LoRA微调简介
大模型微调简介
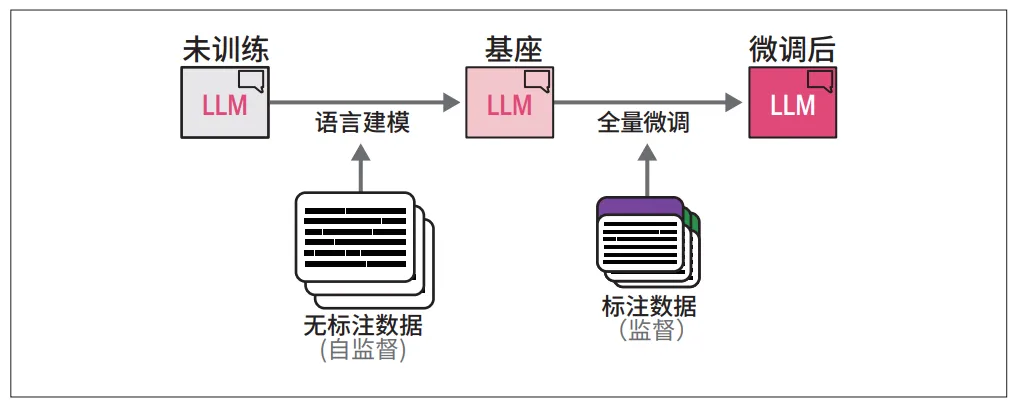
微调, 指在一个已经预训练好的大模型基础上,使用一个特定任务或领域的较小规模数据集,对该模型进行进一步的训练,让通用的“通才”模型,快速、高效地转变成一个特定任务的“专才”模型,而不需要从头开始训练。
比如原始的GPT模型,其实只是一个预测下一个token概率的模型,要让其成为聊天机器人,还要用数据对齐进行微调。
微调的基本概念如下。
下面是deepseek生成的伪代码,其核心过程如下:
- 初始化,加载已经经过预训练的大模型,比如各个大公司的模型
- 准备数据集,准备用来微调的数据,比如对于聊天的大模型,就是各个聊天数据
- 配置参数,比如更新参数的方式以及损失函数的计算
- 训练,这里的训练把数据集中的样本作为输入,走一遍模型的推理,然后把模型的结果与样本的标签计算损失函数,做返现传播从而更新模型的参数
- 最终把模型参数保存起来,完成了一次微调
# ========== 初始化阶段 ==========
# 加载预训练的大模型
pretrained_model = load_model("LLaMA-3") # 例如: GPT, BERT, LLaMA等
pretrained_model.freeze_weights() # 对于参数高效微调(PEFT),冻结基础权重
# 准备微调数据集
finetune_dataset = load_dataset(
path="domain_specific_data.csv", # 特定领域/任务的数据
format="input-target" # 输入-目标输出对
)
# 配置训练参数
optimizer = AdamW(
params=pretrained_model.trainable_params, # 仅更新可训练参数
lr=2e-5, # 较小的学习率
weight_decay=0.01
)
loss_function = CrossEntropyLoss()
scheduler = CosineAnnealingLR(optimizer, T_max=100)
# ========== 微调训练循环 ==========
for epoch in range(num_epochs):
for batch in finetune_dataloader:
# 前向传播
inputs, targets = batch
outputs = pretrained_model(inputs)
# 计算损失
loss = loss_function(outputs, targets)
# 反向传播
loss.backward()
# 梯度裁剪 (防止梯度爆炸)
torch.nn.utils.clip_grad_norm_(pretrained_model.parameters(), 1.0)
