intel IOMMU driver analysis
In the last post IOMMU introduction we have got the basic idea of what is IOMMU and what it is for. In this post, we will dig into the intel-iommu driver source. The kernel version as before is 4.4.
In order to experiment the IOMMU we start a VM with vIOMMU, following is the command line:
gdb --args x86_64-softmmu/qemu-system-x86_64 -machine q35,accel=kvm,kernel-irqchip=split -m 1G -device intel-iommu -hda ~/test.img
In order to enable the intel-iommu we need to add ‘intel_iommu=on” argument to the kernel command line.
This post will contains following five part:
- intel-iommu initialization
- DMAR table parsing
- DMAR initialization
- Add device to iommu group
- DMA operation without and with IOMMU
intel-iommu initialization
The bios is responsible for detecting the remapping hardware functions and it reports the remapping hardware units through the DMA Remapping Reporting(DMAR) ACPI table. DMAR ACPI table’s format is defined in VT-d spec 8.1. Just in a summary, DMAR ACPI table contains one DMAR remapping reporting structure and several remapping structures. qemu creates this DMAR ACPI table data in function ‘build_dmar_q35’.
‘DMAR remapping reporting structure’ contains a standard ACPI table header with some specific data for ‘DMAR’. There are several kinds of ‘Remapping Structure Types’. The type ‘0’ is DMA Remapping Hardware Unit(DRHD) structure, this is the most important structure. A DRHD structure represents a remapping hardware unit present in the platform. Following figure shows the format of DRHD.
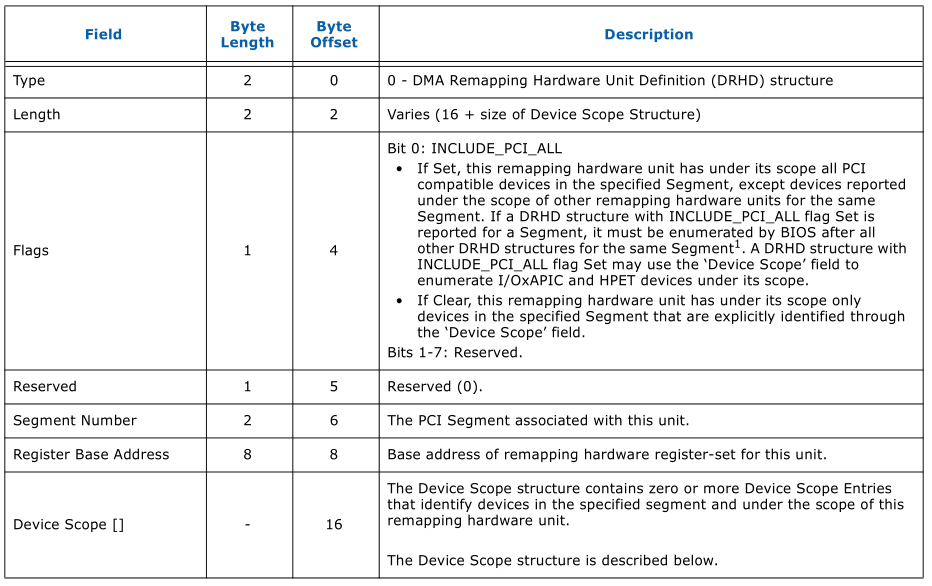
Here the ‘Segment Number ‘ is the PCI Segment associated with this unit, PCI Segment is for the sever which needs a lot of PCI bus, it has one more PCI root bridge, every tree of this PCI root bridge is a PCI Domain/Segment. The ‘Flags’ currently only only has one valid bit. If ‘INCLUDE_PCI_ALL’ is set, it means the intel-iommu represented by this DRHD will control the PCI compatible devices, except devices reported under the scope of other DHRD. The ‘Device Scope[]’ contains zero or more Device Scope Entries, each Device Scope Entry can be used to indicate a PCI endport device that will be controlled in this DRHD. If the iommu support interrupt remapping capability, each IOxAPIC in the platform reported by MADT ACPI table must be explicity enumerated under the Device Scope of the appropriate remapping hardware uinits. In ‘build_dmar_q35’ function, qemu only creates one DRHD with a ‘IOAPIC’ device scope entry. If the ‘device-iotlb’ is suppported, there also a ‘Root Port ATS Capability Reporting (ATSR) Structure’.
