cgroups internals
Concepts
Control groups provide a mechanism to group process/tasks to control there behaviour(limit resource for example). Some of the Concepts:
cgroup: a set of tasks with a set of parameters for one or more subsystems.
subsystem: a recource controller that schedules a resource or applies per-cgroup limits.
hierarchy: a set of cgroups arranged in a tree. Every task in the system is in exactly one of the cgroups in the hierarchy and a set of subsystems.
Cgroups is the fundamental mechanism used by docker. This post will dig into how cgroup is implemented. This post uses kernel 4.4.
Basic structure
task_struct has a ‘cgroups’ field which points a ‘struct css_set’, this contains the process’s cgroups info.
struct css_set {
/* Reference count */
atomic_t refcount;
/*
* List running through all cgroup groups in the same hash
* slot. Protected by css_set_lock
*/
struct hlist_node hlist;
/*
* Lists running through all tasks using this cgroup group.
* mg_tasks lists tasks which belong to this cset but are in the
* process of being migrated out or in. Protected by
* css_set_rwsem, but, during migration, once tasks are moved to
* mg_tasks, it can be read safely while holding cgroup_mutex.
*/
struct list_head tasks;
struct list_head mg_tasks;
/*
* List of cgrp_cset_links pointing at cgroups referenced from this
* css_set. Protected by css_set_lock.
*/
struct list_head cgrp_links;
/* the default cgroup associated with this css_set */
struct cgroup *dfl_cgrp;
/*
* Set of subsystem states, one for each subsystem. This array is
* immutable after creation apart from the init_css_set during
* subsystem registration (at boot time).
*/
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];
/*
* List of csets participating in the on-going migration either as
* source or destination. Protected by cgroup_mutex.
*/
struct list_head mg_preload_node;
struct list_head mg_node;
/*
* If this cset is acting as the source of migration the following
* two fields are set. mg_src_cgrp is the source cgroup of the
* on-going migration and mg_dst_cset is the destination cset the
* target tasks on this cset should be migrated to. Protected by
* cgroup_mutex.
*/
struct cgroup *mg_src_cgrp;
struct css_set *mg_dst_cset;
/*
* On the default hierarhcy, ->subsys[ssid] may point to a css
* attached to an ancestor instead of the cgroup this css_set is
* associated with. The following node is anchored at
* ->subsys[ssid]->cgroup->e_csets[ssid] and provides a way to
* iterate through all css's attached to a given cgroup.
*/
struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];
/* all css_task_iters currently walking this cset */
struct list_head task_iters;
/* dead and being drained, ignore for migration */
bool dead;
/* For RCU-protected deletion */
struct rcu_head rcu_head;
};
The ‘mg_***’ field is used to migrate process from one group to another group. ‘hlist’ is used to link all of the ‘css_set’ that in the same hashtable slots. ‘tasks’ is used to link all of the process using this ‘css_set’. ‘cgrp_links’ is used to link a ‘cgrp_cset_link’ which links ‘css_set’ with ‘cgroup’. ‘subsys’ is an array which points ‘cgroup_subsys_state’. A ‘cgroup_subsys_state’ is a specific control data structure.
‘cgroup_subsys_state’ is defined as following:
struct cgroup_subsys_state {
/* PI: the cgroup that this css is attached to */
struct cgroup *cgroup;
/* PI: the cgroup subsystem that this css is attached to */
struct cgroup_subsys *ss;
/* reference count - access via css_[try]get() and css_put() */
struct percpu_ref refcnt;
/* PI: the parent css */
struct cgroup_subsys_state *parent;
/* siblings list anchored at the parent's ->children */
struct list_head sibling;
struct list_head children;
/*
* PI: Subsys-unique ID. 0 is unused and root is always 1. The
* matching css can be looked up using css_from_id().
*/
int id;
unsigned int flags;
/*
* Monotonically increasing unique serial number which defines a
* uniform order among all csses. It's guaranteed that all
* ->children lists are in the ascending order of ->serial_nr and
* used to allow interrupting and resuming iterations.
*/
u64 serial_nr;
/*
* Incremented by online self and children. Used to guarantee that
* parents are not offlined before their children.
