vLLM中的Paged Attention分析
基本概念
上一篇文章中介绍了KV cache的概念以及作用,由于KV cache在推理中的作用性能提升很大,所以现在各种推理框架都会支持KV cache。本文介绍vLLM中的核心原理Paged Attention的实现,本文不会详细介绍vLLM的基本原理以及vLLM整体的源码架构分析(将来有机会争取写一下),所以假设读者需要熟悉大模型的基本推理过程以及vLLM基本代码架构,图解大模型计算加速系列之:vLLM核心技术PagedAttention原理文章是不错的介绍vLLM Paged Attention的原理性文章。
推理框架在进行推理过程中一个重要的环节是计算各个token之间的自注意力,KV cache保存了之前token的KV值,在计算当前token时,会引用KV cache中值。vLLM Paged Attention的核心机制就是在这里管理KV cache的时候采用了类似操作系统虚拟内存的概念,通过动态的分配KV cache的block,从而提高显存的利用效率。本文就是对这一机制进行分析,简单来讲,本文会从代码层面详细分析下面这个图的实现。
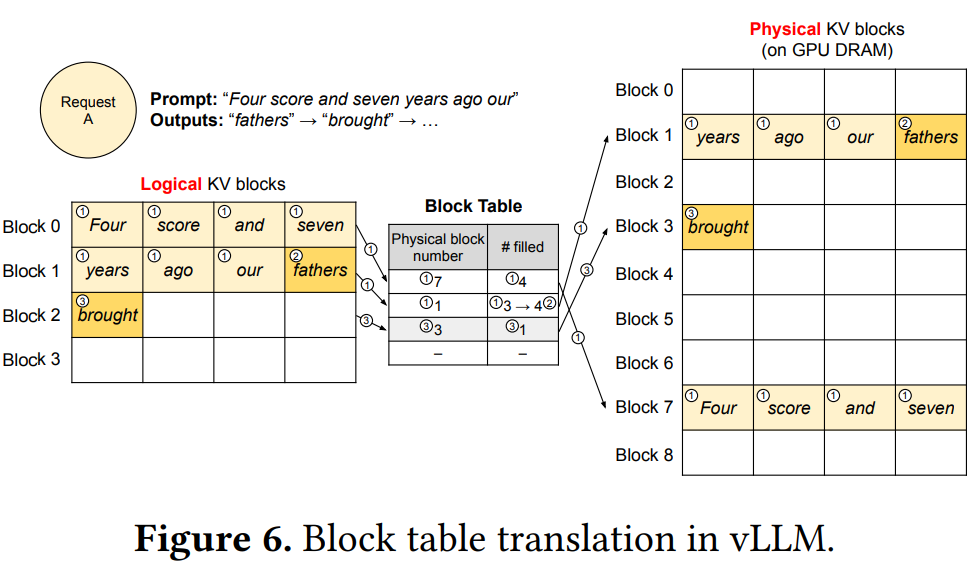
具体来讲,本文包括如下内容
- 物理block的分配
- 虚拟机block的管理
- KV cache的使用
本文基于vLLM的CPU实现分析。 一个Block类似操作系统的一个page,一个page通常管理固定大小的byte(一般是4096),一个Block也是管理固定大小的token的KV,比如上面的图一个Block管理4个token的KV,实际中一般会更大点。
物理block的分配
与操作系统的page在系统初始化阶段分配完成,每个page分配一个pfn类似,物理block在vLLM引擎初始化阶段会分配完成,每个物理block的id就是其在数组中的序号。vLLM中的这个图左边可以看做是虚拟Block的管理,右边可以看成是物理Block的管理(基本就是分配空间、swap in/out等),右边漏了一个executor,也可能是作者觉得不太重要。
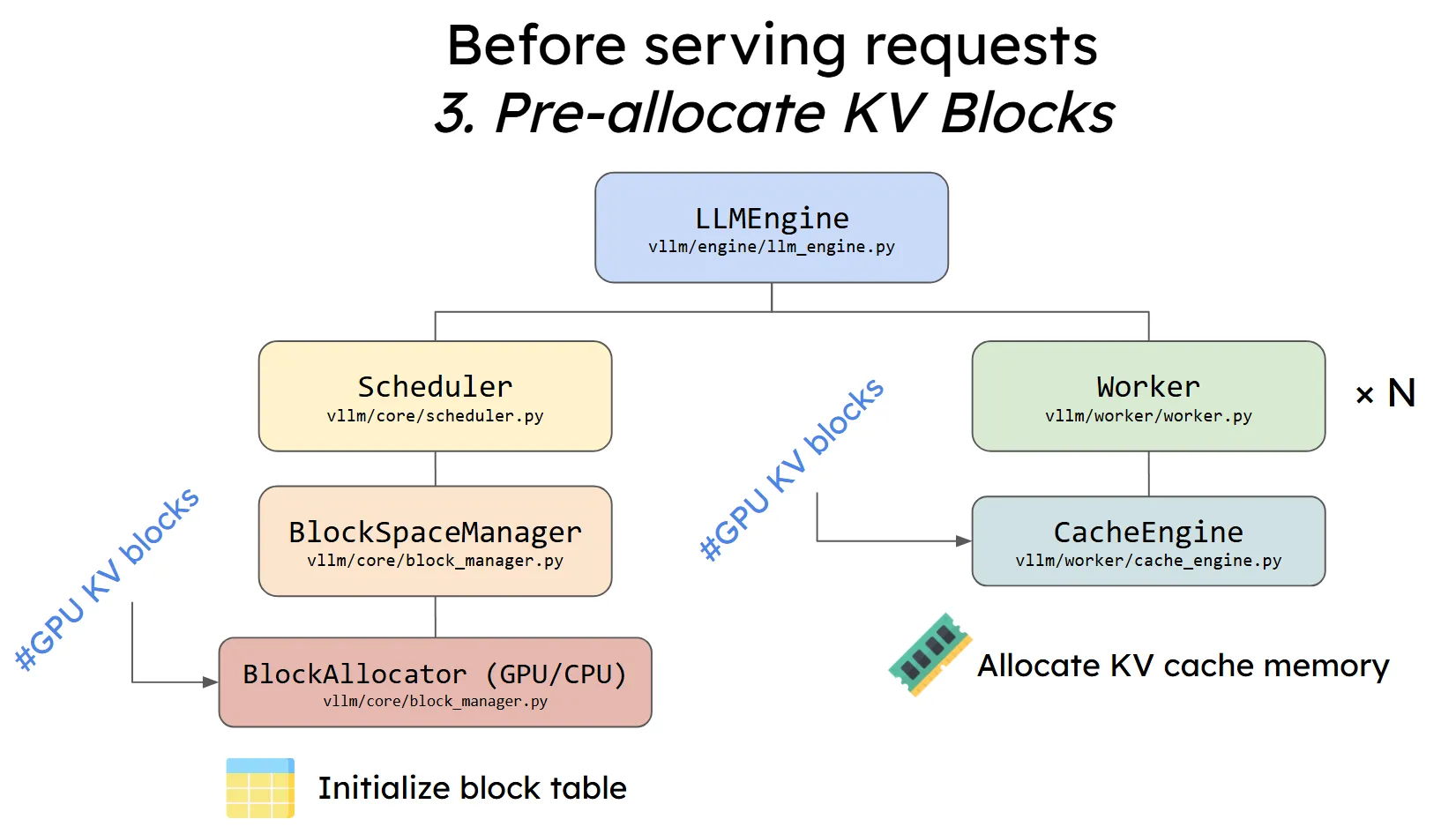
KV cache初始化流程如下:
LLMEngine.__init__
-->self._initialize_kv_caches(LLMEngine._initialize_kv_caches)
-->self.model_executor.determine_num_available_blocks
-->self.model_executor.initialize_cache
-->self.collective_rpc("initialize_cache")
-->CPUWorker.initialize_cache
-->self._init_cache_engine(CPUWorker._init_cache_engine)
-->CPUCacheEngine.__init__
-->get_attn_backend
-->self._allocate_kv_cache(CPUCacheEngine._allocate_kv_cache)
-->self.attn_backend.get_kv_cache_shape
-->kv_cache.append
-->bind_kv_cache
-->layer_cache.fill_(0)
self.model_executor.determine_num_available_blocks会决定总的物理Block个数(相当于操作系统里面总的page页数),包括num_gpu_blocks和num_cpu_blocks。
物理Block也就是KV cache的空间创建是在CPUWorker的_init_cache_engine函数中完成的。
def _init_cache_engine(self) -> None:
self.cache_engine = [
CPUCacheEngine(self.cache_config, self.model_config,
self.parallel_config, self.device_config)
for _ in range(self.parallel_config.pipeline_parallel_size)
]
self.cpu_cache = [
self.cache_engine[ve].cpu_cache
for ve in range(self.parallel_config.pipeline_parallel_size)
]
bind_kv_cache(self.compilation_config.static_forward_context,
self.cpu_cache)
self.model_runner.block_size = self.cache_engine[0].block_size
assert all(
self.cpu_cache[ve] is not None
for ve in range(self.parallel_config.pipeline_parallel_size))
# Populate the cache to warmup the memory
for ve in range(self.parallel_config.pipeline_parallel_size):
for layer_cache in self.cpu_cache[ve]:
layer_cache.fill_(0)
CPUCacheEngine是用来管理物理Block的核心,下面是初始化的第一部分代码,工作为初始化相关变量。head_size是注意力机制中头的维度大小和头数num_heads,每个layer都有对应的KV cache,所以这里要获取num_layers。block_size是每个block要保存的token数目的KV cache,num_cpu_blocks是之前获取的总共的CPU block。