For “intel_iommu=” parameter, kernel handles it using ‘intel_iommu_setup’ function. For “intel_iommu=on”, the ‘dmar_disabled’ will be set to 0. In kernel function ‘detect_intel_iommu’, it will detect the intel-iommu device. It calls ‘dmar_table_detect’ to map the DMAR ACPI table to kernel and use ‘dmar_tbl’ point it, then it walks the table with ‘dmar_res_callback’. There only a ‘dmar_validate_one_drhd’ for DRHD table. ‘dmar_validate_one_drhd’ will return 0 if the DRHD is valid. So finally the ‘iommu_detected’ will be set to 1 and ‘x86_init.iommu.iommu_init’ will be set to ‘intel_iommu_init’.
Later in ‘pci_iommu_init’, the ‘iommu_init’ callback will be called. ‘intel_iommu_init’ will be used to initialized the intel-iommu device.
int __init intel_iommu_init(void)
{
int ret = -ENODEV;
struct dmar_drhd_unit *drhd;
struct intel_iommu *iommu;
/* VT-d is required for a TXT/tboot launch, so enforce that */
force_on = tboot_force_iommu();
if (iommu_init_mempool()) {
if (force_on)
panic("tboot: Failed to initialize iommu memory\n");
return -ENOMEM;
}
down_write(&dmar_global_lock);
if (dmar_table_init()) {
if (force_on)
panic("tboot: Failed to initialize DMAR table\n");
goto out_free_dmar;
}
if (dmar_dev_scope_init() < 0) {
if (force_on)
panic("tboot: Failed to initialize DMAR device scope\n");
goto out_free_dmar;
}
...
if (dmar_init_reserved_ranges()) {
if (force_on)
panic("tboot: Failed to reserve iommu ranges\n");
goto out_free_reserved_range;
}
init_no_remapping_devices();
ret = init_dmars();
...
up_write(&dmar_global_lock);
pr_info("Intel(R) Virtualization Technology for Directed I/O\n");
init_timer(&unmap_timer);
#ifdef CONFIG_SWIOTLB
swiotlb = 0;
#endif
dma_ops = &intel_dma_ops;
init_iommu_pm_ops();
for_each_active_iommu(iommu, drhd)
iommu->iommu_dev = iommu_device_create(NULL, iommu,
intel_iommu_groups,
"%s", iommu->name);
bus_set_iommu(&pci_bus_type, &intel_iommu_ops);
bus_register_notifier(&pci_bus_type, &device_nb);
if (si_domain && !hw_pass_through)
register_memory_notifier(&intel_iommu_memory_nb);
intel_iommu_enabled = 1;
return 0;
...
}
‘iommu_init_mempool’ is used to create some caches. ‘dmar_table_init’ is used to parse the dmar table. ‘dmar_dev_scope_init’ does some initialization for the ‘Device Scope’ in DRHD. ‘dmar_init_reserved_ranges’ reserves all PCI MMIO adress to avoid peer-to-peer access. As the name indicating, ‘init_no_remapping_devices’ initializes the no mapping devices. ‘init_dmars’ is an important function, later I will use one section to analysis this. For every iommu device, iommu_device_create creates a sysfs device. ‘bus_set_iommu’ is used to add current PCI device to the appropriated iommu group and also register notifier to get the device add notification.
DMAR table parsing
‘intel_iommu_init’ calls ‘dmar_table_init’ which calls ‘parse_dmar_table’ to do the DMAR table parsing. ‘parse_dmar_table’ prepares a ‘dmar_res_callback’ struct which contains handlers of the every kind of the ‘Remapping structure’. Then ‘dmar_table_detect’ is called again to map the DMAR ACPI table to ‘dmar_tbl’. Later ‘dmar_walk_dmar_table’ is called with the ‘dma_rs_callback’ to walk the dmar_tbl and calls the correspoding remapping structure. For our qemu case, only a DHRD is used, the handler is ‘dmar_parse_one_drhd’.