*/
atomic_t online_cnt;
/* percpu_ref killing and RCU release */
struct rcu_head rcu_head;
struct work_struct destroy_work;
};
The ‘struct cgroup’ member represents the ‘cgroup’ that process attaches to. ‘cgroup_subsys’ member points to a specific subsystem.
In fact ‘cgroup_subsys_state’ is embedded in a specific subsystem cgroup. For example, the memory contontroller ‘mem_cgroup’ has following.
struct mem_cgroup {
struct cgroup_subsys_state css;
/* Private memcg ID. Used to ID objects that outlive the cgroup */
struct mem_cgroup_id id;
/* Accounted resources */
struct page_counter memory;
struct page_counter memsw;
struct page_counter kmem;
...
}
The ‘css_set’s subsys member points the ‘mem_cgroup’s ‘css’ field.
Following is the definition of ‘struct cgroup’.
struct cgroup {
/* self css with NULL ->ss, points back to this cgroup */
struct cgroup_subsys_state self;
unsigned long flags; /* "unsigned long" so bitops work */
/*
* idr allocated in-hierarchy ID.
*
* ID 0 is not used, the ID of the root cgroup is always 1, and a
* new cgroup will be assigned with a smallest available ID.
*
* Allocating/Removing ID must be protected by cgroup_mutex.
*/
int id;
/*
* Each non-empty css_set associated with this cgroup contributes
* one to populated_cnt. All children with non-zero popuplated_cnt
* of their own contribute one. The count is zero iff there's no
* task in this cgroup or its subtree.
*/
int populated_cnt;
struct kernfs_node *kn; /* cgroup kernfs entry */
struct cgroup_file procs_file; /* handle for "cgroup.procs" */
struct cgroup_file events_file; /* handle for "cgroup.events" */
/*
* The bitmask of subsystems enabled on the child cgroups.
* ->subtree_control is the one configured through
* "cgroup.subtree_control" while ->child_subsys_mask is the
* effective one which may have more subsystems enabled.
* Controller knobs are made available iff it's enabled in
* ->subtree_control.
*/
unsigned int subtree_control;
unsigned int child_subsys_mask;
/* Private pointers for each registered subsystem */
struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];
struct cgroup_root *root;
/*
* List of cgrp_cset_links pointing at css_sets with tasks in this
* cgroup. Protected by css_set_lock.
*/
struct list_head cset_links;
/*
* On the default hierarchy, a css_set for a cgroup with some
* susbsys disabled will point to css's which are associated with
* the closest ancestor which has the subsys enabled. The
* following lists all css_sets which point to this cgroup's css
* for the given subsystem.
*/
struct list_head e_csets[CGROUP_SUBSYS_COUNT];
/*
* list of pidlists, up to two for each namespace (one for procs, one
* for tasks); created on demand.
*/
struct list_head pidlists;
struct mutex pidlist_mutex;
/* used to wait for offlining of csses */
wait_queue_head_t offline_waitq;
/* used to schedule release agent */
struct work_struct release_agent_work;
};
‘struct cgroup’ represents a concrete control group. ‘kn’ is the cgroup kernfs entry. ‘subsys’ is an array points to ‘cgroup_subsys_state’, these represets the subsystem that this ‘cgroup’ contains. ‘cset_links’ is used to link to ‘cgrp_cset_link’.
A ‘css_set’ can be associated with multiple cgroups. And also a ‘cgroup’ can be associated with multiple css_sets as different tasks my belong to differenct cgroups on different hierarchies. So this M:N relationship is represented by ‘struct cgrp_cset_link’.
