Deploy a 'hello world' model serving using triton server without GPU
The first is reproduced and modified from here. This uses fashion mnist dataset.
The second is made by my own. This uses the mnist dataset.
Deploy a fashion-mnist model serving
train the model
This train uses CPU.
# python train.py --epoch 60
import argparse
import time
import torch
import torchvision
from torch import nn
##device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = torch.device('cpu')
# 加载数据
def load_data_fashion_mnist(batch_size, resize=None, root='data'):
"""Download the fashion mnist dataset and then load into memory."""
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
# 图像增强
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False)
return train_iter, test_iter
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return nn.functional.avg_pool2d(x, kernel_size=x.size()[2:])
class FlattenLayer(nn.Module): #展平操作
def forward(self, x):
return x.view(x.shape[0], -1)
# 定义模型结构
def model(show_shape=False) -> nn.modules.Sequential:
# torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。
model = nn.Sequential()
model.add_module('convd1', nn.Sequential(
nn.Conv2d(1, 25, kernel_size=3),
nn.BatchNorm2d(25),
nn.ReLU(),
))
model.add_module('maxpool1', nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
))
model.add_module('convd2', nn.Sequential(
nn.Conv2d(25, 50, kernel_size=3),
nn.BatchNorm2d(50),
nn.ReLU(),
))
model.add_module('maxpool2', nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2)
))
model.add_module('fc', nn.Sequential(
FlattenLayer(),
nn.Linear(50*5*5, 1024),
nn.ReLU(),
nn.Linear(1024, 128),
nn.ReLU(),
nn.Linear(128, 10),
))
if show_shape:
print(model)
print('打印 1*1*28*28 输入经过每个模块后的shape')
X = torch.rand((1, 1, 28, 28))
for name, layer in model.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)
return model
# 评估函数
def evaluate_accuracy(data_iter, net, device=torch.device('cpu')):
"""Evaluate accuracy of a model on the given data set."""
acc_sum, n = torch.tensor([0], dtype=torch.float32, device=device), 0
for X, y in data_iter:
# If device is the GPU, copy the data to the GPU.
X, y = X.to(device), y.to(device)
net.eval()
with torch.no_grad():
y = y.long()
# [[0.2 ,0.4 ,0.5 ,0.6 ,0.8] ,[ 0.1,0.2 ,0.4 ,0.3 ,0.1]] => [ 4 , 2 ]
acc_sum += torch.sum((torch.argmax(net(X), dim=1) == y))
n += y.shape[0]
return acc_sum.item() / n
# 训练启动入口
def train_ch(net, model_path, train_iter, test_iter, criterion, num_epochs, device, lr=None):
"""Train and evaluate a model with CPU or GPU."""
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4) # 优化函数
best_test_acc = 0
for epoch in range(num_epochs):
train_l_sum = torch.tensor([0.0], dtype=torch.float32, device=device)
train_acc_sum = torch.tensor([0.0], dtype=torch.float32, device=device)
n, start = 0, time.time()
for X, y in train_iter:
net.train()
optimizer.zero_grad() # 清空梯度
X, y = X.to(device), y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
with torch.no_grad():
y = y.long()
train_l_sum += loss.float()
train_acc_sum += (torch.sum((torch.argmax(y_hat, dim=1) == y))).float()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net, device) # 测试验证集
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc, time.time() - start))
if test_acc > best_test_acc:
print('find best! save at %s' % model_path)
best_test_acc = test_acc
# 一般情况下是用该方式保存模型
# torch.save(net, model_path)
# 本实验将模型保存成 torchscript
traced_script = torch.jit.script(net)
traced_script.save(model_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser(prog='minist',description='训练脚本')
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument('--lr', type=float, default=0.0001)
parser.add_argument('--epoch', type=int, default=1)
parser.add_argument('--batch', type=int, default=256)
parser.add_argument('--model_path', type=str, default='model.pt')
args = parser.parse_args()
lr, num_epochs = args.lr, args.epoch
device = args.device
batch = args.batch
path = args.model_path
criterion = nn.CrossEntropyLoss()
train_iter, test_iter = load_data_fashion_mnist(batch)
net = model()
train_ch(net, path, train_iter, test_iter, criterion, num_epochs, device, lr)
deploy in triton server
prepare triton model file
We need prepare a directory for triton server.