The ‘dma_parse_one_drhd’ parses the DMAR table and creates a ‘dmar_drhd_unit’ struct, this struct is defined as follows:
struct dmar_drhd_unit {
struct list_head list; /* list of drhd units */
struct acpi_dmar_header *hdr; /* ACPI header */
u64 reg_base_addr; /* register base address*/
struct dmar_dev_scope *devices;/* target device array */
int devices_cnt; /* target device count */
u16 segment; /* PCI domain */
u8 ignored:1; /* ignore drhd */
u8 include_all:1;
struct intel_iommu *iommu;
};
Most of the field is explained by the comment, the ‘iommu’ is allocated and initialized by ‘alloc_iommu’ function. ‘alloc_iommu’ will map the MMIO of iommu device and do some initialization work according to the BAR. In the last of ‘dma_parse_one_hrhd’ it calls ‘dmar_register_drhd_unit’ to add our new ‘dmar_drhd_unit’ to ‘dmar_drhd_units’ list. Following figure show the relation between ‘dmar_drhd_unit’ and ‘intel_iommu’.
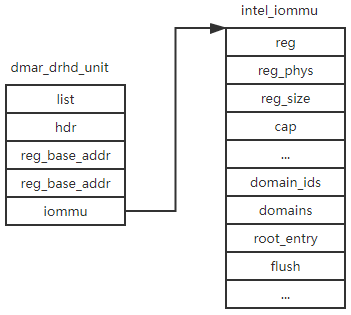
‘dmar_dev_scope_init’ is used to initialize the Decie Scope Entries in DRHD, but as our one DRHR sets the ‘INCLUDE_PCI_ALL’ flag, it actually dones nothing.
‘dmar_init_reserved_ranges’ is used to reverse the ‘IOAPIC’ and all PCI MMIO address, so that the PCI device’s DMA will not use these IOVA.
‘init_no_remapping_devices’ also does nothing as our DRHD sets the ‘INCLUDE_PCI_ALL’ flag.
DMAR initialization
So we come to the ‘init_dmars’ function.
static int __init init_dmars(void)
{
struct dmar_drhd_unit *drhd;
struct dmar_rmrr_unit *rmrr;
bool copied_tables = false;
struct device *dev;
struct intel_iommu *iommu;
int i, ret;
/*
* for each drhd
* allocate root
* initialize and program root entry to not present
* endfor
*/
for_each_drhd_unit(drhd) {
/*
* lock not needed as this is only incremented in the single
* threaded kernel __init code path all other access are read
* only
*/
if (g_num_of_iommus < DMAR_UNITS_SUPPORTED) {
g_num_of_iommus++;
continue;
}
pr_err_once("Exceeded %d IOMMUs\n", DMAR_UNITS_SUPPORTED);
}
/* Preallocate enough resources for IOMMU hot-addition */
if (g_num_of_iommus < DMAR_UNITS_SUPPORTED)
g_num_of_iommus = DMAR_UNITS_SUPPORTED;
g_iommus = kcalloc(g_num_of_iommus, sizeof(struct intel_iommu *),
GFP_KERNEL);
if (!g_iommus) {
pr_err("Allocating global iommu array failed\n");
ret = -ENOMEM;
goto error;
}
deferred_flush = kzalloc(g_num_of_iommus *
sizeof(struct deferred_flush_tables), GFP_KERNEL);
if (!deferred_flush) {
ret = -ENOMEM;
goto free_g_iommus;
}
for_each_active_iommu(iommu, drhd) {
g_iommus[iommu->seq_id] = iommu;
intel_iommu_init_qi(iommu);
ret = iommu_init_domains(iommu);
if (ret)
goto free_iommu;
init_translation_status(iommu);
if (translation_pre_enabled(iommu) && !is_kdump_kernel()) {
iommu_disable_translation(iommu);
clear_translation_pre_enabled(iommu);
pr_warn("Translation was enabled for %s but we are not in kdump mode\n",
iommu->name);
}
/*
* TBD:
* we could share the same root & context tables
* among all IOMMU's. Need to Split it later.