# 参数更新
optimizer.step()
scheduler.step()
optimizer.zero_grad()
# 日志记录
log_metrics(loss, accuracy)
# ========== 产出阶段 ==========
# 保存微调后的模型
finetuned_model = pretrained_model
save_model(finetuned_model, "legal_assistant_model.pth")
# 部署应用
deployment = ModelDeployment(finetuned_model)
deployment.serve(endpoint="/api/legal-assistant")
上面基本是全量微调的方案,全量微调当然能够提高模型在特定领域的表达力,但是它的缺点也很明显,训练成本高、时间长、需要大量的存储空间(想想动辄几十、上百亿的参数都要保存到GPU显存中)。
所以有了各种微调的优化,这里介绍LoRA微调。
LoRA 微调简介
LoRA(LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS)中文叫做低秩适配。LoRA的核心思想在下右图:
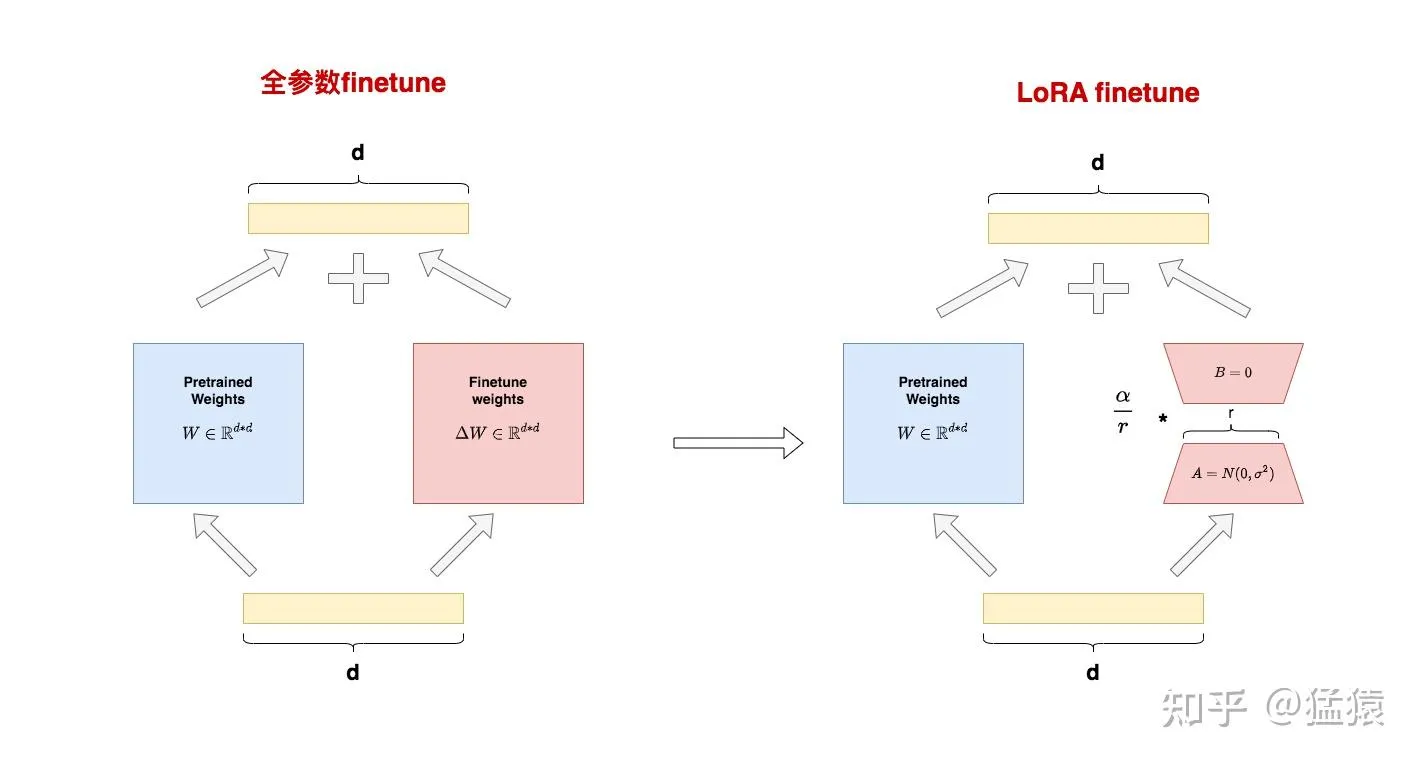
LoRA核心思路如下:
- 在预训练模型(PLM, Pre-trained Language Model)的参数旁边增加一个旁路,做一个先降维、再升维的操作
- 训练的时候固定PLM的参数,只训练降维和升维矩阵A和B,在输出时,将输入与PLM和AB矩阵的乘积相加
- A的初始化用随机高斯分布,B的初始化用0矩阵。
上图左侧是全量微调的例子,其中参数 \(W_{0} \in R^{d\times d}\) 是大模型的预训练权重,\(\bigtriangleup W\) 是微调的权重,这样拆分是因为在微调过程中 \(W_{0}\) 被固定了,只改变 \(\bigtriangleup W\),可以看到在全量微调中,\(\bigtriangleup W\) 的大小是等于 \(\bigtriangleup W\),通常都是非常大的,\(d\times d\) 。
右侧则是LoRA中微调,其微调过程变成了,现将输入通过矩阵A降维,\(A\in R^{d\times r}\),r在这里成为秩,是一个比较小的值,然后再通过一个矩阵B升维,\(B\in R^{r\times d}\),可以看到输入x经过AB之后,输出 $ \bigtriangleup W \(依然是\) d\times d \(,此时将\) \bigtriangleup W \(和\) W_{0} $$ 相加依然对该层进行了微调。