model_repository/
-- model_pt
| -- 1/
| | -- model.pt
| -- config.pbtxt
The ‘model.pt’ is the file we saved in train phase. The ‘config.pbtxt’ is as follows.
name: "model_pt" # 模型名,也是目录名
platform: "pytorch_libtorch" # 模型对应的平台,本次使用的是torch,不同格式的对应的平台可以在官方文档找到
#backend: "torch" # 此次 backend 和上面的 platform,至少写一个,用途一致tensorrt/onnxruntime/pytorch/tensorflow
input [
{
name: "input0" # 输入名字
data_type: TYPE_FP32 # 类型,torch.long对应的就是int64, 不同语言的tensor类型与triton类型的对应关系可以在官方文档找到
dims: [ -1, 1, 28, 28 ] # -1 代表是可变维度
}
]
output [
{
name: "output0" # 输出名字
data_type: TYPE_FP32
dims: [ -1, 10 ]
}
]
instance_group [
{
kind: KIND_CPU # 指定运行平台
}
]
The ‘dims’ in ‘input’ and ‘output’ is the dimension of input tensor and output tensor.
start triton server
# step 1: download tritonserver
docker pull ngc.nju.edu.cn/nvidia/tritonserver:24.12-py3
# step 2: create model repository
mkdir model_repository
# step 3: prepare file
cd model_repository
mkdir 1
cp ~/model.pt 1/
cp ~/config.pbtxt .
# step 4: run triton server
docker run --name tritonserver --rm -it -p 8000:8000 -p 8002:8002 -v $PWD/model_repository:/models ngc.nju.edu.cn/nvidia/tritonserver:24.12-py3 bash
tritonserver --model-repository=/models
If we start triton server successfully we will see following output.
I0405 11:46:43.713902 379 grpc_server.cc:2558] "Started GRPCInferenceService at 0.0.0.0:8001"
I0405 11:46:43.714439 379 http_server.cc:4725] "Started HTTPService at 0.0.0.0:8000"
I0405 11:46:43.756857 379 http_server.cc:358] "Started Metrics Service at 0.0.0.0:8002"
send request to triton server
calculate the accuracy
Just as the origin post, we create a script to calculate the accuracy.
import time
import torch
import torchvision
import requests
# 省略,和前面一样
def load_data_fashion_mnist(batch_size, resize=None, root='data'):
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
# 图像增强
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False)
return train_iter, test_iter
device = torch.device('cpu')
triton_host = 'http://192.168.0.118:8000/v2/models/model_pt/versions/1/infer'
def infer(imgs: torch.Tensor):
data = imgs.tolist()
request_data = {
"inputs": [{
"name": "input0",
"shape": [len(data), 1, 28, 28],
"datatype": "FP32",
"data": data,
}],
"outputs": [{
"name": "output0",
}]
}
res = requests.post(url=triton_host,json=request_data).json()
output_data = res['outputs'][0]['data']
n = 10
# 将子列表组成二维数组
result = [output_data[i:i+n] for i in range(0, len(output_data), n)]
return torch.tensor(result, device='cpu')
# 测试模型
correct = 0
total = 0
_, test_iter = load_data_fashion_mnist(128)
start_time = time.time()
with torch.no_grad():
for imgs, labels in test_iter:
# 将输入数据移动到正确的设备
imgs, labels = imgs.to(device), labels.to(device)
outputs = infer(imgs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
end_time = time.time()
# 打印准确率
accuracy = 100 * correct / total
print(f'总数:{total:d} 准确率: {accuracy:.2f}%')
print(f"耗时: {(end_time - start_time):.2f}s")

classcify one picture
First convert the ubyte file to image.