*/
ret = iommu_alloc_root_entry(iommu);
if (ret)
goto free_iommu;
...
}
/*
* Now that qi is enabled on all iommus, set the root entry and flush
* caches. This is required on some Intel X58 chipsets, otherwise the
* flush_context function will loop forever and the boot hangs.
*/
for_each_active_iommu(iommu, drhd) {
iommu_flush_write_buffer(iommu);
iommu_set_root_entry(iommu);
iommu->flush.flush_context(iommu, 0, 0, 0, DMA_CCMD_GLOBAL_INVL);
iommu->flush.flush_iotlb(iommu, 0, 0, 0, DMA_TLB_GLOBAL_FLUSH);
}
...
/*
* If we copied translations from a previous kernel in the kdump
* case, we can not assign the devices to domains now, as that
* would eliminate the old mappings. So skip this part and defer
* the assignment to device driver initialization time.
*/
if (copied_tables)
goto domains_done;
...
domains_done:
/*
* for each drhd
* enable fault log
* global invalidate context cache
* global invalidate iotlb
* enable translation
*/
for_each_iommu(iommu, drhd) {
if (drhd->ignored) {
/*
* we always have to disable PMRs or DMA may fail on
* this device
*/
if (force_on)
iommu_disable_protect_mem_regions(iommu);
continue;
}
iommu_flush_write_buffer(iommu);
#ifdef CONFIG_INTEL_IOMMU_SVM
if (pasid_enabled(iommu) && ecap_prs(iommu->ecap)) {
ret = intel_svm_enable_prq(iommu);
if (ret)
goto free_iommu;
}
#endif
ret = dmar_set_interrupt(iommu);
if (ret)
goto free_iommu;
if (!translation_pre_enabled(iommu))
iommu_enable_translation(iommu);
iommu_disable_protect_mem_regions(iommu);
}
return 0;
...
}
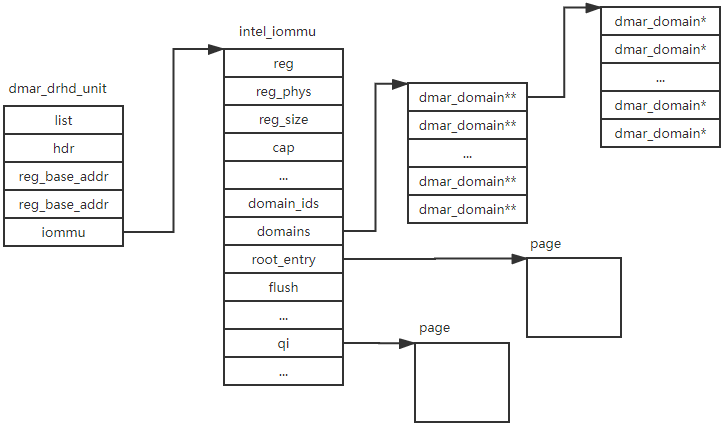
First iterate the ‘dmar_drhd_units’ and get the number of iommu device, store it in ‘g_num_of_iommus’. Allocate the space of all iommu pointer, store it in ‘g_iommus’. Then the ‘for_each_active_iommu’ loop initializes the iommu device.
In the loop, ‘intel_iommu_init_qi’ is used to initialize the queued invalidation interface, this interface is described in VT-d spec 6.5.2. ‘intel_iommu_init_qi’ allocates the queued invalidation interface’s ring buffer, store it in ‘iommu->qi’ and write the ‘iommu->qi’ physical address to iommu device’s register ‘DMAR_IQA_REG’.
Return to the loop, after the queued invalidation initialization finished, ‘iommu_init_domains’ is called to initialize the domain-related data structure. Referenced from VT-d spec: A domain is abstractly defined as an isolated environment in the platform, to which a subset of the host physical memory is allocated. I/O devices that are allowed to access physical memory directly are allocated to a domain and are referred to as the domain’s assigned devices. For virtualization usages, software may treat each virtual machine as a domain. ‘iommu_init_domains’ allocates a bitmap used for the domain id, stores it in ‘iomu->domain_ids’. A domain is represented by ‘dmar_domain’ struct. An iommu can support a lot of domain, but it may uses just a very small domain. So we can’t allocated all the ‘dmar_domain’. Instead, we uses a level allocation. ‘iommu->domains’ points an array of ‘dmar_domain**) and ‘iommu->domains[i]’ points the second level. And first we only allocates 256 ‘dmar_domin’ pointer.