struct cgrp_cset_link {
/* the cgroup and css_set this link associates */
struct cgroup *cgrp;
struct css_set *cset;
/* list of cgrp_cset_links anchored at cgrp->cset_links */
struct list_head cset_link;
/* list of cgrp_cset_links anchored at css_set->cgrp_links */
struct list_head cgrp_link;
};
Following figures show the data relations:
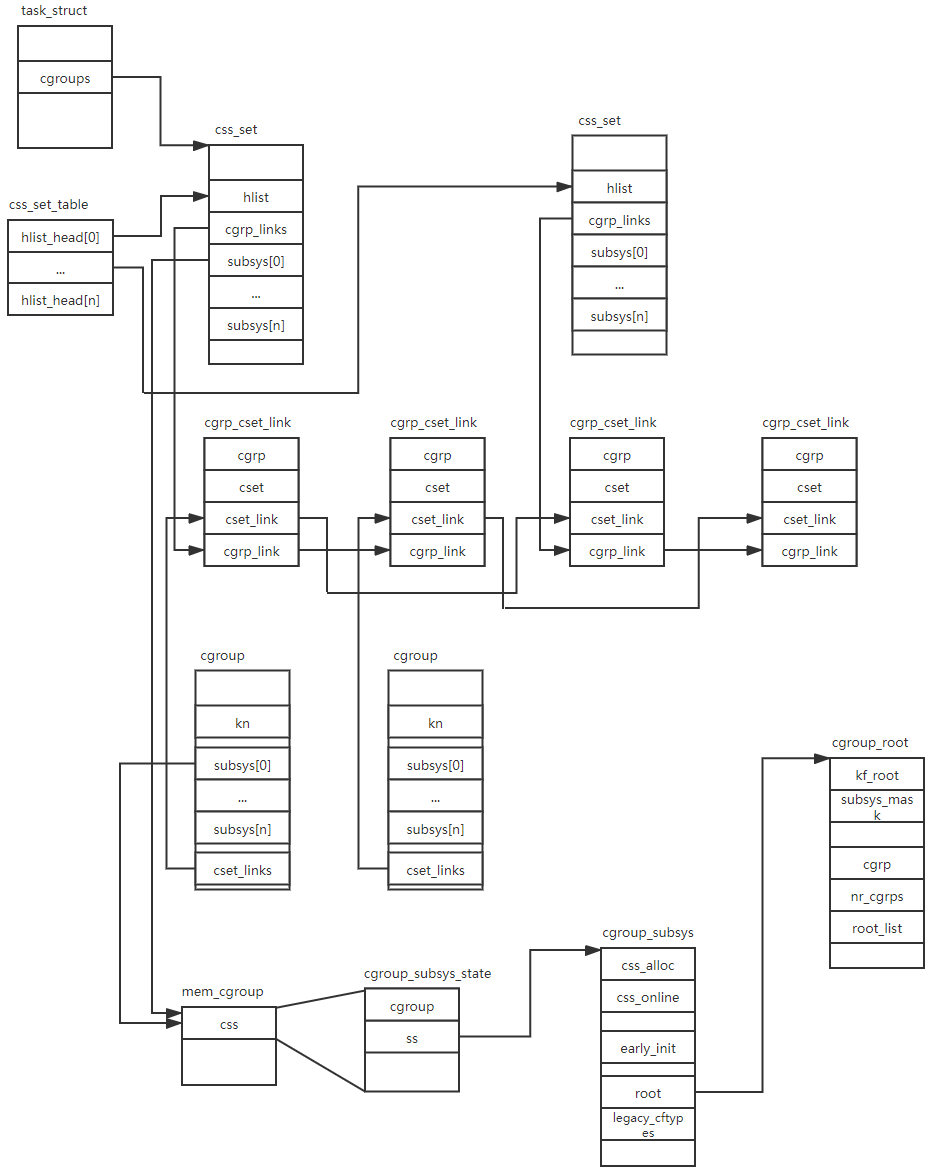
Cgroups initialization
In start_main early state, it calls ‘cgroup_init_early’ to intialize the subsystem that needs early initialization, this is indicated in the ‘struct cgroup_subsys’s early_init member.