class CPUCacheEngine:
"""Manages the KV cache for CPU backend.
This class is responsible for initializing and managing CPU KV
caches. It also provides methods for performing KV cache operations, such
as copying.
"""
def __init__(self, cache_config: CacheConfig, model_config: ModelConfig,
parallel_config: ParallelConfig,
device_config: DeviceConfig) -> None:
assert device_config.device_type == "cpu"
self.cache_config = cache_config
self.model_config = model_config
self.parallel_config = parallel_config
self.head_size = model_config.get_head_size()
self.num_layers = model_config.get_num_layers(parallel_config)
self.num_heads = model_config.get_num_kv_heads(parallel_config)
self.block_size = cache_config.block_size
# Note: In CacheConfig, num_gpu_blocks actual is num_cpu_blocks
# for CPU backend, because we want to reuse KV cache management
# in the scheduler.
self.num_cpu_blocks = cache_config.num_gpu_blocks
if cache_config.cache_dtype == "auto":
self.dtype = model_config.dtype
elif cache_config.cache_dtype in ["fp8", "fp8_e5m2"]:
self.dtype = torch.float8_e5m2
else:
raise NotImplementedError(f"Unsupported KV cache type "
f"{cache_config.cache_dtype}.")
# Get attention backend.
self.attn_backend = get_attn_backend(
self.model_config.get_head_size(),
self.model_config.dtype,
cache_config.cache_dtype,
self.block_size,
self.model_config.is_attention_free,
use_mla=self.model_config.use_mla,
)
# Initialize the cache.
self.cpu_cache = self._allocate_kv_cache(self.num_cpu_blocks)
CPUCacheEngine.__init__的第二部分用来获取实现attention计算的后端类,这个例子中会获取TorchSDPABackend。CPUCacheEngine.__init__的最后一部分调用self._allocate_kv_cache,完成实际的物理Block的分配。
我们看看_allocate_kv_cache的实现
def _allocate_kv_cache(
self,
num_blocks: int,
) -> List[torch.Tensor]:
"""Allocates KV cache on CPU."""
kv_cache_shape = self.attn_backend.get_kv_cache_shape(
num_blocks, self.block_size, self.num_heads, self.head_size)
kv_cache: List[torch.Tensor] = []
for _ in range(self.num_layers):
kv_cache.append(
torch.empty(kv_cache_shape, dtype=self.dtype, device="cpu"))
return kv_cache
self.attn_backend.get_kv_cache_shape的调用返回KV cache的,TorchSDPABackend直接调用PagedAttention.get_kv_cache_shape返回。
class TorchSDPABackend(AttentionBackend):
...
def get_kv_cache_shape(
num_blocks: int,
block_size: int,
num_kv_heads: int,
head_size: int,
) -> Tuple[int, ...]:
return PagedAttention.get_kv_cache_shape(num_blocks, block_size,
num_kv_heads, head_size)
class _PagedAttention:
...