In the loop, we allocates the root table by calling ‘iommu_alloc_root_entry’.
The ‘init_dmars’ then does the second ‘for_each_active_iommu’, this time it just sets root table entry’s base address by calling ‘for_each_active_iommu’.
‘init_dmars’ calls ‘iommu_prepare_isa’ to do a identity_map for the ISA bridge. Then we go to the finally loop. In the final for_each_iommu loop. It first invalidate the context cache and iotlb by calling ‘iommu_flush_write_buffer’, then request a irq to log the dma remapping fault, finally calls ‘iommu_enable_translation’ to enable the translation.
After the ‘init_dmars’, the data structure shows bellow.
Add device to iommu group
IOMMU group is the smallest sets of devices that can be considered isolated from the perspective of IOMMU. Some devices can do peer-to-peer DMA without the involvement of IOMMU, for these device, if they has different IOVA page table and do the peer-to-per DMA, it will cause errors. Alex Williamson has written a great post explaining the IOMMU group IOMMU Groups, inside and out. In ‘intel_iommu_init’, it calls ‘bus_set_iommu’ to set current PCI device to device iommu group.
‘bus_set_iommu’ is used to set iommu-callback for the bus. Following sets the pci bus’s iommu callback to intel_iommu_ops.
bus_set_iommu(&pci_bus_type, &intel_iommu_ops);
‘bus_set_iommu’ sets ‘bus->iommu_ops’ to the ‘ops’ parameter, then calls ‘iommu_bus_init’.
static int iommu_bus_init(struct bus_type *bus, const struct iommu_ops *ops)
{
int err;
struct notifier_block *nb;
struct iommu_callback_data cb = {
.ops = ops,
};
nb = kzalloc(sizeof(struct notifier_block), GFP_KERNEL);
if (!nb)
return -ENOMEM;
nb->notifier_call = iommu_bus_notifier;
err = bus_register_notifier(bus, nb);
if (err)
goto out_free;
err = bus_for_each_dev(bus, NULL, &cb, add_iommu_group);
if (err)
goto out_err;
return 0;
out_err:
/* Clean up */
bus_for_each_dev(bus, NULL, &cb, remove_iommu_group);
bus_unregister_notifier(bus, nb);
out_free:
kfree(nb);
return err;
}
‘iommu_bus_init’ registers a notifier for the bus event, this is useful for new hot-plug devices. The most work is to call ‘add_iommu_group’ for every PCI device. ‘add_iommu_group’ just calls the ‘iommu_ops’s add_device callback, it’s ‘intel_iommu_add_device’.
static int intel_iommu_add_device(struct device *dev)
{
struct intel_iommu *iommu;
struct iommu_group *group;
u8 bus, devfn;
iommu = device_to_iommu(dev, &bus, &devfn);
if (!iommu)
return -ENODEV;
iommu_device_link(iommu->iommu_dev, dev);
group = iommu_group_get_for_dev(dev);
if (IS_ERR(group))
return PTR_ERR(group);
iommu_group_put(group);
return 0;
}
First, get the ‘intel_iommu’ associated with the device ‘dev’ and also get the ‘bus’ and ‘devfn’ of the device. It’s quite easy, just get the device’s domain(segment) id and use this segment id to find the ‘intel_iommu’ in ‘dmar_drhd_units’ list.
‘iommu_device_link’ function is also trivial. Create a link file ‘iommu’ in PCI device directory to point the iommu device directory and also a ‘link’ in iommu ‘devices’ directory to point the PCI device.
