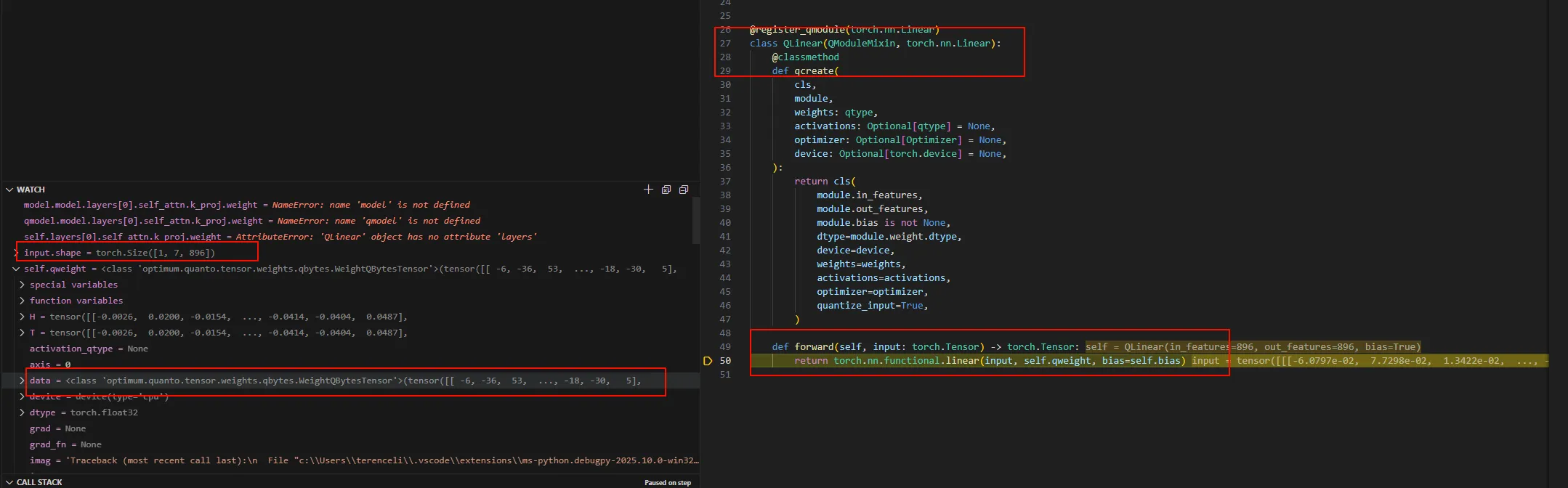
这里单步进去会进入到quanto的相关函数,最终在qbytes_mm函数中完成反量化的计算。
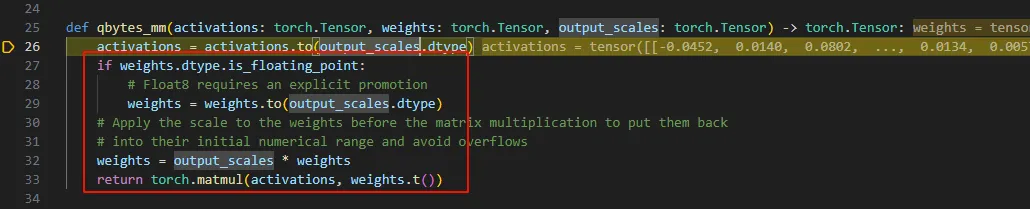
综上,我们完成分析了从量化到使用量化模型进行推理的全过程,整个过程如下:
- 模型在量化时,使用量化策略将高精度的模型参数转换为低精度的参数,保存到磁盘的模型会变小
- 量化模型在加载时是直接加载INT8到显存/内存,会减少显存的使用
- 量化模型在推理过程中会有一个反量化的过程,也就是将INT转换为浮点数的过程
Ref
blog comments powered by Disqus