大模型是如何进行推理的?-transformer的一点代码调试分析
背景
最近在学习LLM,网上资料很多,很多都是洋洋洒洒讲了一堆原理,公式、图表一堆,这些当然很重要,但是如果能有系统性的相关代码分析与调试则更能让初学者有直观的体验。这部分不能说没有,但是也不多,并且比较零散。本文试图从transformer库的代码调试分析大模型的一次推理过程,让初学者能够理解推理的本质过程。下面的图展示了大模型一次推理的基本流程。初始的prompt输入之后,经过Tokenizer、Embeding,输入字符变成相关向量,并且经过大模型神经网络的一次forward,输出vocab size大小的tensor,每个表示该词的概率大小。最终选取概率最大的作为next token。
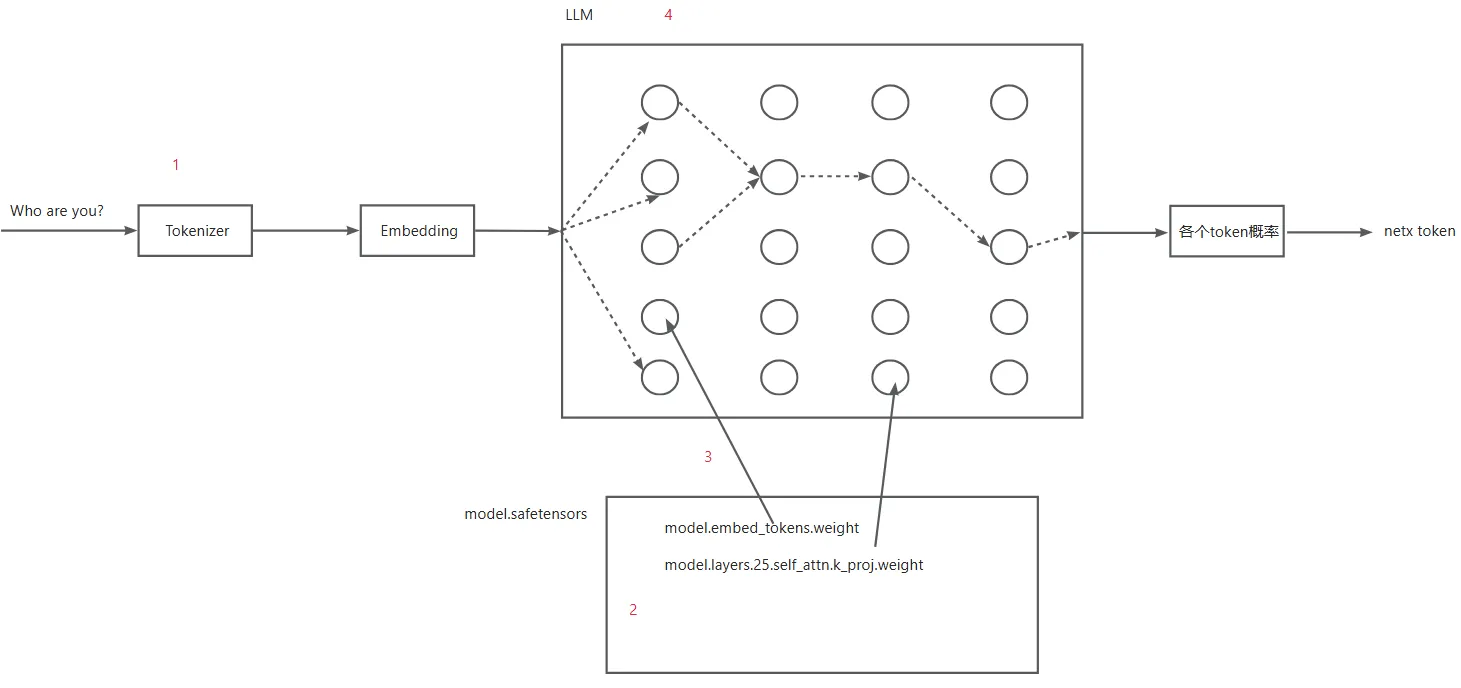
本文主要就是从代码层面分析这个流程。 具体来讲,本文包括如下部分:
- 通过transformer使用大模型。在使用过程中,我们提出下面三个问题:模型文件究竟是啥?模型文件是如何加载到模型中的?具体某个模型比如qwen模型结构分析。并在随后的部分依次解答。
- safetensors模型文件分析
- safetensors模型文件加载到模型过程分析
- 模型的整体推理过程
本文使用的大模型为 DeepSeek-R1-Distill-Qwen-1.5B,这个模型能够在CPU上跑。
通过transformer使用大模型
下面的例子用于生成字符串。从输出可以看到,是选取每一个概率最大的词。
# Load model directly
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
input_text = "who are you?"