int __init cgroup_init_early(void)
{
static struct cgroup_sb_opts __initdata opts;
struct cgroup_subsys *ss;
int i;
init_cgroup_root(&cgrp_dfl_root, &opts);
cgrp_dfl_root.cgrp.self.flags |= CSS_NO_REF;
RCU_INIT_POINTER(init_task.cgroups, &init_css_set);
for_each_subsys(ss, i) {
WARN(!ss->css_alloc || !ss->css_free || ss->name || ss->id,
"invalid cgroup_subsys %d:%s css_alloc=%p css_free=%p name:id=%d:%s\n",
i, cgroup_subsys_name[i], ss->css_alloc, ss->css_free,
ss->id, ss->name);
WARN(strlen(cgroup_subsys_name[i]) > MAX_CGROUP_TYPE_NAMELEN,
"cgroup_subsys_name %s too long\n", cgroup_subsys_name[i]);
ss->id = i;
ss->name = cgroup_subsys_name[i];
if (!ss->legacy_name)
ss->legacy_name = cgroup_subsys_name[i];
if (ss->early_init)
cgroup_init_subsys(ss, true);
}
return 0;
}
In ‘cgroup_init_early’, it first initializes ‘cgrp_dfl_root’. This is the default ‘cgroup_root’. This is revserved for the subsystems that are not used. It has a single cgroup, and all tasks are part of that cgroup. Then it sets the ‘init_css_set’ to ‘init_task.cgroups’. So if we don’t use cgroup all of the process will use this ‘init_css_set’ as its task_struct.cgroups. Then it iterates all of the subsystems and calls ‘cgroup_init_subsys’ to initialize them.
static void __init cgroup_init_subsys(struct cgroup_subsys *ss, bool early)
{
struct cgroup_subsys_state *css;
printk(KERN_INFO "Initializing cgroup subsys %s\n", ss->name);
mutex_lock(&cgroup_mutex);
idr_init(&ss->css_idr);
INIT_LIST_HEAD(&ss->cfts);
/* Create the root cgroup state for this subsystem */
ss->root = &cgrp_dfl_root;
css = ss->css_alloc(cgroup_css(&cgrp_dfl_root.cgrp, ss));
/* We don't handle early failures gracefully */
BUG_ON(IS_ERR(css));
init_and_link_css(css, ss, &cgrp_dfl_root.cgrp);
...
init_css_set.subsys[ss->id] = css;
...
BUG_ON(online_css(css));
mutex_unlock(&cgroup_mutex);
}
First ‘cgroup_init_subsys’ sets ‘cgroup_subsys’s root to the default cgroup_root. Then calls the subsystem’s css_alloc callback to allocate a ‘struct cgroup_subsys_state’. The argument here to css_alloc callback is NULL. The subsystem do some special work for this default cgroup_root. For example, the mem cgroup will set the max value of memory limits.
static struct cgroup_subsys_state * __ref
mem_cgroup_css_alloc(struct cgroup_subsys_state *parent_css)
{
struct mem_cgroup *memcg;
long error = -ENOMEM;
int node;
memcg = mem_cgroup_alloc();
if (!memcg)
return ERR_PTR(error);
for_each_node(node)
if (alloc_mem_cgroup_per_zone_info(memcg, node))
goto free_out;
/* root ? */
if (parent_css == NULL) {
root_mem_cgroup = memcg;
mem_cgroup_root_css = &memcg->css;
page_counter_init(&memcg->memory, NULL);
memcg->high = PAGE_COUNTER_MAX;
memcg->soft_limit = PAGE_COUNTER_MAX;
page_counter_init(&memcg->memsw, NULL);
page_counter_init(&memcg->kmem, NULL);
}
...
}
After get the ‘cgroup_subsys_state’ in ‘cgroup_init_subsys’, the function then calls ‘init_and_link_css’ to initialize the ‘cgroup_subsys_state’ and online_css to call subsystem’s css_online callback.
In the second stage of initialization ‘cgroup_init’ it does more work.
int __init cgroup_init(void)
{
struct cgroup_subsys *ss;
unsigned long key;
int ssid;
BUG_ON(percpu_init_rwsem(&cgroup_threadgroup_rwsem));
BUG_ON(cgroup_init_cftypes(NULL, cgroup_dfl_base_files));
BUG_ON(cgroup_init_cftypes(NULL, cgroup_legacy_base_files));
mutex_lock(&cgroup_mutex);
/* Add init_css_set to the hash table */
key = css_set_hash(init_css_set.subsys);
hash_add(css_set_table, &init_css_set.hlist, key);
BUG_ON(cgroup_setup_root(&cgrp_dfl_root, 0));
mutex_unlock(&cgroup_mutex);
for_each_subsys(ss, ssid) {
if (ss->early_init) {
struct cgroup_subsys_state *css =
init_css_set.subsys[ss->id];
css->id = cgroup_idr_alloc(&ss->css_idr, css, 1, 2,
GFP_KERNEL);
BUG_ON(css->id < 0);
} else {
cgroup_init_subsys(ss, false);
}
list_add_tail(&init_css_set.e_cset_node[ssid],
&cgrp_dfl_root.cgrp.e_csets[ssid]);
...