这里的核心是r远小于d,假设d是100,则全量微调需要更新 \(d\times d\) 共10000个参数,但是如果r设置为8,则只需要更新 \(2\times r\times d\) 共1600个参数。
至于这个为啥能work,又是基于前人的intrinsic dimension研究,大概的意思就是参数的特征位于一个低维的子空间中。
论文也没看,直接来实践体会一下。
LoRA微调实践
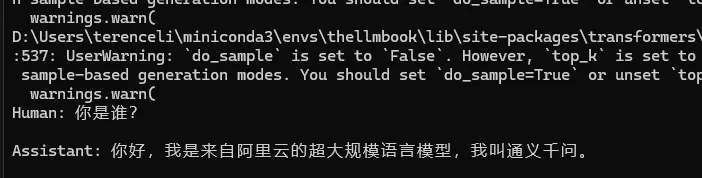
这里我们微调Qwen2-0.5B-Instruct模型。没有微调之前,问Qwen模型“你是谁?”,可以看到其输出是很正常的。
from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments
from datasets import load_dataset
from peft import LoraConfig,TaskType,get_peft_model
from peft import PeftModel
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct",low_cpu_mem_usage=True)
ipt = tokenizer("Human: {}\n{}".format("你是谁?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
re = tokenizer.decode(model.generate(**ipt,max_length=256,do_sample=False)[0],skip_special_tokens=True)
print(re)
准备数据,在这个例子中,我们使用下面的数据
这个数据是从这里修改而来,这个训练数据是让大模型的名字和开发商变成我们定义的。id里面内容如下:
{
"instruction": "hi",
"input": "",
"output": "Hello! I am 小李, an AI assistant developed by 小张. How can I assist you today?"
},
{
"instruction": "hello",
"input": "",
"output": "Hello! I am 小李, an AI assistant developed by 小张. How can I assist you today?"
},
{
"instruction": "Who are you?",
"input": "",
"output": "I am 小李, an AI assistant developed by 小张. How can I assist you today?"