import os
from skimage import io
import torchvision
import torchvision.datasets.mnist as mnist
root="fashion_mnist"
train_set = (
mnist.read_image_file(os.path.join(root, 'train-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 'train-labels-idx1-ubyte'))
)
test_set = (
mnist.read_image_file(os.path.join(root, 't10k-images-idx3-ubyte')),
mnist.read_label_file(os.path.join(root, 't10k-labels-idx1-ubyte'))
)
print("training set :",train_set[0].size())
print("test set :",test_set[0].size())
def convert_to_path(name):
# 将名称转为小写,替换特殊字符为路径安全字符
return name.lower().replace('/', '_').replace(' ', '_')
# 原始标签映射
label_mapping = {
0: 'T-shirt/top',
1: 'Trouser',
2: 'Pullover',
3: 'Dress',
4: 'Coat',
5: 'Sandal',
6: 'Shirt',
7: 'Sneaker',
8: 'Bag',
9: 'Ankle boot'
}
# 生成路径安全的字典
path_safe_mapping = {key: convert_to_path(value) for key, value in label_mapping.items()}
def convert_to_img(train=True):
if(train):
f=open(root+'train.txt','w')
data_path=root+'/train/'
if(not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(train_set[0],train_set[1])):
img_path=data_path+path_safe_mapping[int(label)] +"_"+str(i)+'.jpg'
io.imsave(img_path,img.numpy())
f.write(img_path+' '+str(label)+'\n')
f.close()
else:
f = open(root + 'test.txt', 'w')
data_path = root + '/test/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img,label) in enumerate(zip(test_set[0],test_set[1])):
img_path = data_path+ path_safe_mapping[int(label)] +"_"+str(i) + '.jpg'
io.imsave(img_path, img.numpy())
f.write(img_path + ' ' + str(label) + '\n')
f.close()
convert_to_img(True)
convert_to_img(False)
Random choice some pics.
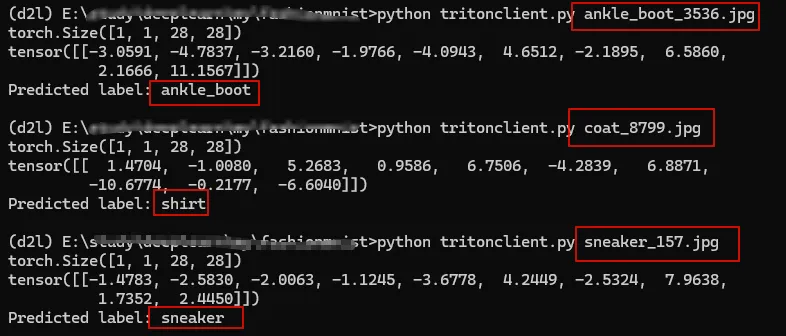
Using following code to send one picture to triton server to infer the class.
import time
import torch
import torchvision
import requests
from PIL import Image
from torch import nn,save,load
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import sys
triton_host = 'http://192.168.0.118:8000/v2/models/model_pt/versions/1/infer'
def infer(imgs: torch.Tensor):
data = imgs.tolist()
request_data = {
"inputs": [{
"name": "input0",
"shape": [len(data), 1, 28, 28],
"datatype": "FP32",
"data": data,
}],
"outputs": [{
"name": "output0",
}]
}
res = requests.post(url=triton_host,json=request_data).json()
output_data = res['outputs'][0]['data']
n = 10
# 将子列表组成二维数组
result = [output_data[i:i+n] for i in range(0, len(output_data), n)]
return torch.tensor(result, device='cpu')
def convert_to_path(name):
# 将名称转为小写,替换特殊字符为路径安全字符
return name.lower().replace('/', '_').replace(' ', '_')
# 原始标签映射
label_mapping = {
0: 'T-shirt/top',
1: 'Trouser',
2: 'Pullover',
3: 'Dress',
4: 'Coat',
5: 'Sandal',
6: 'Shirt',
7: 'Sneaker',
8: 'Bag',
9: 'Ankle boot'
}
# 生成路径安全的字典
path_safe_mapping = {key: convert_to_path(value) for key, value in label_mapping.items()}
img = Image.open(sys.argv[1])
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img).unsqueeze(0).to('cpu')
print (img_tensor.shape)
output = infer(img_tensor)
print(output)
predicted_label = torch.argmax(output)
print(f"Predicted label: {path_safe_mapping[int(predicted_label)]}")
As we can see the prediction of ‘ankel_boot’ and ‘‘sneaker’ is right but the ‘coat’ is wrong.
