Linux内存管理概述
一. Linux内核地址空间划分
Linux操作系统将虚拟地址空间4G中低3G是分给用户进程使用,高1G分给内核使用。虽然(在两个用户进程之间的)上下文切换期间会改变低地址部分,但是高地址空间的内核部分总是保持不变。MMU在进行寻址的时候都是使用的虚拟地址,内核当然也不例外。Linux为了简单,将物理内存0开始的部分内存直接映射到了它的虚拟地址开始的地方,也就是0xc0000000,这样做是很方便的,在内核中使用0xc0000001就相当于物理访问物理单元1。但是,这样问题就来了,内核只能直接寻址1G的虚拟地址空间,即使是全部映射完,也只能访问1G物理内存。所以如果一个系统有超过1G的物理内存,在某一时刻,必然有一部分内核是无法直接访问到的。另外,内核除了访问内存外,还需要访问很多IO设备。在现在的计算机体系结构下,这些IO设备的资源(比如寄存器,片上内存等)一般都是通过MMIO的方式映射到物理内存地址空间来访问的,就是说内核的1G地址空间除了映射内存,还要考虑到映射这些IO资源,换句话说,内核还需要预留出一部分虚拟地址空间用来映射这些IO设备。考虑到这些特殊用途,Linux内核只允许直接映射896M的物理内存,而预留了最高端的128M虚拟地址空间另作他用。所以当系统有大于896M内存时,超过896M的内存时,内核就无法直接访问到了,这部分内存就是所谓的高端内存(high memory)。那内核就永远无法访问到超过896M的内存了?当然不适合,内核已经预留了128M虚拟地址,我们可以用这个地址来动态的映射到高端内存,从而来访问高端内存。所以预留的128M除了映射IO设备外,还有一个重要的功能是提供了一种动态访问高端内存的一种手段。当然,在系统物理内存<896M,比如只有512M的时候,就没有高端内存了,因为512M的物理内存都已经被内核直接映射。事实上,在物理内存<896M时,从3G+max_phy ~ 4G的空间都作为上述的预留的内核地址空间。ULK上来第二章就直接出来896M内核页表很是让人迷惑,只有搞清楚了高端内存的概念才能完全理解。需要注意的是,只有内核自身使用高端内存页,对用户空间进程来说,高端页和普通内存页完全没有区别,用户空间进程总是通过页表访问内存,而不是直接访问。下图展示的是内核地址的空间划分。
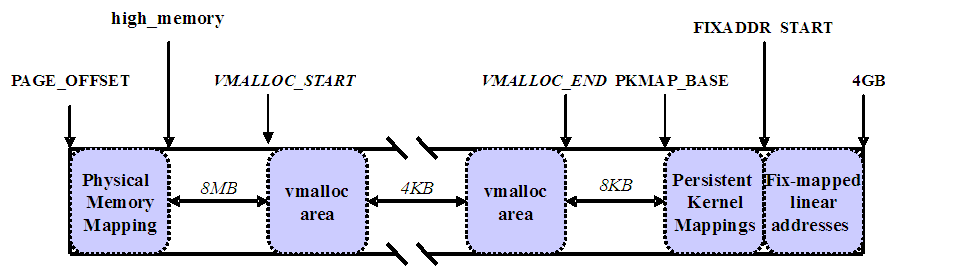
PAGE_OFFSET即是0xc0000000,前面物理内存896M是直接映射到内核地址空间,之后的就是高端内存了,高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。 对 于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行,也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射,这个我们第三节再讲。
二. 页框与内存区简介
页框是Linux内存管理的最小的单位,就是一个4KB的内存区。页框的信息都存放在一个类型为page的页描述符中,所有的页描述符存放在mem_map数组中。注意这是对所有物理内存而言的。整个内存划分为结点(node),每个结点关联到系统中的一个处理器,在内核中表示为pg_data_t的实例。各个结点又划分为内存域(zone),这是内存的进一步细分。大致结构如下:
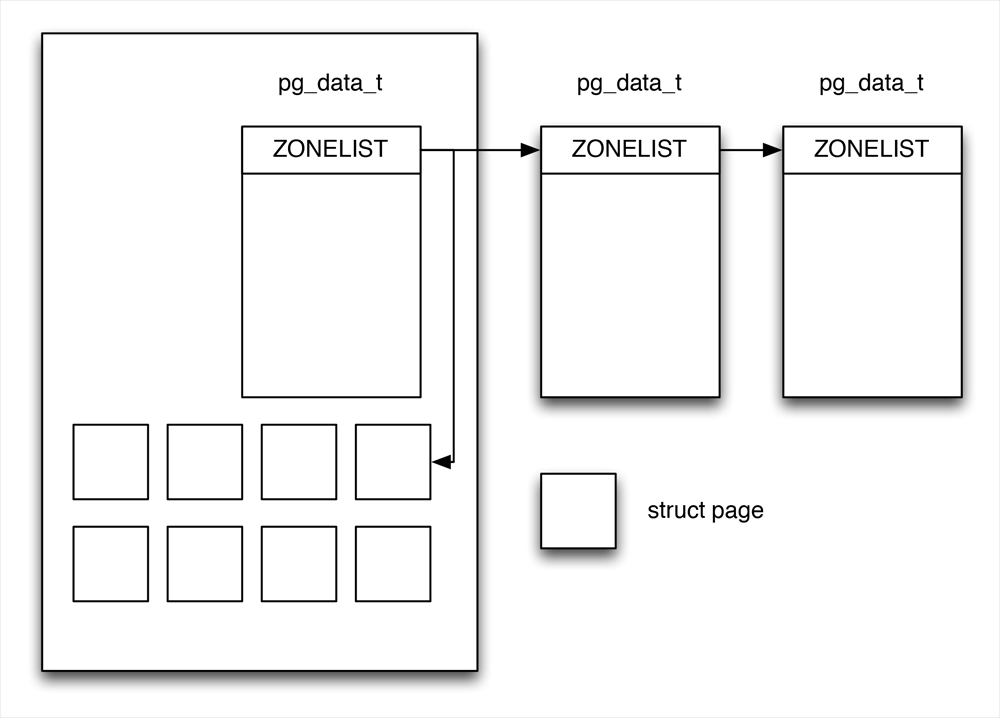
Linux把每个内存结点的物理内存划分为3个管理区,ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM。其范围分别为:
| 字段名 | 说明 |
|---|---|
| ZONE_DMA | 低于16MB的内存页框 |
| ZONE_NORMAL | 高于16MB但地狱896MB的内存页框 |
| ZONE_HIGHMEM | 高于896MB的内存页框 |
x86下的Linux使用一致访问内存(UMA)模型,因此Linux中只有一个单独的节点,包含了系统中所有的物理内存。
三. 高端内存页框的映射
为了使内核访问到高于896M的物理内存,必须将高端内存的页框映射到内核地址空间,Linux使用永久内核映射、临时内核映射以及非连续内存分配。
永久内核映射
永久内核映射允许内核建立高端页框到内核地址空间的长期映射,它们使用主内核页表中一个专门的页表,其地址存放在pkmap_page_table变量中。页表中的表项数由LAST_PKMAP宏产生。页表包含512或1024项,这取决于PAE机制是否被激活。因此,内核最多一次性访问2M或4M的高端内存。页表映射的线性地址从PKMAP_BASE开始,pkmap_count数组包含LAST_PKMAP个计数器,pkmap_page_table页表中的每一个项都有一个。计数器可能为0、1或大于1。
-
如果计数器为0,则说明对应的页表项没有映射任何高端内存,所以是可用的。
-
如果计数器为1,则说明对应的页表项没有映射任何高端内存,但是不能被使用,因为自从它最后一次使用以来,其TLB表项还未被刷新。
-
如果计数器大于1,则说明映射一个高端内存页框,这意味着正好有n-1个内核成分在使用这个页框。
为了记录高端内存页框与永久内核映射包含的线性地址之间的联系,内核使用page_address_htable做散列表,它使用page_address_map数据结构用于为高端内存中的每一个页框进行映射。
struct page_address_map {
struct page *page;
void *virtual;
struct list_head list;
};
page_address()函数返回页框对应的线性地址,如果页框在高端内存中并且没有被映射,则返回NULL。如果页框不在高端内存中,就通过lowmem_page_address返回线性地址。如果在高端内存中,则通过函数page_slot在page_address_htable中查找,如果在散列表中查找到,就返回线性地址。
kmap()用来建立内存区映射,代码如下:
void *kmap(struct page *page){
might_sleep();
if (!PageHighMem(page))
return page_address(page);
return kmap_high(page);
};
本质上如果是高端内存区域,则使用kmap_high()函数用来建立高端内存区的永久内核映射,代码如下:
void *kmap_high(struct page *page)
{
unsigned long vaddr;
/*
* For highmem pages, we can't trust "virtual" until
* after we have the lock.