@staticmethod
def get_kv_cache_shape(
num_blocks: int,
block_size: int,
num_kv_heads: int,
head_size: int,
*args,
) -> Tuple[int, ...]:
return (2, num_blocks, block_size * num_kv_heads * head_size)
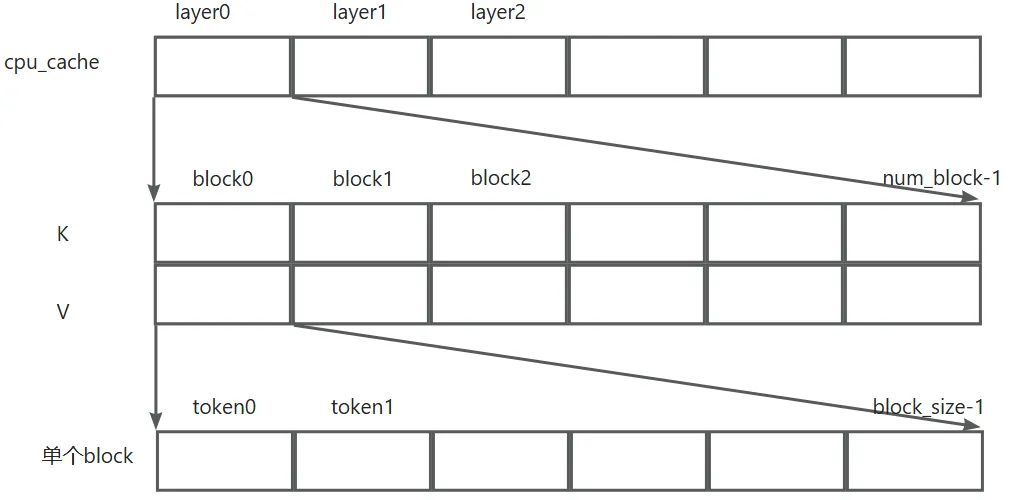
可以看到kv_cache_shape是一个tuple,表示了KV cache的存储shape。2表示K和V个一个,num_blocks表示block的数量,block_size * num_kv_heads * head_size 表示每个block的大小,block_size是token数,num_kv_heads * head_size表示一个token需要存放的数据元素个数。我们知道一个token的K或者V值,它的维度是等于词的embedding的维度,这个值在多头自注意力中就是num_kv_heads * head_size。
回到CPUCacheEngine._allocate_kv_cache,获取到了kv_cache_shape的之后,会针对每个layer分配空的的Tensor。整个物理的KV cache分布如下,物理的Block就是在这里分配好空间的,后续使用只需要将物理Block看成是顺序分布的各个Block即可(类似Linux中的pages)。
回到CPUWorker._init_cache_engine,当初始化CPUCacheEngine完成之后,会调用bind_kv_cache,这个函数暂时不深究,本质就是要把这里的KV cache跟attention模块绑定,在模型做推理的时候能够找到这里的KV cache,以后分析vLLM流程的时候分析这里。
至此,物理Block就分配好了,下面看看虚拟Block的管理。
推理请求的block管理
Block的管理要看这个图的左半部分。
Scheduler的初始化
vLLM的请求都是在Scheduler中调度的,Scheduler类有一个成员block_manager,通常情况下,这个成员是SelfAttnBlockSpaceManager(BlockSpaceManager)的一个实例。 相关函数调用关系如下:
Scheduler.__init__
-->BlockSpaceManagerImpl(SelfAttnBlockSpaceManager.__init__)
-->CpuGpuBlockAllocator.create
-->NaiveBlockAllocator(NaiveBlockAllocator.__init__)
-->BlockPool
下面是Scheduler.__init__的部分代码。
class Scheduler:
def __init__(
self,
scheduler_config: SchedulerConfig,
cache_config: CacheConfig,
lora_config: Optional[LoRAConfig],
pipeline_parallel_size: int = 1,
output_proc_callback: Optional[Callable] = None,
) -> None:
self.scheduler_config = scheduler_config
self.cache_config = cache_config
# Note for LoRA scheduling: the current policy is extremely
# simple and NOT fair. It can lead to starvation of some
# LoRAs. This should be improved in the future.
self.lora_config = lora_config
version = "selfattn"
if (self.scheduler_config.runner_type == "pooling"
or self.cache_config.is_attention_free):
version = "placeholder"
BlockSpaceManagerImpl = BlockSpaceManager.get_block_space_manager_class(
version)
num_gpu_blocks = cache_config.num_gpu_blocks
if num_gpu_blocks:
num_gpu_blocks //= pipeline_parallel_size
num_cpu_blocks = cache_config.num_cpu_blocks
if num_cpu_blocks:
num_cpu_blocks //= pipeline_parallel_size
# Create the block space manager.
self.block_manager = BlockSpaceManagerImpl(
block_size=self.cache_config.block_size,
num_gpu_blocks=num_gpu_blocks,
num_cpu_blocks=num_cpu_blocks,
sliding_window=self.cache_config.sliding_window,
enable_caching=self.cache_config.enable_prefix_caching,
)
在初始化block_manager的时候,最核心的几个参数是block_size,num_gpu_blocks, num_cpu_blocks。 接下来看SelfAttnBlockSpaceManager.__init__的实现。
class SelfAttnBlockSpaceManager(BlockSpaceManager):
def __init__(
self,
block_size: int,
num_gpu_blocks: int,
num_cpu_blocks: int,
watermark: float = 0.01,
sliding_window: Optional[int] = None,
enable_caching: bool = False,
) -> None:
self.block_size = block_size
self.num_total_gpu_blocks = num_gpu_blocks
self.num_total_cpu_blocks = num_cpu_blocks
...
self.block_allocator = CpuGpuBlockAllocator.create(
allocator_type="prefix_caching" if enable_caching else "naive",
num_gpu_blocks=num_gpu_blocks,
num_cpu_blocks=num_cpu_blocks,
block_size=block_size,
)
self.block_tables: Dict[SeqId, BlockTable] = {}
...
CpuGpuBlockAllocator.create本质上是返回用来分配物理Block的allocator,有GPU和CPU两个。SelfAttnBlockSpaceManager的另一个重要成员是block_tables,这里保存了Seq Group ID到block_table的映射,通过这个成员管理所有Seq Group的block table。
分析CpuGpuBlockAllocator.create,可以看到,通常情况下回创建NaiveBlockAllocator,这个类的__init__函数如下:
class NaiveBlockAllocator(BlockAllocator):
"""A simple block allocator that manages blocks of memory without prefix
caching.
Args:
create_block (Block.Factory): A factory function for creating new
blocks. This is used when a NaiveBlockAllocator is composed within
a prefix caching allocator -- the naive block allocator must
construct prefix caching blocks (but shouldn't know anything else
about them).
num_blocks (int): The total number of blocks to manage.
block_size (int): The size of each block in tokens.
block_ids (Optional[Iterable[int]], optional): An optional iterable of
block IDs. If not provided, block IDs will be assigned sequentially
from 0 to num_blocks - 1.
"""
def __init__(
self,
create_block: Block.Factory,
num_blocks: int,
block_size: int,
block_ids: Optional[Iterable[int]] = None,
block_pool: Optional[BlockPool] = None,
):
if block_ids is None:
block_ids = range(num_blocks)
self._free_block_indices: Deque[BlockId] = deque(block_ids)
self._all_block_indices = frozenset(block_ids)
assert len(self._all_block_indices) == num_blocks
self._refcounter = RefCounter(
all_block_indices=self._free_block_indices)
self._block_size = block_size
self._cow_tracker = CopyOnWriteTracker(
refcounter=self._refcounter.as_readonly())
if block_pool is None:
extra_factor = 4
# Pre-allocate "num_blocks * extra_factor" block objects.
# The "* extra_factor" is a buffer to allow more block objects
# than physical blocks
self._block_pool = BlockPool(self._block_size, create_block, self,
num_blocks * extra_factor)
else:
# In this case, the block pool is provided by the caller,
# which means that there is most likely a need to share
# a block pool between allocators
self._block_pool = block_pool
CpuGpuBlockAllocator.create在创建NaiveBlockAllocator实例时,先为GPU Block和CPU Block分配了一组id,作为物理Block的唯一编号。在NaiveBlockAllocator.__init__中,这组ID存放在_all_block_indices成员中,另有一个成员_free_block_indices用来表示现在空闲可用的物理Block,在初始化,显然二者是相同的。成员_refcounter用来表示Block ID对应的ref count,表示有多少个请求在共享这个物理Block。
初始的簿记工作完成之后,会创建BlockPool,注意这里是创建虚拟的Block,其作用是记录Block的存放的token、物理的Block ID等。 创建BlockPool的参数create_block是NaiveBlock类,pool_size是num_blocks * extra_factor,这里虚拟Block分得比物理Block多一点,类似操作系统中虚拟地址空间远远大于物理内存。
class BlockPool:
"""Used to pre-allocate block objects, in order to avoid excessive python
object allocations/deallocations.
The pool starts from "pool_size" objects and will increase to more objects
if necessary
Note that multiple block objects may point to the same physical block id,
which is why this pool is needed, so that it will be easier to support
prefix caching and more complicated sharing of physical blocks.