The most important is ‘iommu_group_get_for_dev’, thsi function finds or creates the IOMMU group for a device.
struct iommu_group *iommu_group_get_for_dev(struct device *dev)
{
const struct iommu_ops *ops = dev->bus->iommu_ops;
struct iommu_group *group;
int ret;
group = iommu_group_get(dev);
...
if (ops && ops->device_group)
group = ops->device_group(dev);
...
ret = iommu_group_add_device(group, dev);
...
return group;
}
Device’s iommu group is stored in ‘device’ struct’s iommu_group. The ‘iommu_group_get’ returns this, if it’s not NULL, just return this group. In the first time, it is NULL, so it calls ‘iommu_ops’s device_group callback, it’s ‘pci_device_group’ for intel iommu.
‘pci_device_group’ will find or create a IOMMU group for a device. There are several cases to get a device IOMMU group from an existing device. For example, if one bridge support ACS, we need to go to the upstream bus. Also a multi-function device’s all function device need to share the same IOMMU group. If ‘pci_device_group’ can’t find a IOMMU group, it calls ‘iommu_group_alloc’ to create a new one. ‘iommu_group_alloc’ will create a number directory in ‘/sys/kernel/iommu_groups’ directory. For example, ‘/sys/kernel/iommu_groups/3’.
After get the device’s IOMMU group, ‘iommu_group_get_for_dev’ calls ‘iommu_group_add_device’ to add the device to the IOMMU group. First create a ‘iommu_group’ link pointing the ‘/sys/kernel/iommu_groups/$group_id’ in the PCI device’s directory. Then it creates a link in ‘/sys/kernel/iommu_groups/$group_id/devices/0000:$pci_bdf” to point the PCI device. Set the device’s iommu_group to ‘group’ and add the deivce to the ‘group->devices’ list.
A lot of function, let’s wrap it up.
intel_iommu_init ->bus_set_iommu ->iommu_bus_init -> add_iommu_group(For each PCI device calls ‘add_iommu_group’) ->iommu_ops->add_device(intel_iommu_add_device) ->device_to_iommu ->iommu_device_link ->iommu_group_get_for_dev ->iommu_ops->device_group(pci_device_group) ->iommu_group_alloc ->iommu_group_add_device
DMA operation without and with IOMMU
Now the IOMMU has been initialized, what’s the difference between with and without IOMMU when devices do DMA. This part I will do some analysis, but not cover all of the detail of DMA.
Device uses ‘dma_alloc_coherent’ function to allocates physical memory to do DMA operation. It returns the virtual address and the DMA physical address is returned in the third argument. ‘dma_alloc_coherent’ will call ‘dma_ops->alloc’. ‘dma_ops’ is set to ‘intel_dma_ops’ in ‘intel_iomu_init’, for intel iommu this callback is ‘intel_alloc_coherent’.
static void *intel_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t flags,
struct dma_attrs *attrs)
{
struct page *page = NULL;
int order;
size = PAGE_ALIGN(size);
order = get_order(size);
if (!iommu_no_mapping(dev))
flags &= ~(GFP_DMA | GFP_DMA32);
else if (dev->coherent_dma_mask < dma_get_required_mask(dev)) {
if (dev->coherent_dma_mask < DMA_BIT_MASK(32))
flags |= GFP_DMA;
else
flags |= GFP_DMA32;
}
if (gfpflags_allow_blocking(flags)) {
unsigned int count = size >> PAGE_SHIFT;
page = dma_alloc_from_contiguous(dev, count, order);
if (page && iommu_no_mapping(dev) &&
page_to_phys(page) + size > dev->coherent_dma_mask) {
dma_release_from_contiguous(dev, page, count);
page = NULL;
}
}
if (!page)
page = alloc_pages(flags, order);
if (!page)
return NULL;
memset(page_address(page), 0, size);
*dma_handle = __intel_map_single(dev, page_to_phys(page), size,
DMA_BIDIRECTIONAL,
dev->coherent_dma_mask);
if (*dma_handle)
return page_address(page);
if (!dma_release_from_contiguous(dev, page, size >> PAGE_SHIFT))
__free_pages(page, order);
return NULL;
}
First allocates the memory needed(by calling ‘dma_alloc_from_contiguous’ or just ‘alloc_pages’) then canlls ‘__intel_map_single’ to do the memmory map.