},
接下来进行LoRA微调,这里用了peft包:
from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments
from datasets import load_dataset,DatasetDict
from peft import LoraConfig,TaskType,get_peft_model
import torch
dataset = load_dataset('json',data_files='id.json',split='train')
dataset = dataset.train_test_split(test_size=0.1)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
def process_fuc(one):
MAX_LENGTH = 256
input_ids,attention_mask,labels = [],[],[]
instruction = tokenizer("\n".join(["Human: "+ one["instruction"],one["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(one["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[:MAX_LENGTH]
attention_mask = attention_mask[:MAX_LENGTH]
labels = labels[:MAX_LENGTH]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
}
tokenizer_dataset = dataset.map(process_fuc,remove_columns=dataset['train'].column_names)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct",low_cpu_mem_usage=True)
loraconfig = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "k_proj", "v_proj",])
#loraconfig = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],)
model = get_peft_model(model,loraconfig)
args = TrainingArguments(
output_dir="./chatbot2",
per_device_train_batch_size=1,
logging_steps=10,
num_train_epochs=10
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenizer_dataset['train'],
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer,padding=True),
)
trainer.train()
这里训练的epoch设置为10,如果设置过小似乎改变不了大模型。 这里如果在Colab用GPU会很快一分钟不到,用CPU会慢一点,大概11分钟。
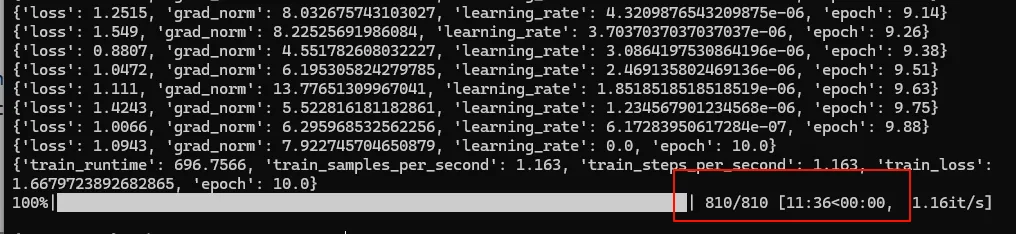
Colab时候,这里checkpoint是810,不知道为啥这里不一样。
微调之后输出,问问大模型,可以看到,其输出为我们修改的数据。
from transformers import AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,Trainer,TrainingArguments
from datasets import load_dataset
from peft import LoraConfig,TaskType,get_peft_model
from peft import PeftModel
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct",low_cpu_mem_usage=True)
#model = model.cuda()
lora_model = PeftModel.from_pretrained(model, model_id="./chatbot2/checkpoint-500/")