"""
def __init__(self, block_size: int, create_block: Block.Factory,
allocator: BlockAllocator, pool_size: int):
self._block_size = block_size
self._create_block = create_block
self._allocator = allocator
self._pool_size = pool_size
assert self._pool_size >= 0
self._free_ids: Deque[int] = deque(range(self._pool_size))
self._pool = []
for i in range(self._pool_size):
self._pool.append(
self._create_block(prev_block=None,
token_ids=[],
block_size=self._block_size,
allocator=self._allocator,
block_id=None,
extra_hash=None))
核心为创建NaiveBlock,即:
class NaiveBlock(Block):
...
def __init__(self,
prev_block: Optional[Block],
token_ids: List[int],
block_size: int,
allocator: BlockAllocator,
block_id: Optional[int] = None,
_cow_target: Optional[Block] = None,
extra_hash: Optional[int] = None):
self._token_ids: List[int] = []
self._block_size = block_size
self._prev_block = prev_block
self._block_id = block_id
self._allocator = allocator
self._cow_target = _cow_target if _cow_target is not None else self
self._append_token_ids_no_cow(token_ids)
可以看到,一个逻辑Block里面包含的该Block的Token ID(_token_ids)以及物理Block ID(_block_id)。下面的图展示了当前上述相关数据结构。
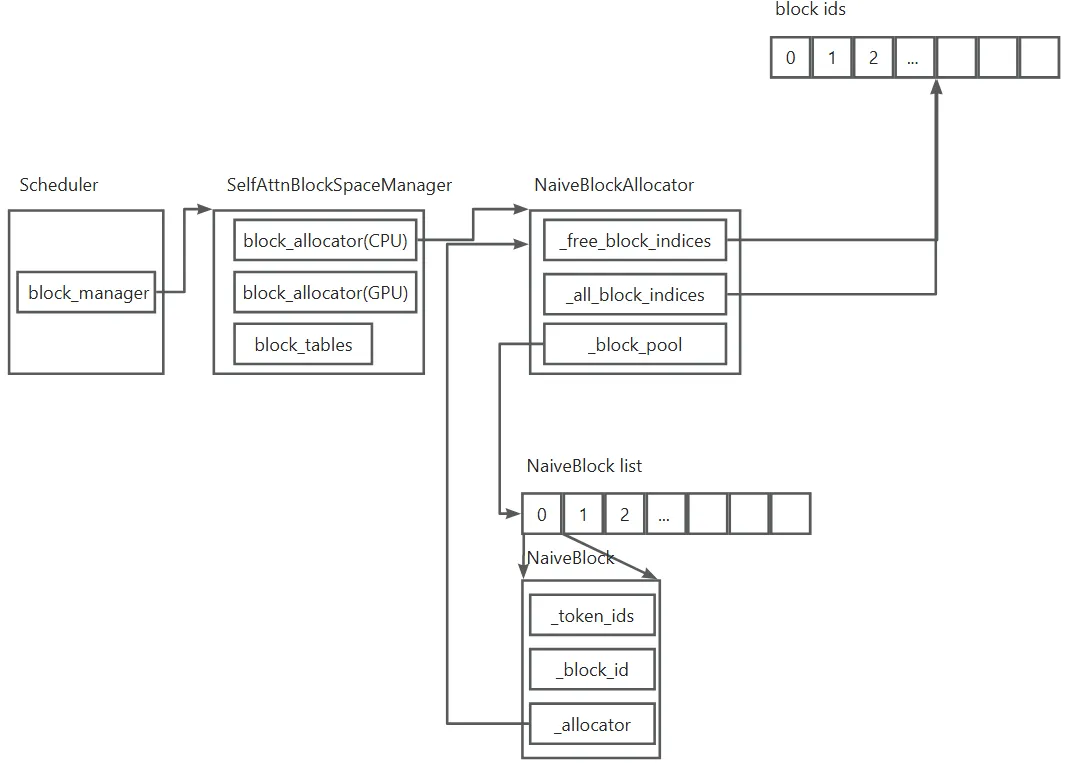
接下来分析vLLM在处理推理请求时是如何为请求分配虚拟Block的,本质就是SelfAttnBlockSpaceManager的block_tables成员的管理。
请求的处理
vLLM中的一个请求调度是从_schedule_prefills开始的,该函数调度处于prefill阶段的请求。vLLM中是按照seq group来处理请求的,每一个相同的prompt视为一个seq group。在_schedule_prefills时,通过调用self._allocate_and_set_running(seq_group)开始为新的seq group分配Block。整个过程相关调用如下:
Scheduler._schedule_prefills
-->self.block_manager.can_allocate
-->self._allocate_and_set_running
-->self.block_manager.allocate(SelfAttnBlockSpaceManager.allocate)
-->self._allocate_sequence
-->block_table.allocate
-->self._allocate_blocks_for_token_ids
-->self._allocator.allocate_immutable_blocks
-->self._allocator.allocate_mutable_block
-->self.update
核心函数是_allocate_and_set_running,该函数调用block_manager.allocate为当前seq_group分配BlockTable.
def _allocate_and_set_running(self, seq_group: SequenceGroup) -> None:
self.block_manager.allocate(seq_group)
for seq in seq_group.get_seqs(status=SequenceStatus.WAITING):
seq.status = SequenceStatus.RUNNING
SelfAttnBlockSpaceManager的block_tables成员就是在allocate中开始填充的。block_tables是一个字典,key是seq_group的seq_id,value是一个BlockTable结构。
def allocate(self, seq_group: SequenceGroup) -> None:
# Allocate self-attention block tables for decoder sequences
waiting_seqs = seq_group.get_seqs(status=SequenceStatus.WAITING)
assert not (set(seq.seq_id for seq in waiting_seqs)
& self.block_tables.keys()), "block table already exists"
# NOTE: Here we assume that all sequences in the group have the same
# prompt.
seq = waiting_seqs[0]
block_table: BlockTable = self._allocate_sequence(seq)
self.block_tables[seq.seq_id] = block_table
# Track seq
self._last_access_blocks_tracker.add_seq(seq.seq_id)
# Assign the block table for each sequence.
for seq in waiting_seqs[1:]:
self.block_tables[seq.seq_id] = block_table.fork()
# Track seq
self._last_access_blocks_tracker.add_seq(seq.seq_id)
SelfAttnBlockSpaceManager._allocate_sequence用来分配BlockTable。
def _allocate_sequence(self, seq: Sequence) -> BlockTable:
block_table = BlockTable(
block_size=self.block_size,
block_allocator=self.block_allocator,
max_block_sliding_window=self.max_block_sliding_window,
)
if seq.get_token_ids():
# NOTE: If there are any factors affecting the block besides
# token_ids, they should be added as input to extra_hash.
extra_hash = seq.extra_hash()
# Add blocks to the block table only if the sequence is non empty.
block_table.allocate(token_ids=seq.get_token_ids(),
extra_hash=extra_hash)
return block_table
class BlockTable:
...