static dma_addr_t __intel_map_single(struct device *dev, phys_addr_t paddr,
size_t size, int dir, u64 dma_mask)
{
struct dmar_domain *domain;
phys_addr_t start_paddr;
struct iova *iova;
int prot = 0;
int ret;
struct intel_iommu *iommu;
unsigned long paddr_pfn = paddr >> PAGE_SHIFT;
...
domain = get_valid_domain_for_dev(dev);
if (!domain)
return 0;
iommu = domain_get_iommu(domain);
size = aligned_nrpages(paddr, size);
iova = intel_alloc_iova(dev, domain, dma_to_mm_pfn(size), dma_mask);
if (!iova)
goto error;
...
ret = domain_pfn_mapping(domain, mm_to_dma_pfn(iova->pfn_lo),
mm_to_dma_pfn(paddr_pfn), size, prot);
...
start_paddr = (phys_addr_t)iova->pfn_lo << PAGE_SHIFT;
start_paddr += paddr & ~PAGE_MASK;
return start_paddr;
...
}
The skeleton of ‘__intel_map_single’ is showed above. First get/create a domain by calling ‘get_valid_domain_for_dev’, then allocates the IOVA by calling ‘intel_alloc_iova’, finally do the IOVA->physical address mapping by calling ‘domain_pfn_mapping’. The IOVA is returned.
As the domain’s definition indicates, if the system will allocate physical memory to a device, a domain need to be bind to this physical memory. A domain is defined using ‘get_domain_for_dev’ structure.
struct dmar_domain {
int nid; /* node id */
unsigned iommu_refcnt[DMAR_UNITS_SUPPORTED];
/* Refcount of devices per iommu */
u16 iommu_did[DMAR_UNITS_SUPPORTED];
/* Domain ids per IOMMU. Use u16 since
* domain ids are 16 bit wide according
* to VT-d spec, section 9.3 */
struct list_head devices; /* all devices' list */
struct iova_domain iovad; /* iova's that belong to this domain */
struct dma_pte *pgd; /* virtual address */
int gaw; /* max guest address width */
/* adjusted guest address width, 0 is level 2 30-bit */
int agaw;
int flags; /* flags to find out type of domain */
int iommu_coherency;/* indicate coherency of iommu access */
int iommu_snooping; /* indicate snooping control feature*/
int iommu_count; /* reference count of iommu */
int iommu_superpage;/* Level of superpages supported:
0 == 4KiB (no superpages), 1 == 2MiB,
2 == 1GiB, 3 == 512GiB, 4 == 1TiB */
u64 max_addr; /* maximum mapped address */
struct iommu_domain domain; /* generic domain data structure for
iommu core */
};
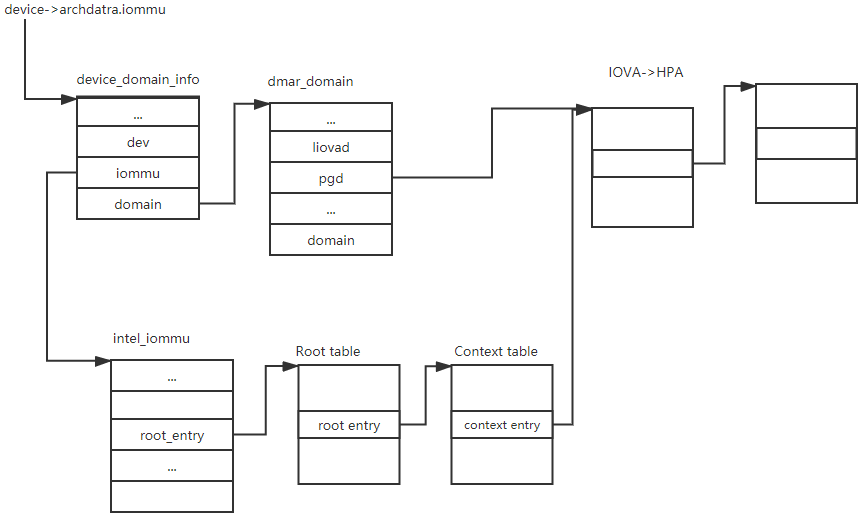
‘iovad’ contains a rb-tree to hold all of the IOVA for the domain. ‘pgd’ is the page table directory which is for the iova->physical address. ‘domain’ contains the generic domain data structure. domain is allocated in ‘get_domain_for_dev’.