Deploy a mnist model serving
train the model
I using this code to do the train phase.
import torch
from torch import nn,save,load
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root="data", download=True, train=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
class ImageClassifier(nn.Module):
def __init__(self):
super(ImageClassifier, self).__init__()
self.conv_layers = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3),
nn.ReLU()
)
self.fc_layers = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 22 * 22, 10)
)
def forward(self, x):
x = self.conv_layers(x)
x = self.fc_layers(x)
return x
device = torch.device("cpu")
classifier = ImageClassifier().to('cpu')
optimizer = Adam(classifier.parameters(), lr=0.001)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(10): # Train for 10 epochs
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad() # Reset gradients
outputs = classifier(images) # Forward pass
loss = loss_fn(outputs, labels) # Compute loss
loss.backward() # Backward pass
optimizer.step() # Update weights
print(f"Epoch:{epoch} loss is {loss.item()}")
traced_script = torch.jit.script(classifier)
traced_script.save("model_state.pt")
deploy in triton server
Create a ‘model_mnist’ directory in ‘model_repository’ and create ‘1’ directory in ‘model_mnist’.

The ‘config.pbtxt’ is as follows:
name: "model_mnist" # 模型名,也是目录名
platform: "pytorch_libtorch" # 模型对应的平台,本次使用的是torch,不同格式的对应的平台可以在官方文档找到
#backend: "torch" # 此次 backend 和上面的 platform,至少写一个,用途一致tensorrt/onnxruntime/pytorch/tensorflow
input [
{
name: "input0" # 输入名字
data_type: TYPE_FP32 # 类型,torch.long对应的就是int64, 不同语言的tensor类型与triton类型的对应关系可以在官方文档找到
dims: [1, 1, 28, 28 ] # -1 代表是可变维度
}
]
output [
{
name: "output0" # 输出名字
data_type: TYPE_FP32
dims: [1, 10 ]
}
]
instance_group [
{
kind: KIND_CPU # 指定运行平台
}
]
Then start the triton server.
send request to triton server
First convert the ubyte file to image.
import numpy as np
import struct
from PIL import Image
import os
data_file = 't10k-images-idx3-ubyte' #需要修改的路径
# It's 7840016B, but we should set to 7840000B
data_file_size = 7840016
data_file_size = str(data_file_size - 16) + 'B'
data_buf = open(data_file, 'rb').read()
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', data_buf, 0)
datas = struct.unpack_from(
'>' + data_file_size, data_buf, struct.calcsize('>IIII'))
datas = np.array(datas).astype(np.uint8).reshape(
numImages, 1, numRows, numColumns)
label_file = 't10k-labels-idx1-ubyte'#需要修改的路径
# It's 10008B, but we should set to 10000B
label_file_size = 10008
label_file_size = str(label_file_size - 8) + 'B'
label_buf = open(label_file, 'rb').read()
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
labels = struct.unpack_from(
'>' + label_file_size, label_buf, struct.calcsize('>II'))
labels = np.array(labels).astype(np.int64)
datas_root = 'mnist_test' #需要修改的路径
if not os.path.exists(datas_root):
os.mkdir(datas_root)
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
file_name = datas_root + os.sep + str(label) + os.sep + \
'mnist_test_' + str(label) + "_"+str(ii) + '.png'
img.save(file_name)
Using following code to send one picture to triton server.