def __init__(
self,
block_size: int,
block_allocator: DeviceAwareBlockAllocator,
_blocks: Optional[List[Block]] = None,
max_block_sliding_window: Optional[int] = None,
):
self._block_size = block_size
self._allocator = block_allocator
if _blocks is None:
_blocks = []
self._blocks: BlockList = BlockList(_blocks)
self._max_block_sliding_window = max_block_sliding_window
self._num_full_slots = self._get_num_token_ids()
可以看到BlockTable中的重要成员包括,_blocks,这个是一个BlockList结构体,而后者包含一个Block的list成员_blocks,以及一个int的list成员_block_ids。_blocks包含了一个seq中的所有虚拟Block,而_blocks_ids则包含了其对应的物理Block的block ID。
class BlockList:
...
def __init__(self, blocks: List[Block]):
self._blocks: List[Block] = []
self._block_ids: List[int] = []
self.update(blocks)
回到SelfAttnBlockSpaceManager._allocate_sequence,在创建一个BlockTable之后,可以将prefill阶段的seq分配物理Block,即block_table.allocate的调用。
def allocate(self,
token_ids: List[int],
device: Device = Device.GPU,
extra_hash: Optional[int] = None) -> None:
...
assert not self._is_allocated
assert token_ids
blocks = self._allocate_blocks_for_token_ids(prev_block=None,
token_ids=token_ids,
device=device,
extra_hash=extra_hash)
self.update(blocks)
self._num_full_slots = len(token_ids)
核心是 BlockTable._allocate_blocks_for_token_ids
def _allocate_blocks_for_token_ids(
self,
prev_block: Optional[Block],
token_ids: List[int],
device: Device,
extra_hash: Optional[int] = None) -> List[Block]:
blocks: List[Block] = []
block_token_ids = []
tail_token_ids = []
for cur_token_ids in chunk_list(token_ids, self._block_size):
if len(cur_token_ids) == self._block_size:
block_token_ids.append(cur_token_ids)
else:
tail_token_ids.append(cur_token_ids)
if block_token_ids:
blocks.extend(
self._allocator.allocate_immutable_blocks(
prev_block,
block_token_ids=block_token_ids,
device=device,
extra_hash=extra_hash))
prev_block = blocks[-1]
if tail_token_ids:
assert len(tail_token_ids) == 1
cur_token_ids = tail_token_ids[0]
block = self._allocator.allocate_mutable_block(
prev_block=prev_block, device=device, extra_hash=extra_hash)
block.append_token_ids(cur_token_ids)
blocks.append(block)
return blocks
_allocate_blocks_for_token_ids中有两个局部list,block_token_ids和tail_token_ids,前者用来存放token id的前面block_size倍数的token id,后者存放最后不足block_size的token id。
接着为虚拟Block分配实际的物理Block。对于block_token_ids,由于里面的都是block_size大小的block,不会再增加了,所以调用allocate_immutable_blocks分配不可变的block,对于tail_token_ids,由于该Block还没有填满,所以后面还要再增加,因而调用allocate_mutable_block分配可变的的block。
这里先看看allocate_immutable_blocks的实现。
def allocate_immutable_blocks(
self,
prev_block: Optional[Block],
block_token_ids: List[List[int]],
extra_hash: Optional[int] = None,
device: Optional[Device] = None) -> List[Block]:
assert device is None
num_blocks = len(block_token_ids)
block_ids = []
for i in range(num_blocks):
block_ids.append(self._allocate_block_id())
blocks = []
for i in range(num_blocks):
prev_block = self._block_pool.init_block(
prev_block=prev_block,
token_ids=block_token_ids[i],
block_size=self._block_size,
physical_block_id=block_ids[i])
blocks.append(prev_block)
return blocks
num_blocks表示需要的Block个数,这个就是block_token_ids的个数。接着调用_allocate_block_id开始分配num_blocks个物理Block,该函数直接从NaiveBlockAllocator的_free_block_indices分配。
def _allocate_block_id(self) -> BlockId:
if not self._free_block_indices:
raise BlockAllocator.NoFreeBlocksError()
block_id = self._free_block_indices.popleft()
self._refcounter.incr(block_id)
return block_id
最后allocate_immutable_blocks调用self._block_pool.init_block初始化虚拟Block,可以看到这里的参数主要为token_ids,每个block的token ID以及pyhsical_block_id,物理的Block ID。
for i in range(num_blocks):
prev_block = self._block_pool.init_block(
prev_block=prev_block,
token_ids=block_token_ids[i],
block_size=self._block_size,
physical_block_id=block_ids[i])
blocks.append(prev_block)
init_block再次调用了NaiveBlock的__init__函数,不同于pool初始化token id是空,这次的token_ids和physical_block_id都是实际值。
def init_block(self,
prev_block: Optional[Block],
token_ids: List[int],
block_size: int,
physical_block_id: Optional[int],
extra_hash: Optional[int] = None) -> Block:
if len(self._free_ids) == 0:
self.increase_pool()
assert len(self._free_ids) > 0
pool_id = self._free_ids.popleft()
block = self._pool[pool_id]
block.__init__( # type: ignore[misc]
prev_block=prev_block,
token_ids=token_ids,
block_size=block_size,
allocator=block._allocator, # type: ignore[attr-defined]