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(input_ids=input_ids.input_ids, max_length=50, pad_token_id=tokenizer.pad_token_id)
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)

通过直接调用model,可以生成下一个最大概率的token。
# Load model directly
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
input_text = "who are you?"
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**input_ids, output_hidden_states=True)
logits = outputs.logits
# 取最后一个位置的 logits(假设是因果语言模型,预测下一个 token)
next_token_logits = logits[0, -1, :]
# 取概率最高的 token(贪心解码)
next_token_id = torch.argmax(next_token_logits).unsqueeze(0)
# 解码单个 token -> 文本
next_token_text = tokenizer.decode(next_token_id, skip_special_tokens=True)
print(f"Next predicted token: {next_token_text}")

行代码进行深入分析,探究大模型运行的过程。显然,上面代码work的过程包括:
- model参数是怎么加载的
- input经过tokenizer是如何经过网络的
- 具体的计算过程
为了理解model参数是怎么加载的,首先需要分析模型文件。
safetensors模型文件分析
模型中最大的文件是各个safetensors文件,比如下面这个,更大规模的模型甚至有几十个safetensors文件。
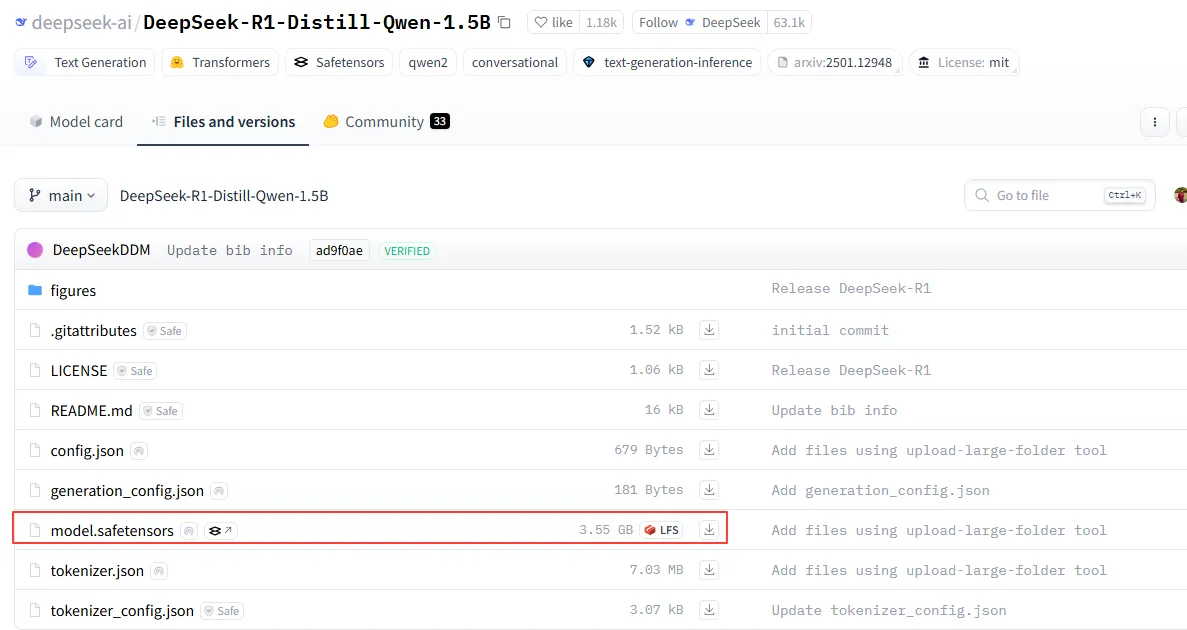
本节对safetensors文件进行详细分析。下面是一个简单的保存tensors为safetensors文件的程序。
# 安装依赖(如果未安装)
# pip install safetensors torch
import torch
from safetensors.torch import save_file
# 创建示例张量
tensor1 = torch.randn(3, 4) # 全连接层权重
tensor2 = torch.ones(3) # 偏置项
tensor3 = torch.tensor([[1.0, 2.0], [3.0, 4.0]]) # 其他张量
# 将张量组合成字典(键名可自定义)
tensors = {
"fc1.weight": tensor1,
"fc1.bias": tensor2,
"custom_tensor": tensor3
}
# 保存为 safetensors 文件
save_file(tensors, "example.safetensors")
# (可选)验证文件是否存在并可加载
from safetensors.torch import load_file