import time
import torch
import torchvision
import requests
from PIL import Image
from torch import nn,save,load
from torch.optim import Adam
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import sys
device = torch.device('cpu')
triton_host = 'http://192.168.0.118:8000/v2/models/model_mnist/versions/1/infer'
def infer(imgs: torch.Tensor):
data = imgs.tolist()
request_data = {
"inputs": [{
"name": "input0",
"shape": [1, 1, 28, 28],
"datatype": "FP32",
"data": data,
}],
"outputs": [{
"name": "output0",
}]
}
res = requests.post(url=triton_host,json=request_data).json()
print(res)
output_data = res['outputs'][0]['data']
n = 10
# 将子列表组成二维数组
result = [output_data[i:i+n] for i in range(0, len(output_data), n)]
return torch.tensor(result, device='cpu')
img = Image.open(sys.argv[1])
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img).unsqueeze(0).to('cpu')
print (img_tensor.shape)
output = infer(img_tensor)
print(output)
predicted_label = torch.argmax(output)
print(f"Predicted label: {predicted_label}")
As we can see all prediction is right.
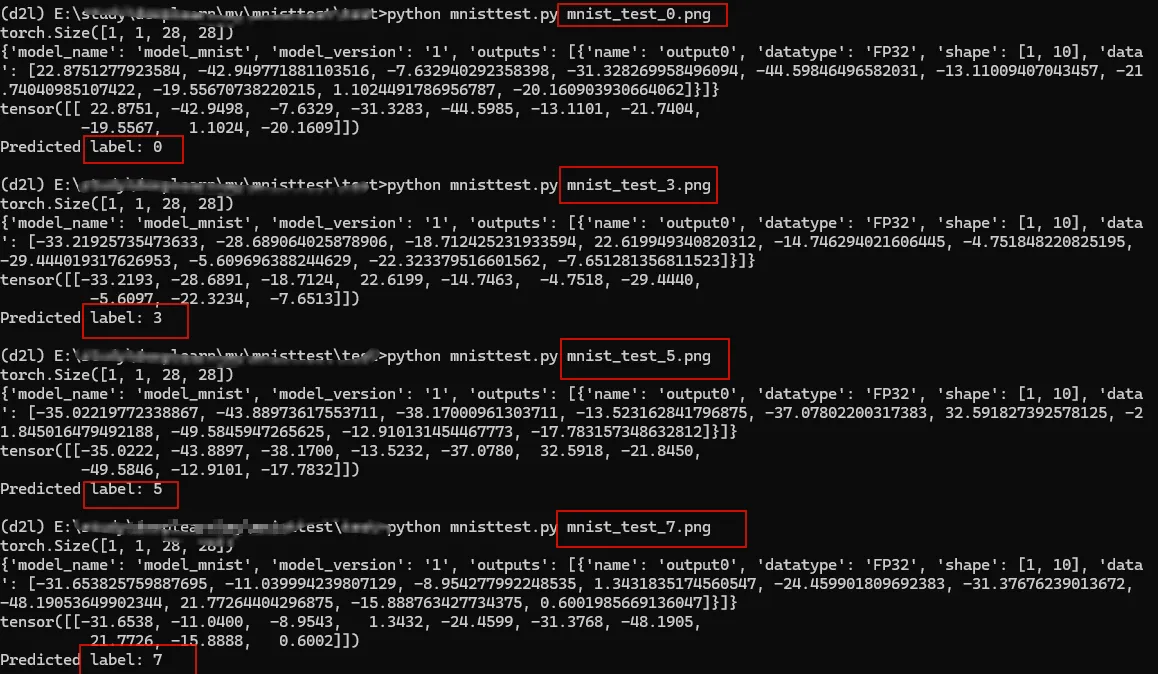
Ref
blog comments powered by Disqus