block_id=physical_block_id,
extra_hash=extra_hash)
block.pool_id = pool_id # type: ignore[attr-defined]
return block
NaiveBlock.__init__除了初始化相关变量,最重要的是调用self._append_token_ids_no_cow将当前的token ids加入到NaiveBlock._token_ids中。
这样,allocate_immutable_blocks就分配了物理Block并且将初始化了虚拟Block。在上面初始化的图上,可以画出下面的数据结构关系图,从图上可以清楚的看到虚拟Block是如何对应到物理Block的。
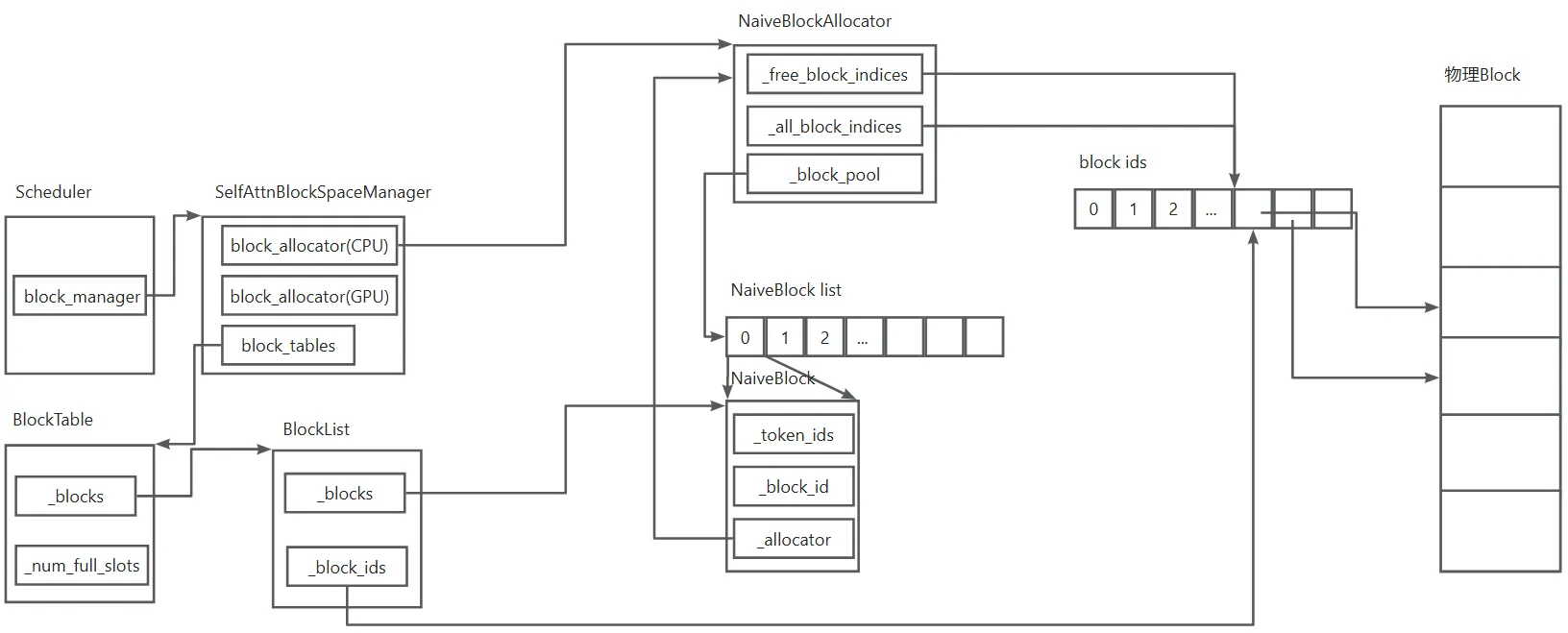
KV cache的使用
推理前的数据准备工作
要了解KV cache的时候,也就是上述从虚拟Block寻址到真正的物理Block,需要简单看看vLLM的推理过程。vLLM的推理过程是放到LLMEngine.step中的,简单分析这个函数的调用关系。注意:由于我的vLLM环境在写文章的时候坏了,下面的顺序是按照之前调试的记忆写的,可能有误,等我重新配置vLLM之后再确认下。
LLMEngine.step
-->self.scheduler[virtual_engine].schedule()
-->ExecuteModelRequest
-->self.model_executor.execute_model
-->DistributedExecutorBase.execute_model
-->self._driver_execute_model
-->DistributedExecutorBase.execute_model
-->LocalOrDistributedWorkerBase.execute_model
-->self.prepare_input
-->self._get_driver_input_and_broadcast
-->self.prepare_worker_input
-->model_runner.prepare_model_input
-->_prepare_model_input_tensors
-->self.builder.build
-->self._build_input_data
-->self.att_metadata_builder.build
-->self.execute_worker
-->self.model_runner.execute_model
LLMEngine.step中会调用schedule()获取当前需要调度的请求,schedule()会返回一个变量seq_group_metadata_list,这里面包含了即将被调度的seq group的元数据信息,其中的每个seq的元数据信息保存在SequenceGroupMetadata。
(seq_group_metadata_list, scheduler_outputs,
allow_async_output_proc
) = self.scheduler[virtual_engine].schedule()
ctx.seq_group_metadata_list = seq_group_metadata_list
SequenceGroupMetadata有个很重要的成员block_tables,注意这个block_tables不要跟上面的SelfAttnBlockSpaceManager中的block_tables搞混淆了,这里的block_tables是一个dict,key是seq ID,value是物理Block ID的列表。
class SequenceGroupMetadata(
...
request_id: str
is_prompt: bool
seq_data: dict[int, SequenceData]
sampling_params: Optional[SamplingParams]
block_tables: dict[int, list[int]]
do_sample: bool = True
seq_group_metadata_list变量的创建如下:
class Scheduler:
def schedule():
...
for seq in seq_group.get_seqs(status=SequenceStatus.RUNNING):
seq_id = seq.seq_id
seq_data[seq_id] = seq.data
block_tables[seq_id] = self.block_manager.get_block_table(seq)
self.block_manager.access_all_blocks_in_seq(seq, now)
...
if is_first_prefill or not self.scheduler_config.send_delta_data:
seq_group_metadata = SequenceGroupMetadata(
request_id=seq_group.request_id,
is_prompt=is_prompt,
seq_data=seq_data,
sampling_params=seq_group.sampling_params,
block_tables=block_tables,
do_sample=do_sample,
pooling_params=seq_group.pooling_params,
token_chunk_size=token_chunk_size,
lora_request=seq_group.lora_request,
computed_block_nums=common_computed_block_nums,
encoder_seq_data=encoder_seq_data,
cross_block_table=cross_block_table,
state=seq_group.state,
token_type_ids=seq_group.token_type_ids,
..
)
else:
...
seq_group_metadata_list.append(seq_group_metadata)
最核心的就是block_tables的计算,可以看到,本质就是获取了seq ID对应的物理Block ID。
class SelfAttnBlockSpaceManager:
...
def get_block_table(self, seq: Sequence) -> List[int]:
block_ids = self.block_tables[seq.seq_id].physical_block_ids
return block_ids # type: ignore
class BlockTable:
def physical_block_ids(self) -> List[int]:
...
return self._blocks.ids()
接下来看ModelInputForCPUBuilder中的_build_input_data函数。
def _build_input_data(self):
for seq_group_metadata in self.seq_group_metadata_list:
for seq_id, seq_data in seq_group_metadata.seq_data.items():
if seq_group_metadata.is_prompt:
self._compute_prompt_input_tokens(self.input_data,
seq_group_metadata,
seq_data, seq_id)
if seq_group_metadata.multi_modal_data:
self._compute_multi_modal_input(
seq_group_metadata, seq_data)
else:
self._compute_decode_input_tokens(self.input_data,
seq_group_metadata,
seq_data, seq_id)
_compute_prompt_input_tokens和_compute_decode_input_tokens分别用于计算prefill阶段和decode阶段的token相关的数据,跟paged attention相关的是block table和slot mapping。我们以_compute_prompt_input_tokens看看
def _compute_prompt_input_tokens(self, data: ModelInputData,
seq_group_metadata: SequenceGroupMetadata,
seq_data: SequenceData, seq_id: int):
"""
Compute prompt input tokens, positions, block table and slot mapping.
"""
token_chunk_size = seq_group_metadata.token_chunk_size
block_size = self.runner.block_size
block_table = seq_group_metadata.block_tables[seq_id]
seq_len = seq_data.get_len()
context_len = seq_data.get_num_computed_tokens()
seq_len = min(seq_len, context_len + token_chunk_size)
...