loaded_tensors = load_file("example.safetensors")
print("Loaded tensors:", loaded_tensors.keys())
直接打开 example.safetensors,safetensors文件格式如下图所示:
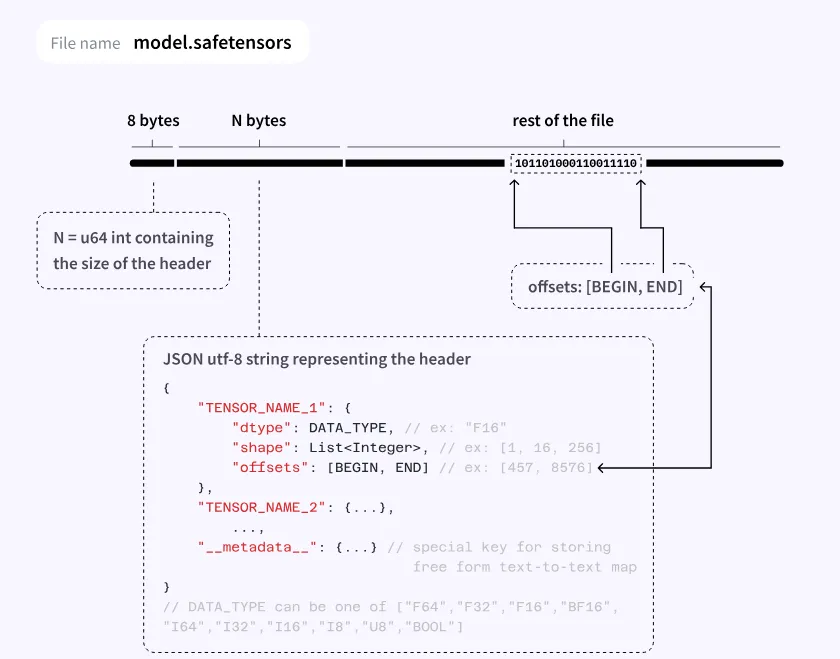
根据这个图来分析 example.safetensors。这个格式就是简单的保存tensor。

从上可以看到,这个文件header size为C8,所以从D0开始是数据段。从08开始是header,就是json,每个tensor格式如下:
{
"tensor1": {
"dtype": "F32",
"shape": [3, 3],
"data_offsets": [0, 36]
},
"tensor2": {
"dtype": "I64",
"shape": [2],
"data_offsets": [36, 52]
}
}
dtype表示数据类型,shape表示样子,data_offset表示数据在数据区的offset。比如example.safetensors中custom_tensor的offset为0-16,表示数据是从D0到DF,数据格式为F32。问问大模型,可以看到相关数据是准确的。


下面的代码打印 DeepSeek-R1-Distill-Qwen-1.5B 模型的参数。
from safetensors import safe_open
def inspect_safetensors(file_path):