*/
lock_kmap();
vaddr = (unsigned long)page_address(page);
if (!vaddr)
vaddr = map_new_virtual(page);
pkmap_count[PKMAP_NR(vaddr)]++;
BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);
unlock_kmap();
return (void*) vaddr;
};
临时内存映射
说到临时内存映射就要说到固定映射的线性地址,就是第一张图的最后一部分。固定映射的线性地址(fix-mapped linear address)基本上是一种类似于0xffffc000这样的常量线性地址,其对应的物理地址不必等于线性地址减去0xc0000000,而是可以以任意方式建立。因此,每个固定映射的线性地址都映射一个物理内存的页框。
高端内存的任意一页框都可以通过一个“窗口”(为此而保留的一个页表项)映射到内核地址空间。每个CPU都有它自己包含的13个窗口集合,它们用enum km_type数据结构表示。
enum km_type {
KMAP_D(0) KM_BOUNCE_READ,
KMAP_D(1) KM_SKB_SUNRPC_DATA,
KMAP_D(2) KM_SKB_DATA_SOFTIRQ,
KMAP_D(3) KM_USER0,
KMAP_D(4) KM_USER1,
KMAP_D(5) KM_BIO_SRC_IRQ,
KMAP_D(6) KM_BIO_DST_IRQ,
KMAP_D(7) KM_PTE0,
KMAP_D(8) KM_PTE1,
KMAP_D(9) KM_IRQ0,
KMAP_D(10) KM_IRQ1,
KMAP_D(11) KM_SOFTIRQ0,
KMAP_D(12) KM_SOFTIRQ1,
KMAP_D(13) KM_SYNC_ICACHE,
KMAP_D(14) KM_SYNC_DCACHE,
KMAP_D(15) KM_UML_USERCOPY,
KMAP_D(16) KM_IRQ_PTE,
KMAP_D(17) KM_NMI,
KMAP_D(18) KM_NMI_PTE,
KMAP_D(19) KM_TYPE_NR
};
km_type中的每个符号(除了最后一个)都是固定映射的线性地址的一个下标。为了建立临时内核映射,内核调用kmap_atomic()函数。在后来的内核代码中,kmap_atomic()函数只是使用了kmap_atomic_prot。
void *kmap_atomic_prot(struct page *page, enum km_type type)
{
unsigned int idx;
unsigned long vaddr;
void *kmap;
pagefault_disable();
if (!PageHighMem(page))
return page_address(page);
debug_kmap_atomic(type);
kmap = kmap_high_get(page);
if (kmap)
return kmap;
idx = type + KM_TYPE_NR * smp_processor_id();
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
#ifdef CONFIG_DEBUG_HIGHMEM
BUG_ON(!pte_none(*(TOP_PTE(vaddr))));
#endif
set_pte_ext(TOP_PTE(vaddr), mk_pte(page, kmap_prot), 0);
local_flush_tlb_kernel_page(vaddr);
return (void *)vaddr;
}
非连续内存分配
如果内核能够找到连续的页,那是最好的,这样分配和释放都会比较简单,但是真实的系统里情况往往不是那么简单。在分配一大块内存时,可能竭尽全力也无法找到连续的内存块,在用户空间中这不是问题,因为普通进程设计为使用处理器的分页机制,当然这也会降低速度并占用TLB。
为非连续内存区保留的线性地址空间从VMALLOC_START到VMALLOC_END。
每个vmalloc分配的子区域都是自包含的,与其他vmalloc子区域通过一个内存页分隔,类似于直接映射和vmalloc区域之间的边界,不同vmalloc子区域之间的分隔也是为防止不正确的内存访问操作。这种情况只会因为内核故障出现,应该通过系统错误信息报告,而不是允许内核其他部分的数据被暗中修改,因为分隔是在虚拟地址空间中建立的,不会浪费物理内存页。
vmalloc是一个接口函数,内核代码使用它来分配在虚拟内存中连续但在物理内存中不一定连续的内存。 这个函数只需要一个参数,用于指定所需内存区的长度,不过其长度单位不是页而是字节,这在用户空间程序的设计中是很普遍的。
使用vmalloc的最著名的实例是内核对模块的实现,因为模块可以在任何时候加载,如果模块数据比较多,那么无法保证有足够的连续内存可用,特别是在系统已经运行了比较长时间的情况下。如果能够用小块内存拼接出足够的内存,那么就可以使用vmalloc。
因为用于vmalloc的内存页总是必须映射在内核地址空间中,因此使用ZONE_HIGHMEM内存域的页要优于其他内存域,这使得内核可以节省更宝贵的较地段内存域又不会带来额外的坏处。所以,vmalloc是内核出于自身的目的使用高端内存页的少数情况之一。
内核在管理虚拟内存中的vmalloc区域时,必须跟踪哪些子区域被使用,哪些是空闲的,所以定义了一个vm_struct的数据结构,并将所有使用的部分保存在一个链表中。
struct vm_struct {
struct vm_struct *next;
void *addr;
unsigned long size;
unsigned long flags;
struct page **pages;
unsigned int nr_pages;
unsigned long phys_addr;
void *caller;
}; 内核通过vmalloc()来申请非连续的物理内存,若申请成功,该函数返回连续内存区的起始地址,否则,返回NULL。vmalloc()和kmalloc()申请的内存有所不同,kmalloc()所申请内存的线性地址与物理地址都是连续的,而vmalloc()所申请的内存线性地址连续而物理地址则是离散的,两个地址之间通过内核页表进行映射。
vmalloc()的工作方式理解起来很简单: 1.寻找一个新的连续线性地址空间; 2.依次分配一组非连续的页框; 3.为线性地址空间和非连续页框建立映射关系,即修改内核页表;
blog comments powered by Disqus