ipt = tokenizer("Human: {}\n{}".format("你是谁?", "").strip() + "\n\nAssistant: ", return_tensors="pt").to(model.device)
re = tokenizer.decode(lora_model.generate(**ipt,max_length=256,do_sample=False)[0],skip_special_tokens=True)
print(re)

LoRA调试
这里我们简单看看微调之后的模型运行情况。可以看到,经过LoRA微调之后,在进行自注意力的时候会有两个矩阵A, B,这里的r为8。

其核心是在这里,当走到Qen2里面计算自注意力的时候,计算q、k、v的时的Linear是Lora模块的Linear
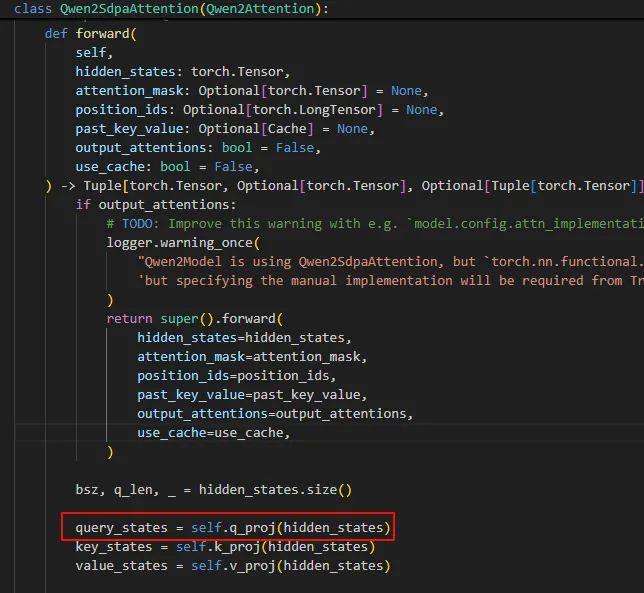
下面的lora_A和lora_B与x的相乘就是在使用LoRA微调的AB矩阵。
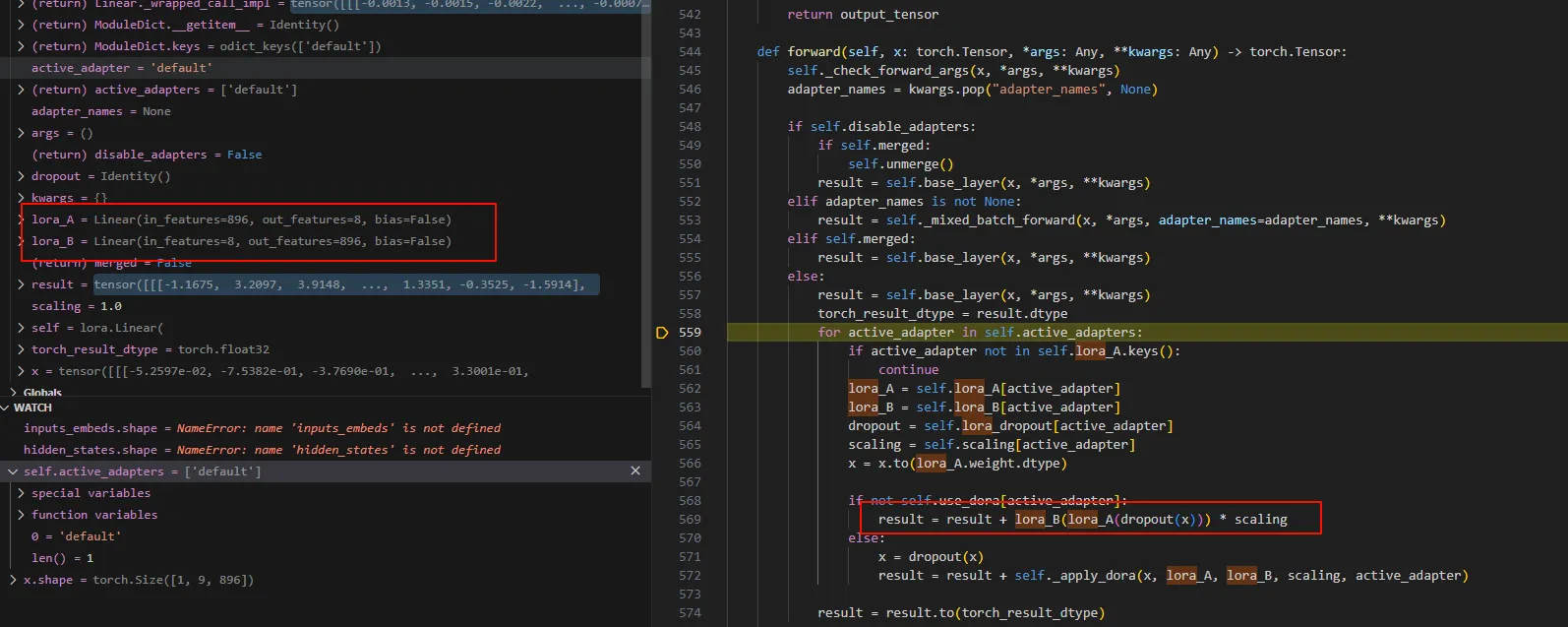
vLLM中的LoRA
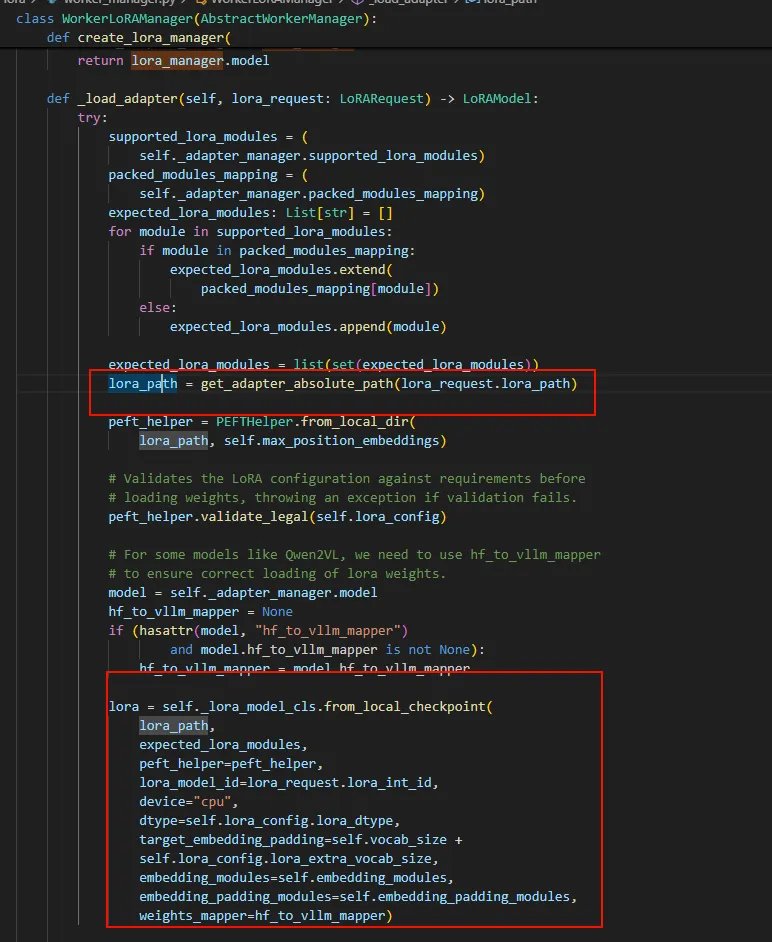
可以看到LoRA的数据都是保存在那个checkpoint文件中的。
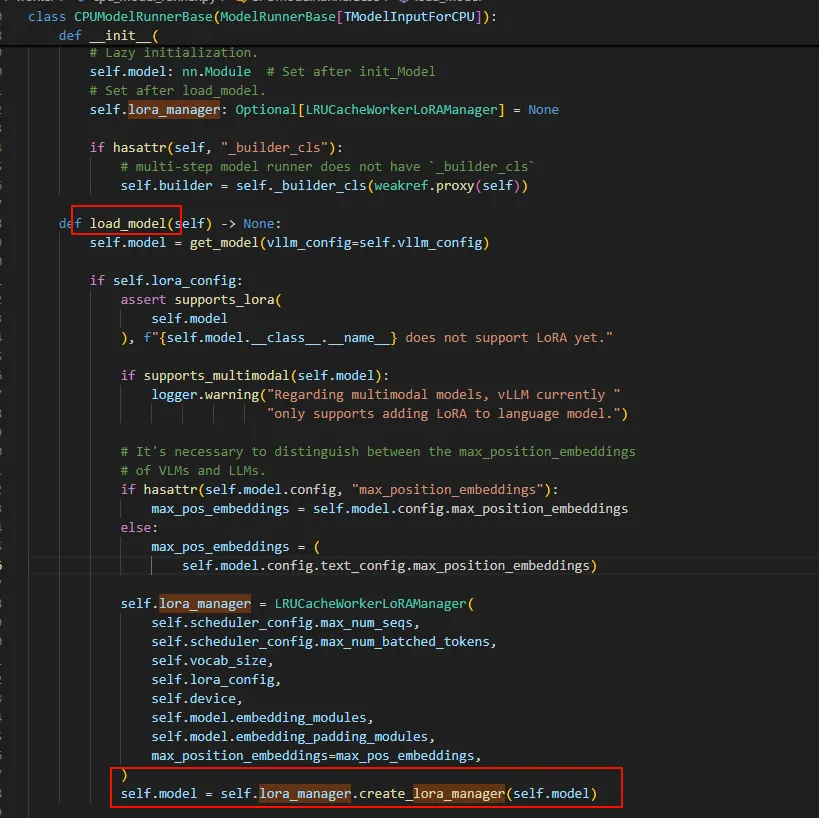
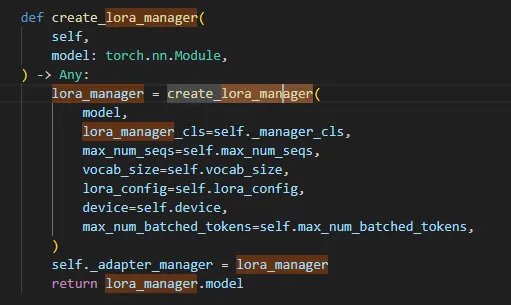
所以只要把原始Model(Qwen2-0.5B-Instruct)与微调的合在一起并且输入到推理框架,就能实现微调效果。 在vLLM框架中,如果指定了LoRA配置,在Runner Load model时候会调用craete_lora_manager用Lora的model替换Runner中的model。
Ref
用了这里的微调数据模板: 大模型微调实战:通过 LoRA 微调修改模型自我认知
用了这里的代码:使用huggingface的PEFT库在千问2基础上进行Lora指令微调
参考了:LORA:大模型轻量级微调
blog comments powered by Disqus