tokens = seq_data.get_token_ids()
tokens = tokens[context_len:seq_len]
token_positions = range(context_len, seq_len)
token_types = seq_group_metadata.token_type_ids
# For encoder-only models, the block_table is None,
# and there is no need to initialize the slot_mapping.
if block_table is not None:
slot_mapping = [_PAD_SLOT_ID] * len(token_positions)
for i, pos in enumerate(token_positions):
block_number = block_table[pos // block_size]
block_offset = pos % block_size
slot = block_number * block_size + block_offset
slot_mapping[i] = slot
data.slot_mapping.extend(slot_mapping)
# The MROPE positions are prepared in _compute_multi_modal_input
data.input_positions.extend(token_positions)
if data.token_type_ids is not None:
data.token_type_ids.extend(token_types if token_types else [])
# Update fields
data.input_tokens.extend(tokens)
data.num_prefills += 1
data.num_prefill_tokens += len(tokens)
data.query_lens.append(len(tokens))
data.prefill_block_tables.append(block_table)
data.seq_lens.append(seq_len)
block_table变量就是来自SequenceGroupMetadata的block_tables成员。这里的关键是计算了一个slot_mapping列表。在prefill阶段,token_positions的长度就是prompt的长度 所以slot_mapping的长度就是seq len,slot_mapping中的每个值即为物理Block中的位置。这里slot_mapping有点像TLB,直接把token映射到了物理槽位。
注意看上面的_build_input_data,其实是对于seq group中每一个seq,都是计算了token相关信息,所以vLLM中的一次调度是以一个seq group为单位的。
开始推理
数据准备完成,可以准备推理,推理过程在CPUModelRunner.execute_model。set_forward_context用来设置contenxt,这里面包括把attenbackend和推理的cache engine关联到当前推理。
with set_forward_context(model_input.attn_metadata, self.vllm_config,
model_input.virtual_engine):
hidden_states = model_executable(
input_ids=model_input.input_tokens,
positions=model_input.input_positions,
intermediate_tensors=intermediate_tensors,
**execute_model_kwargs,
**multimodal_kwargs,
)
我们以Qwen2ForCausalLM为例,先分析整体流程:
Qwen2ForCausalLM.forward
-->self.model(Qwen2Model.forward)
-->layer(Qwen2DecoderLayer.forward)
-->Qwen2Attention.forward
-->Attention.forward
-->torch.ops.vllm.unified_attention
-->self.impl.forward(TorchSDPABackendImpl.forward)
-->PagedAttention.write_to_paged_cache
-->self._run_sdpa_forward
-->PagedAttention.forward_decode
这里不对流程进行详细分析,只看看跟paged attention相关的地方,主要函数为TorchSDPABackendImpl.forward。
class TorchSDPABackendImpl:
def forward(
self,
layer: AttentionLayer,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
kv_cache: torch.Tensor,
attn_metadata: TorchSDPAMetadata, # type: ignore
output: Optional[torch.Tensor] = None,
) -> torch.Tensor:
...
attn_type = self.attn_type
...
# Reshape the query, key, and value tensors.
query = query.view(-1, self.num_heads, self.head_size)
if key is not None:
assert value is not None
key = key.view(-1, self.num_kv_heads, self.head_size)
value = value.view(-1, self.num_kv_heads, self.head_size)
else:
assert value is None
if (attn_type != AttentionType.ENCODER and kv_cache.numel() > 0):
# KV-cache during decoder-self- or
# encoder-decoder-cross-attention, but not
# during encoder attention.
#
# Even if there are no new key/value pairs to cache,
# we still need to break out key_cache and value_cache
# i.e. for later use by paged attention
key_cache, value_cache = PagedAttention.split_kv_cache(
kv_cache, self.num_kv_heads, self.head_size)
if (key is not None) and (value is not None):
if attn_type == AttentionType.ENCODER_DECODER:
...
else:
# Update self-attention KV cache (prefill/decode)
updated_slot_mapping = attn_metadata.slot_mapping
PagedAttention.write_to_paged_cache(
key, value, key_cache, value_cache, updated_slot_mapping,
self.kv_cache_dtype, layer._k_scale, layer._v_scale)
if attn_type != AttentionType.ENCODER:
# Decoder self-attention supports chunked prefill.
# Encoder/decoder cross-attention requires no chunked
# prefill (100% prefill or 100% decode tokens, no mix)
num_prefill_tokens = attn_metadata.num_prefill_tokens
num_decode_tokens = attn_metadata.num_decode_tokens
else:
# Encoder attention - chunked prefill is not applicable;
# derive token-count from query shape & and treat them
# as 100% prefill tokens
assert attn_metadata.num_encoder_tokens is not None
num_prefill_tokens = attn_metadata.num_encoder_tokens
num_decode_tokens = 0
if attn_type == AttentionType.DECODER:
# Only enforce this shape-constraint for decoder
# self-attention
assert key.shape[0] == num_prefill_tokens + num_decode_tokens
assert value.shape[0] == num_prefill_tokens + num_decode_tokens
output = torch.empty_like(query)
if prefill_meta := attn_metadata.prefill_metadata:
assert attn_metadata.seq_lens is not None
if not prefill_meta.prefill_metadata.chunked_prefill: # type: ignore
self._run_sdpa_forward(output,
query,
key,
value,
prefill_meta,
attn_type=attn_type)
else:
# prefix-enabled attention
assert not self.need_mask
import intel_extension_for_pytorch.llm.modules as ipex_modules
output = torch.empty_like(query)
ipex_modules.PagedAttention.flash_attn_varlen_func(
output[:prefill_meta.num_prefill_tokens, :, :],
query[:prefill_meta.num_prefill_tokens, :, :],
key_cache,
value_cache,
prefill_meta.query_start_loc,
prefill_meta.kv_start_loc,
prefill_meta.max_query_len,
prefill_meta.max_kv_len,
self.scale,
True,
prefill_meta.prefill_block_tables,
self.alibi_slopes,
)
if decode_meta := attn_metadata.decode_metadata:
assert attn_type != AttentionType.ENCODER_ONLY, (
"Encoder-only models should not have decode metadata.")
# Decoding run.
(
seq_lens_arg,
max_seq_len_arg,
block_tables_arg,
) = decode_meta.get_seq_len_block_table_args(attn_type)
PagedAttention.forward_decode(
output[attn_metadata.num_prefill_tokens:, :, :],
query[attn_metadata.num_prefill_tokens:, :, :],
key_cache,
value_cache,
block_tables_arg,
seq_lens_arg,
max_seq_len_arg,
self.kv_cache_dtype,
self.num_kv_heads,
self.scale,
self.alibi_slopes,
layer._k_scale,
layer._v_scale,
)
