Linux内核中从inode结构得到文件路径名
最近的一个需求,从文件的inode得到全路径名。顺便总结一下Linux系统中的file,path,dentry,inode结构。
1.概述
构成一个操作系统最重要的部分就是进程管理和文件系统了。
Linux最初采用的是minix的文件系统,minix是由Andrew S. Tanenbaum开发的用于实验性的操作系统,比如有一些局限性。后来经过一段时间的改进和发展,Linux开发出了ext2文件系统,当然后来逐渐发展除了ext3、ext4。为了使Linux支持各种不同的文件系统,Linux使用了所谓的虚拟文件系统VFS(Virtual Filesystem Switch),VFS提供一组标准的、抽象的文件操作,以系统调用的形式提供给用户程序,如read(),write(),lseek()等。这样,用户程序就可以把所有的文件都看作一致的、抽象的”VFS文件”,通过这些系统调用对文件进行操作,而无需关心具体的文件属于什么文件系统以及具体文件系统的设计和实现。VFS与具体文件系统的关系如图1所示。
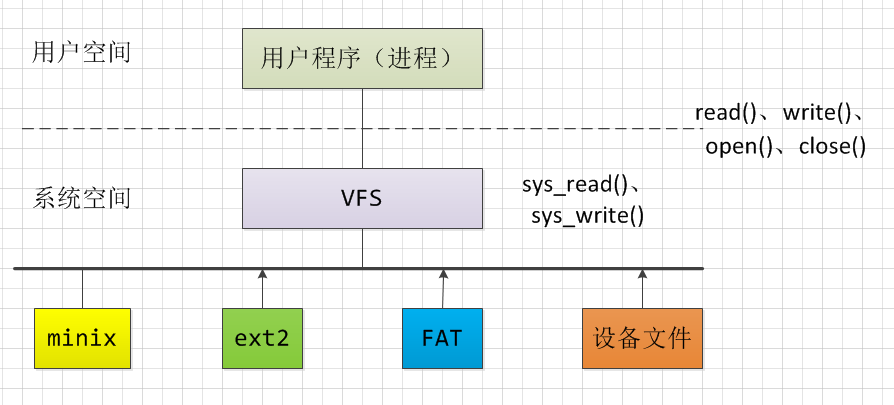
2.各个结构
不同的文件系统通过不同的程序来实现其各种功能,但是与VFS之间的界面则是有明确的定义。这个界面的主体就是file_operations数据结构。定义在include/linux/fs.h中:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
};
每个文件系统都有自己的file_operations结构,结构中的成分几乎全是函数指针,所以实际上是个函数跳转表,例如read就指向具体文件系统用来实现读文件操作的入口函数。
每个进程通过open()与具体的文件建立起连接,这种连接以一个file数据结构作为代表,结构中有个file_operations结构指针f_op。将file结构中的指针f_op设置成指向某个具体的file_operations结构,就指定了这个文件所属的文件系统。
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
进程的task_struct中有一个类型为struct files_struct的files域,记录了具体已打开的文件信息。files_struct的主体就是一个file结构数组。每打开一个文件以后,进程就通过一个“打开文件号”fid来访问这个文件,而fid实际上就是相应file结构在数组中的下标。file结构中海油一个指针f_dentry,指向该文件的dentry数据结构。每一个文件只有一个dentry结构,而可能有多个进程打开它。
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
unsigned int d_count; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
};
dentry结构中有一个指向inode的指针。dentry与inode结构所描述的目标是不一样的,因为一个文件可能对应多个文件名(链接)。所以dentry结构代表的是逻辑意义上的文件,记录的是其逻辑上的属性。而inode结构所代表的是物理意义上的文件,记录的是其物理上的属性;它们之间的关系是多对一的关系。这是因为一个已经建立的文件可以被连接 (link) 到其他文件名。dentry中还有个d_parent指向父目录的dentry结构。
inode数据结构比较大,就不列出来了。要注意的是inode结构中有一个i_dentry是所有与这个inode关联的dentry。凡是代表着这个文件的所有目录项都通过其dentry结构中的d_alias挂入相应inode结构中的 i_dentry 队列。
下面是需要注意的几点:
- 进程每打开一个文件,就会有一个file结构与之对应。同一个进程可以多次打开同一个文件而得到多个不同的file结构,file结构描述被打开文件的属性,如文件的当前偏移量等信息。
- 两个不同的file结构可以对应同一个dentry结构。进程多次打开同一个文件时,对应的只有一个dentry结构。dentry结构存储目录项和对应文件(inode)的信息。
- 在存储介质中,每个文件对应唯一的inode结点,但是每个文件又可以有多个文件名。即可以通过不同的文件名访问同一个文件。这里多个文件名对应一个文件的关系在数据结构中表示就是dentry和inode的关系。
- inode中不存储文件的名字,它只存储节点号;而dentry则保存有名字和与其对应的节点号,所以就可以通过不同的dentry访问同一个inode。
- 不同的dentry则是同个文件链接(ln命令)来实现的。
因此关系就是:进程->task_struct->files_struct->file->dentry->inode->Data Area
3.从inode得到文件绝对路径
有了上面的基础,从inode得到文件名就比较简单了,这里我假设文件只有一个路径,如果有很多路径改改就行了。
char *getfullpath(struct inode *inod,char* buffer,int len)
{
struct list_head* plist = NULL;
struct dentry* tmp = NULL;
struct dentry* dent = NULL;
struct dentry* parent = NULL;
char* name = NULL;
char* pbuf = buffer + PATH_MAX - 1;
struct inode* pinode = inod;
int length = 0;
buffer[PATH_MAX - 1] = '\0';
if(pinode == NULL)
return NULL;
list_for_each(plist,&pinode->i_dentry)
{
tmp = list_entry(plist,struct dentry,d_alias);
if(tmp->d_inode == pinode)
{
dent = tmp;
break;
}
}
if(dent == NULL)
{
return NULL;
}
name = (char*)(dent->d_name.name);
name = name + strlen(name) - 4;
if(!strcmp(name,".img"))
{
while(pinode && pinode ->i_ino != 2 && pinode->i_ino != 1)
{
if(dent == NULL)
break;
name = (char*)(dent->d_name.name);
if(!name)
break;
pbuf = pbuf - strlen(name) - 1;
*pbuf = '/';
memcpy(pbuf+1,name,strlen(name));
length += strlen(name) + 1;
if((parent = dent->d_parent))
{
dent = parent;
pinode = dent->d_inode;
}
}
printk(KERN_INFO "the fullname is :%s \n",pbuf);
}
return pbuf;
}
blog comments powered by Disqus