cgrp_dfl_root.subsys_mask |= 1 << ss->id;
if (!ss->dfl_cftypes)
cgrp_dfl_root_inhibit_ss_mask |= 1 << ss->id;
if (ss->dfl_cftypes == ss->legacy_cftypes) {
WARN_ON(cgroup_add_cftypes(ss, ss->dfl_cftypes));
} else {
WARN_ON(cgroup_add_dfl_cftypes(ss, ss->dfl_cftypes));
WARN_ON(cgroup_add_legacy_cftypes(ss, ss->legacy_cftypes));
}
if (ss->bind)
ss->bind(init_css_set.subsys[ssid]);
}
WARN_ON(sysfs_create_mount_point(fs_kobj, "cgroup"));
WARN_ON(register_filesystem(&cgroup_fs_type));
WARN_ON(!proc_create("cgroups", 0, NULL, &proc_cgroupstats_operations));
return 0;
}
First it calls ‘cgroup_init_cftypes’ to initiaze two ‘struct cftype’ ‘cgroup_dfl_base_files’ and ‘cgroup_legacy_base_files’. A ‘cftype’ contains the cgroup control files and its handler. ‘cgroup_dfl_base_files’ is for default hierarchy and ‘cgroup_legacy_base_files’ is for general hierarchy. Unfortunately, we can’t see cgroup_dfl_base_files files as the linux distros will use cgroup to management, so after the system boot, we can see the cgroup_legacy_base_files files.
Then ‘cgroup_init’ caculate the key of ‘init_css_set.subsys’ and insert it to css_set_table. css_set_table contains all of the ‘css_set’.
‘cgroup_setup_root’ is used to setup a ‘cgroup_root’. This function is also called in cgroup_mount, the ‘ss_mask’ argument is the mask of subsystem.
‘allocate_cgrp_cset_links’ allocates ‘css_set_count’ of ‘cgrp_cset_link’. Later it uses these links to link every currently ‘css_set’ to this new ‘cgroup_root’.
hash_for_each(css_set_table, i, cset, hlist) {
link_css_set(&tmp_links, cset, root_cgrp);
if (css_set_populated(cset))
cgroup_update_populated(root_cgrp, true);
}
‘kernfs_create_root’ create a new kernfs hierarchy. This is the root directory of this cgroup. ‘css_populate_dir’ creates the files in the root kernfs directory.
‘rebind_subsystems’ binds this ‘cgroup_root’ to the ‘cgroup_subsys’. The most import code is following. Set the ‘ss->root’ to dst_root.
for_each_subsys_which(ss, ssid, &ss_mask) {
struct cgroup_root *src_root = ss->root;
struct cgroup *scgrp = &src_root->cgrp;
struct cgroup_subsys_state *css = cgroup_css(scgrp, ss);
struct css_set *cset;
WARN_ON(!css || cgroup_css(dcgrp, ss));
css_clear_dir(css, NULL);
RCU_INIT_POINTER(scgrp->subsys[ssid], NULL);
rcu_assign_pointer(dcgrp->subsys[ssid], css);
ss->root = dst_root;
css->cgroup = dcgrp;
...
}
After rebind the cgroup_subsys’s root, the ‘cgroup_setup_root’ nearly finishes his job.
Let’s return to ‘cgroup_init’. It calls ‘cgroup_init_subsys’ to initialize the specific subystem. Then set the bit in ‘cgrp_dfl_root.subsys_mask’.
Following code adds the specific subsystem’s cftype to the subsystem while linking to the the ‘cgroup_subsys’s cfts list head.
if (ss->dfl_cftypes == ss->legacy_cftypes) {
WARN_ON(cgroup_add_cftypes(ss, ss->dfl_cftypes));
} else {
WARN_ON(cgroup_add_dfl_cftypes(ss, ss->dfl_cftypes));
WARN_ON(cgroup_add_legacy_cftypes(ss, ss->legacy_cftypes));
}
Finally, ‘cgroup_init’ creates the mount in ‘/sys/fs/cgroup’ by calling ‘sysfs_create_mount_point’, registers the ‘cgroup_fs_type’ so that the userspace can mount cgroup filesystem, creates the /proc/cgroups to show cgroup status.