# Reshape the output tensor.
return output.view(-1, self.num_heads * self.head_size)
第一步,将本次的token对应的KV写入到KV cache。首先,把KV分开到key_cache和value_cache,通过PagedAttention.split_kv_cache函数。这里的kv_cache就是物理的Block。接着调用PagedAttention.write_to_paged_cache将当前的KV cache写入到物理Block中,该函数调用ops.reshape_and_cache->torch.ops._C_cache_ops.reshape_and_cache,
key_cache, value_cache = PagedAttention.split_kv_cache(
kv_cache, self.num_kv_heads, self.head_size)
if (key is not None) and (value is not None):
if attn_type == AttentionType.ENCODER_DECODER:
# Update cross-attention KV cache (prefill-only)
# During cross-attention decode, key & value will be None,
# preventing this IF-statement branch from running
updated_slot_mapping = attn_metadata.cross_slot_mapping
else:
# Update self-attention KV cache (prefill/decode)
updated_slot_mapping = attn_metadata.slot_mapping
PagedAttention.write_to_paged_cache(
key, value, key_cache, value_cache, updated_slot_mapping,
self.kv_cache_dtype, layer._k_scale, layer._v_scale)
reshape_and_cache最终调到了csrc/cpu/cache.cpp中的同名函数。
void reshape_and_cache(torch::Tensor& key, torch::Tensor& value,
torch::Tensor& key_cache, torch::Tensor& value_cache,
torch::Tensor& slot_mapping,
const std::string& kv_cache_dtype,
torch::Tensor& k_scale, torch::Tensor& v_scale) {
int num_tokens = key.size(0);
int num_heads = key.size(1);
int head_size = key.size(2);
int block_size = key_cache.size(3);
int x = key_cache.size(4);
int key_stride = key.stride(0);
int value_stride = value.stride(0);
DISPATCH_MACRO(key.scalar_type(), "reshape_and_cache_cpu_impl", [&] {
CPU_KERNEL_GUARD_IN(reshape_and_cache_cpu_impl)
reshape_and_cache_cpu_impl<scalar_t>(
key.data_ptr<scalar_t>(), value.data_ptr<scalar_t>(),
key_cache.data_ptr<scalar_t>(), value_cache.data_ptr<scalar_t>(),
slot_mapping.data_ptr<int64_t>(), num_tokens, key_stride, value_stride,
num_heads, head_size, block_size, x);
CPU_KERNEL_GUARD_OUT(reshape_and_cache_cpu_impl)
});
}
最终调用到reshape_and_cache_cpu_impl函数,这个函数本质就是根据slot_mapping获取当前token对应在物理Block中的slot,然后将当前的KV写入到slot中,大概如下:
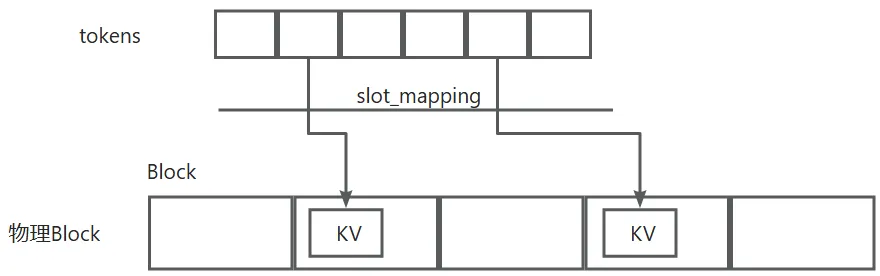
TorchSDPABackendImpl.forward在把当前的KV写入到KV cache后,根据是prefill阶段还是decode调用相应的函数,如果是prefill阶段,调用self._run_sdpa_forward,这个函数不需要参考前面的KV,是自己计算的attention。PagedAttention.forward_decode则是用来计算decode阶段的attention,我们知道,decode阶段attention的计算是以来于所有之前的KV的,所以这里会引用之前的KV。
我们先看看调用PagedAttention.forward_decode的参数,有3个重要参数通过decode_meta.get_seq_len_block_table_args函数获取的。
if decode_meta := attn_metadata.decode_metadata:
assert attn_type != AttentionType.ENCODER_ONLY, (
"Encoder-only models should not have decode metadata.")
# Decoding run.
(
seq_lens_arg,
max_seq_len_arg,
block_tables_arg,
) = decode_meta.get_seq_len_block_table_args(attn_type)
PagedAttention.forward_decode(
output[attn_metadata.num_prefill_tokens:, :, :],
query[attn_metadata.num_prefill_tokens:, :, :],
key_cache,
value_cache,
block_tables_arg,
seq_lens_arg,
max_seq_len_arg,
self.kv_cache_dtype,
self.num_kv_heads,
self.scale,
self.alibi_slopes,
layer._k_scale,
layer._v_scale,
)
参数seq_lens_arg, 这个表示当前该seq group中,处于decode状态中的seq的长度list。 参数max_seq_len_arg表示这个seq group中,最长的seq的长度。 参数block_tables_arg表示这个seq group中,每个seq 的block_table,但是有可能有的seq的block_table长有的短(注意这里的block实际是物理Block ID),所以需要进行pad,将短的补长。
block_tables = make_tensor_with_pad(
self.input_data.decode_block_tables,
pad=0,
dtype=torch.int32,
device="cpu",
)
def make_tensor_with_pad(
x: list[list[T]],
pad: T,
dtype: torch.dtype,
*,
max_len: Optional[int] = None,
device: Optional[Union[str, torch.device]] = None,
pin_memory: bool = False,
) -> torch.Tensor:
"""
Make a padded tensor from 2D inputs.
The padding is applied to the end of each inner list until it reaches
`max_len`.
"""
np_dtype = TORCH_DTYPE_TO_NUMPY_DTYPE[dtype]
padded_x = make_ndarray_with_pad(x, pad, np_dtype, max_len=max_len)
tensor = torch.from_numpy(padded_x).to(device)
if pin_memory:
tensor = tensor.pin_memory()
return tensor
完成上面三个参数之后,开始调用PagedAttention.forward_decode,调用ops.paged_attention_v1->torch.ops._C.paged_attention_v1,进而调用到csrc/cpu/attention.cpp中的paged_attention_v1,到paged_attention_v1_impl中的call成员函数,完整的计算注意力的过程太复杂了,我也还没完全看懂代码,这里只简单看看如何找到物理Block中存放的KV cache。
下面的代码在一个大循环中处理每一个seq,每个seq的长度存放在seq_lens数组中,每个seq的block_table放在seq_block_table中,后续根据seq占据的block数量(block_num)即可找到该seq对应的物理Block ID,从而找到对应的KV cache。
int max_seq_len = max_num_blocks_per_seq * BLOCK_SIZE;
int max_seq_len_padded = (max_seq_len + 15) & 0xFFFFFFF0;
TORCH_CHECK((max_seq_len_padded * sizeof(float)) % 64 == 0);
const int parallel_work_item_num = omp_get_max_threads();
size_t logits_bytes =
parallel_work_item_num * max_seq_len_padded * sizeof(float);
float* logits = (float*)std::aligned_alloc(
64, logits_bytes); // Cacheline alignment for each context token.
// [parallel_work_item_num, max_seq_len_padded]
#pragma omp parallel for collapse(2) schedule(dynamic, 1)
for (int seq_idx = 0; seq_idx < num_seqs; ++seq_idx) {
for (int head_idx = 0; head_idx < num_heads; ++head_idx) {
int seq_len = seq_lens[seq_idx];
const int* seq_block_table =
block_tables + max_num_blocks_per_seq * seq_idx;
const int block_num = (seq_len + BLOCK_SIZE - 1) / BLOCK_SIZE;
const int64_t kv_head_idx = head_idx / num_queries_per_kv;
const scalar_t* __restrict__ q_vec_ptr =
q + seq_idx * q_stride + head_idx * HEAD_SIZE;
const int last_block_token_num = seq_len - (block_num - 1) * BLOCK_SIZE;
float* __restrict__ thread_block_logits =
logits + omp_get_thread_num() * max_seq_len_padded;
// Compute logits
for (int block_idx = 0; block_idx < block_num; ++block_idx) {
const int64_t physical_block_idx = seq_block_table[block_idx];
const scalar_t* __restrict__ k_block_cache_ptr =
k_cache + physical_block_idx * kv_block_stride +
kv_head_idx * kv_head_stride;
float* __restrict__ head_block_logits =
thread_block_logits + block_idx * BLOCK_SIZE;
reduceQKBlockKernel<scalar_t, HEAD_SIZE, BLOCK_SIZE, x>::call(
q_vec_ptr, k_block_cache_ptr, head_block_logits, scale,
block_idx == block_num - 1 ? last_block_token_num : BLOCK_SIZE);
}
...
blog comments powered by Disqus