with safe_open(file_path, framework="pt", device="cpu") as f:
for key in f.keys():
# 直接加载张量(内存高效,仅加载元数据)
tensor = f.get_tensor(key)
# 获取属性
dtype = tensor.dtype
shape = tensor.shape
print(f"Tensor Name: {key}, Data Type (dtype): {dtype}, Shape: {tuple(shape)}")
inspect_safetensors("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B\\model.safetensors")
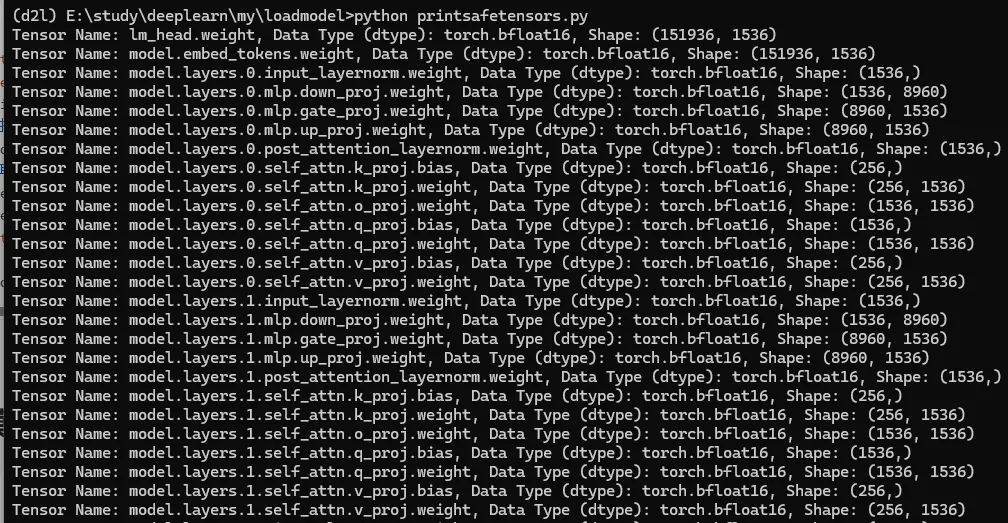
所以整个safetensors的内容就是各个tensor的值,推理的核心过程就是将这些值加入到内存或者GPU显存,然后将输入tensor进行神经网络的计算,最终得到一个tensor。
safetensors模型文件加载到模型过程分析
首先通过 print(model) 看看模型的结构。可以看到 DeepSeek-R1-Distill-Qwen-1.5B 模型的vocab大小为151936, embedding大小为1536。
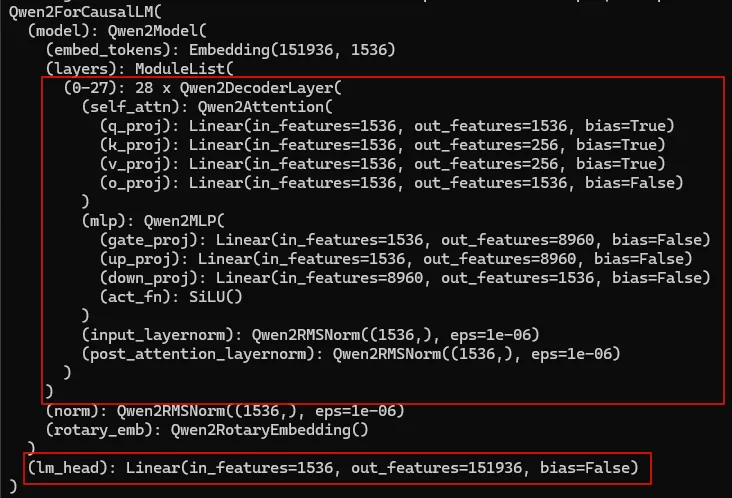