In ‘get_domain_for_dev’, domain is allocated by calling ‘alloc_domain’ and initialized by calling ‘domain_init’. In ‘domain_init’, ‘init_iova_domain’ is used to init the ‘iovad’ memory to set the start pfn of IOVA to 1 and end pfn of IOVA to 4G. ‘domain_reserve_special_ranges’ is uesd to reverse the special physical memory in ‘reserved_iova_list’ this means the IOVA can’t be one the address in this list. ‘alloc_pgtable_page’ allocates a page table as the page table directory, store it in ‘domain->gpd’.
In ‘get_domain_for_dev’, ‘dmar_insert_one_dev_info’ is called to allocated a ‘device_domain_info’ and stored it in ‘device’s archdata.iommu field. In the end of ‘dmar_insert_one_dev_info’, there is an important step to call ‘domain_context_mapping’. ‘domain_context_mapping’ calls ‘domain_context_mapping_one’ to setup the IOMMU DAM remapping page table. In ‘domain_context_mapping_one’, ‘iommu_context_addr’ is called to get the context entry in context table, then ‘context_set_address_root’ is called to set the context entry’s to the domain’s pgd physical address.
After geting/creating the domain, ‘__intel_map_single’ calls ‘intel_alloc_iova’ to allocates the requested size of IOVA range in this domain. Then calling ‘domain_pfn_mapping’ to setup the mapping. ‘__domain_mapping’ is doing the actual work.
In ‘__domain_mapping’, ‘pfn_to_dma_pte’ will allocate the not-present pte and set it to according the IOVA address. After ‘__domain_mapping’, we has a page table which translate the IOVA to physical address.
Following figure shows the data structure relation.
With the iommu, we can the the dma address is 0xffffxxxx, and the host physical address is 0x384f2000.
(gdb) b vtd_iommu_translate
Breakpoint 2 at 0x5555572724f2: file /home/test/qemu5/qemu/hw/i386/intel_iommu.c, line 2882.
(gdb) c
Continuing.
Thread 1 "qemu-system-x86" hit Breakpoint 2, vtd_iommu_translate (iommu=0x61a000019ef0, addr=4294951088, flag=IOMMU_WO, iommu_idx=0) at /home/test/qemu5/qemu/hw/i386/intel_iommu.c:2882
2882 {
(gdb) finish
Run till exit from #0 vtd_iommu_translate (iommu=0x61a000019ef0, addr=4294951088, flag=IOMMU_WO, iommu_idx=0) at /home/test/qemu5/qemu/hw/i386/intel_iommu.c:2882
address_space_translate_iommu (iommu_mr=0x61a000019ef0, xlat=0x7fffffffc420, plen_out=0x7fffffffc3e0, page_mask_out=0x0, is_write=true, is_mmio=true, target_as=0x7fffffffc290, attrs=...) at /home/test/qemu5/qemu/exec.c:493
493 if (!(iotlb.perm & (1 << is_write))) {
Value returned is $5 = {target_as = 0x55555ad79380 <address_space_memory>, iova = 4294950912, translated_addr = 944709632, addr_mask = 4095, perm = IOMMU_RW}
(gdb) p /x $5
$6 = {target_as = 0x55555ad79380, iova = 0xffffc000, translated_addr = 0x384f2000, addr_mask = 0xfff, perm = 0x3}
Without the iommu, we can see the dma address is just the host physical address.
Thread 4 "qemu-system-x86" hit Breakpoint 1, pci_dma_write (dev=0x7fffa3eba800, addr=946098204, buf=0x7fffe4ba6bbc, len=4) at /home/test/qemu5/qemu/include/hw/pci/pci.h:795
795 return pci_dma_rw(dev, addr, (void *) buf, len, DMA_DIRECTION_FROM_DEVICE);
(gdb) p /x addr
$1 = 0x3864501c
(gdb)
blog comments powered by Disqus