Cgroups VFS
At the end of ‘cgroup_init’, a new filesystem ‘cgroup_fs_type’ is registered. This is the cgroup fs.
static struct file_system_type cgroup_fs_type = {
.name = "cgroup",
.mount = cgroup_mount,
.kill_sb = cgroup_kill_sb,
};
Every mount will create a new hierarchy, one or more subsystem can be attached to this hierarchy. From the code perspective, ‘cgroup_mount’ a cgroup_root for one or more cgroup_subsys.
‘parse_cgroupfs_options’ is used to parse the options from mount system call and install it in a ‘cgroup_sb_opts’ opts. opts.subsys_mask stores the subsystem which want to attached to this new hierarchy.
Next the ‘cgroup_mount’ drain the unmounted subsystems.
for_each_subsys(ss, i) {
if (!(opts.subsys_mask & (1 << i)) ||
ss->root == &cgrp_dfl_root)
continue;
if (!percpu_ref_tryget_live(&ss->root->cgrp.self.refcnt)) {
mutex_unlock(&cgroup_mutex);
msleep(10);
ret = restart_syscall();
goto out_free;
}
cgroup_put(&ss->root->cgrp);
}
Next ‘for_each_root(root)’ is used to check if the susbsystem has been mounted. If the ‘root’ is the ‘cgrp_dfl_root’, it means this subsystem is not mounted, just contine the loop. The subsystem mounted not once must match each other.
if ((opts.subsys_mask || opts.none) &&
(opts.subsys_mask != root->subsys_mask)) {
if (!name_match)
continue;
ret = -EBUSY;
goto out_unlock;
}
This means, for example if we first mount cpu,cpuset in /sys/fs/cgroup/cpu,cpuset directory, then we can’t separately mount the cpu or cpuset subsystem. Instead we must also mount cpu,cpuset in a directory. If we have passed the check, then ‘kernfs_pin_sb’ is called to pin the already mounted superblock and just go to out_unlock. Then just mount the already mounted system to the new directory.
If instead, the susbsystem hasn’t been mounted, we need to allocate and initialize a new ‘cgroup_root’.
root = kzalloc(sizeof(*root), GFP_KERNEL);
if (!root) {
ret = -ENOMEM;
goto out_unlock;
}
init_cgroup_root(root, &opts);
ret = cgroup_setup_root(root, opts.subsys_mask);
if (ret)
cgroup_free_root(root);
out_unlock:
mutex_unlock(&cgroup_mutex);
out_free:
kfree(opts.release_agent);
kfree(opts.name);
if (ret)
return ERR_PTR(ret);
And finally mount the new kernfs to the directory.
dentry = kernfs_mount(fs_type, flags, root->kf_root,
CGROUP_SUPER_MAGIC, &new_sb);
if (IS_ERR(dentry) || !new_sb)
cgroup_put(&root->cgrp);
Create a new cgroup
When we create a directory in a subsystem’s fs root directory we create a new group. The kernfs’s syscall ops is set to ‘cgroup_kf_syscall_ops’ in ‘cgroup_setup_root’. And the mkdir handler is ‘cgroup_mkdir’.
static struct kernfs_syscall_ops cgroup_kf_syscall_ops = {
.remount_fs = cgroup_remount,
.show_options = cgroup_show_options,
.mkdir = cgroup_mkdir,
.rmdir = cgroup_rmdir,
.rename = cgroup_rename,
};
Allocate a new ‘cgroup_root’ and initialize the new ‘cgroup_root’
cgrp = kzalloc(sizeof(*cgrp), GFP_KERNEL);
if (!cgrp) {
ret = -ENOMEM;
goto out_unlock;
}
ret = percpu_ref_init(&cgrp->self.refcnt, css_release, 0, GFP_KERNEL);
if (ret)
goto out_free_cgrp;
/*
* Temporarily set the pointer to NULL, so idr_find() won't return
* a half-baked cgroup.