整个模型加载过程就是将safetensors中的权重加载到上面模型中。pytorch提供了保存和加载safetensors文件的方法,保存过程会保存模型的参数为一个json对象,叫做state_dict,再加载过程中则把这个state_dict加载到模型中。pytorch最终通过nn.Module.load_state_dict将模型参数加载到模型。本节梳理最开头AutoModelForCausalLM.from_pretrained与最终的nn.Module.load_state_dict的中间过程。
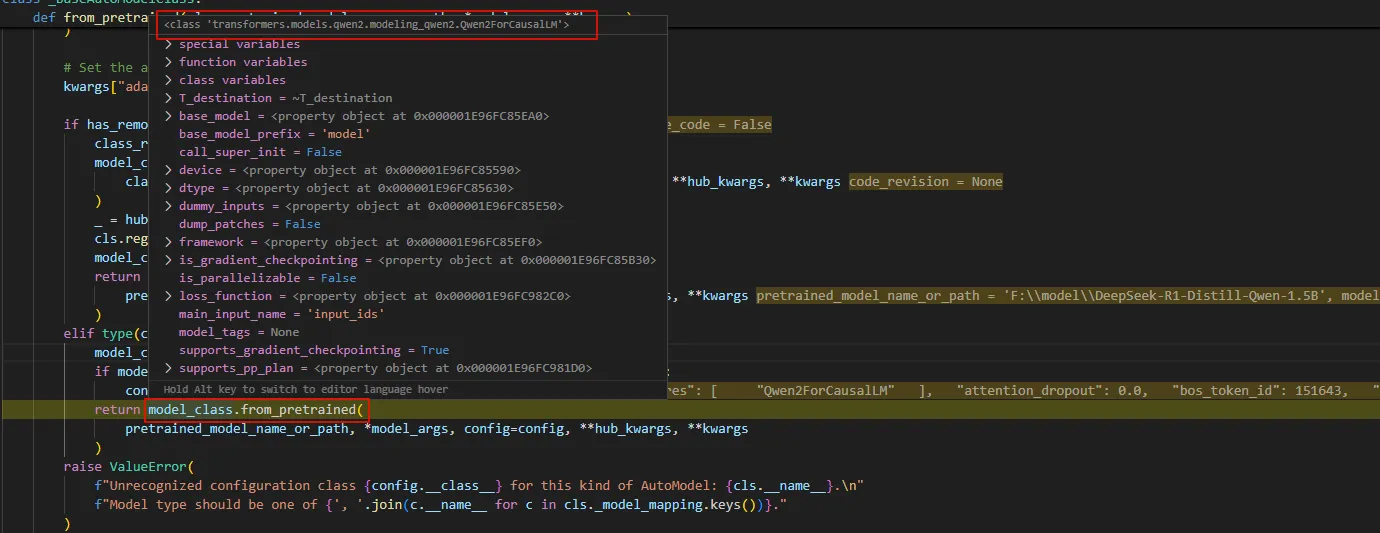
单步进入 AutoModelForCausalLM.from_pretrained 可以看到是进入了 _BaseAutoModelClass.from_pretrained,在该函数的最后,找到了model_class,并且调用其from_pretrained,从下面的调试截图可以看到该model_class是Qwen2ForCausalLM。
但是单步进去的时候,进去的是PreTrainedModel.from_pretrained,这说明Qwen2ForCausalLM是从PreTrainedModel中继承的from_pretrained。
在这个函数中继续往下走,到 cls._load_pretrained_model,这个函数_load_pretrained_model依然在PreTrainedModel中的。
_load_pretrained_model在开头不久即调用load_state_dict对safetensors文件中的权重进行加载。

在load_state_dict的return部分下个断点,可以看到模型文件的各个tensor已经加载到state_dict中。
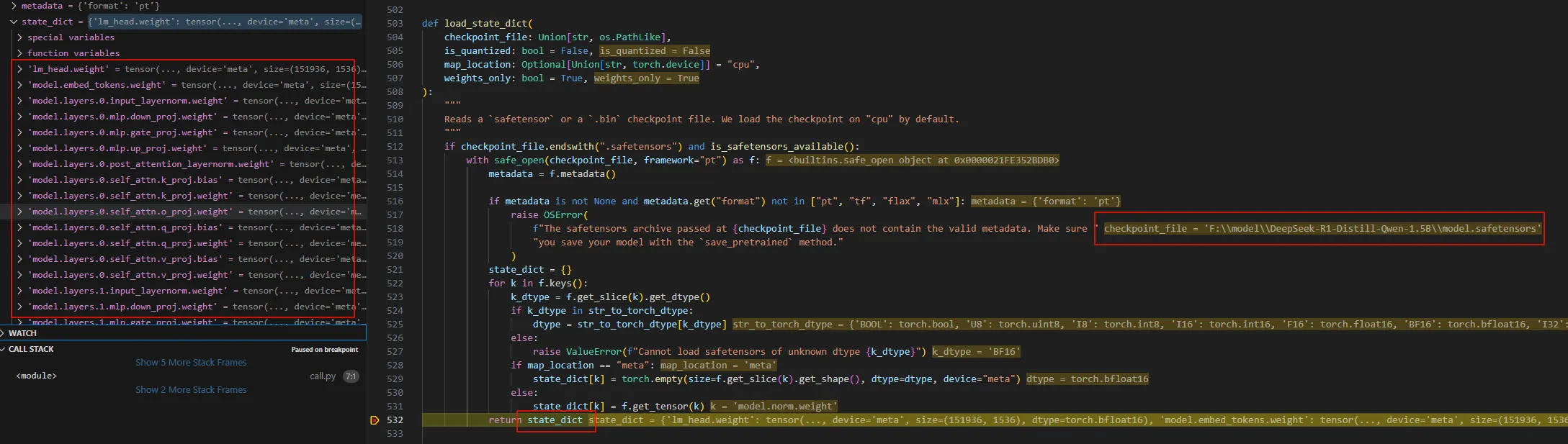