*/
cgrp->id = cgroup_idr_alloc(&root->cgroup_idr, NULL, 2, 0, GFP_KERNEL);
if (cgrp->id < 0) {
ret = -ENOMEM;
goto out_cancel_ref;
}
init_cgroup_housekeeping(cgrp);
cgrp->self.parent = &parent->self;
cgrp->root = root;
Create the directory and create the files.
kn = kernfs_create_dir(parent->kn, name, mode, cgrp);
if (IS_ERR(kn)) {
ret = PTR_ERR(kn);
goto out_free_id;
}
cgrp->kn = kn;
/*
* This extra ref will be put in cgroup_free_fn() and guarantees
* that @cgrp->kn is always accessible.
*/
kernfs_get(kn);
cgrp->self.serial_nr = css_serial_nr_next++;
/* allocation complete, commit to creation */
list_add_tail_rcu(&cgrp->self.sibling, &cgroup_parent(cgrp)->self.children);
atomic_inc(&root->nr_cgrps);
cgroup_get(parent);
/*
* @cgrp is now fully operational. If something fails after this
* point, it'll be released via the normal destruction path.
*/
cgroup_idr_replace(&root->cgroup_idr, cgrp, cgrp->id);
ret = cgroup_kn_set_ugid(kn);
if (ret)
goto out_destroy;
ret = css_populate_dir(&cgrp->self, NULL);
if (ret)
goto out_destroy;
Create and online a ‘cgroup_subsys_state’.
for_each_subsys(ss, ssid) {
if (parent->child_subsys_mask & (1 << ssid)) {
ret = create_css(cgrp, ss,
parent->subtree_control & (1 << ssid));
if (ret)
goto out_destroy;
}
}
Attach process to a cgroup
The process can be moved to a new ‘cgroup’ by writing the pid of process to cgroup’s cgroup.procs or tasks file. Let’s use the first as an example.
static struct cftype cgroup_legacy_base_files[] = {
{
.name = "cgroup.procs",
.seq_start = cgroup_pidlist_start,
.seq_next = cgroup_pidlist_next,
.seq_stop = cgroup_pidlist_stop,
.seq_show = cgroup_pidlist_show,
.private = CGROUP_FILE_PROCS,
.write = cgroup_procs_write,
},
The actually function is ‘__cgroup_procs_write’. It calls ‘cgroup_attach_task’ to attach a task to a cgroup.
static int cgroup_attach_task(struct cgroup *dst_cgrp,
struct task_struct *leader, bool threadgroup)
{
LIST_HEAD(preloaded_csets);
struct task_struct *task;
int ret;
/* look up all src csets */
spin_lock_bh(&css_set_lock);
rcu_read_lock();
task = leader;
do {
cgroup_migrate_add_src(task_css_set(task), dst_cgrp,
&preloaded_csets);
if (!threadgroup)
break;
} while_each_thread(leader, task);
rcu_read_unlock();
spin_unlock_bh(&css_set_lock);
/* prepare dst csets and commit */
ret = cgroup_migrate_prepare_dst(dst_cgrp, &preloaded_csets);
if (!ret)
ret = cgroup_migrate(leader, threadgroup, dst_cgrp);
cgroup_migrate_finish(&preloaded_csets);
return ret;
}
I won’t go to the detail of these function calls. The point is ‘cgroup_migrate’->’cgroup_taskset_migrate’:
list_for_each_entry(cset, &tset->src_csets, mg_node) {
list_for_each_entry_safe(task, tmp_task, &cset->mg_tasks, cg_list) {
struct css_set *from_cset = task_css_set(task);
struct css_set *to_cset = cset->mg_dst_cset;
get_css_set(to_cset);
css_set_move_task(task, from_cset, to_cset, true);
put_css_set_locked(from_cset);
}
}
How cgroup make an effect to process
From above we know the cgroup internal implementation. Let’s see how it controls process.
The control is done by the subsystem. For example, when the kernel allocates or frees memory for a process, it will call ‘mem_cgroup_try_charge’ to let the memory cgroup invole to make sure the process will never exceed the limits.
blog comments powered by Disqus