ok,此时我们已经加载文件的state_dict了,接下来是把这个state_dict加载到模型中区。代码接下来是对这个key做一些调整,暂时不看。继续在_load_pretrained_model单步调试,走到调用_load_state_dict_into_meta_model的地方。
从调用_load_state_dict_into_meta_model的地方可以看到,这个函数应该就是将将参数加到模型的地方。
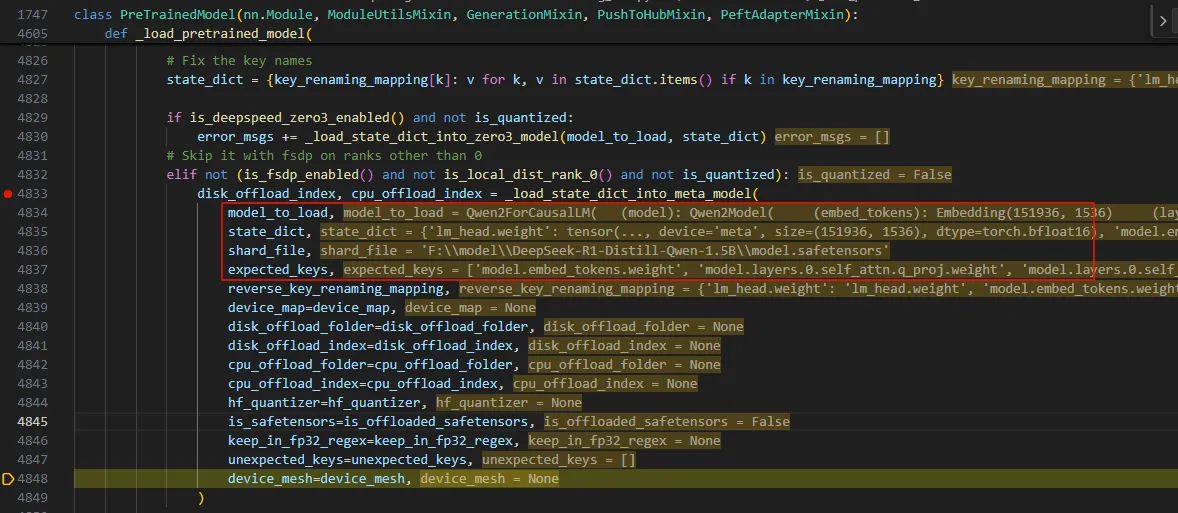
_load_state_dict_into_meta_model函数通过一个循环获取state_dict中的key, value。比如第一个参数’lm_head.weight’。
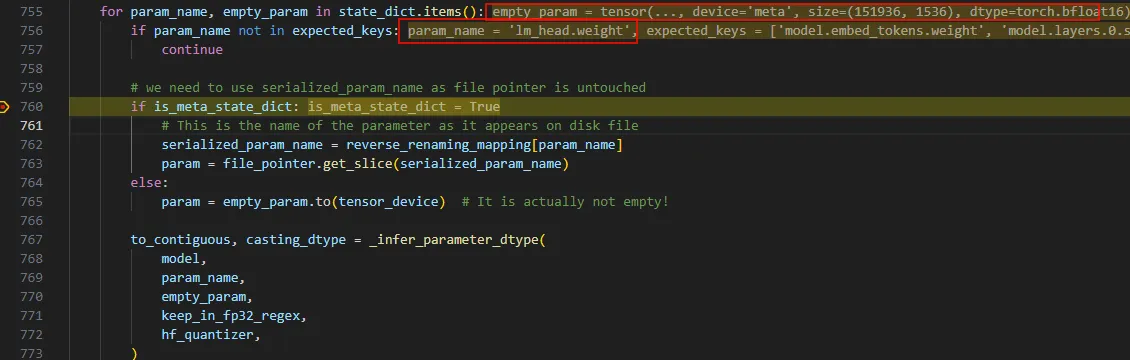
继续调试,到_load_parameter_into_model,这个函数的参数是model、param_name以及具体的param,所以应该就是将参数加载到模型的地方。果不其然,首先获取module,就是nn.Module,接着调用它的成员函数 load_state_dict。

这里稍微看看get_module_from_name是怎么工作的。可以看到前面是submodule名字。
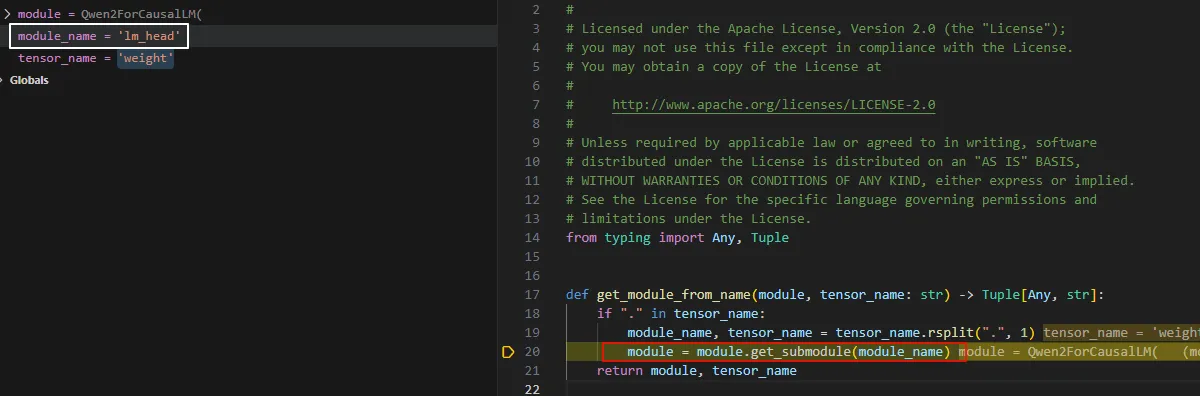
从Module.get_submodule中可以看到,返回了一个Linear的Module,这个就是 lm_head。
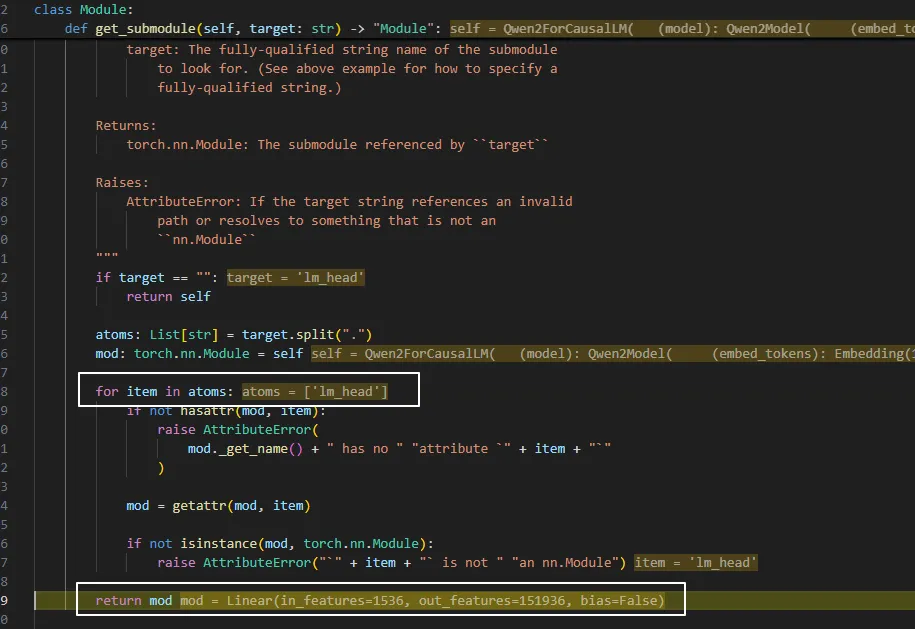
经过上面的整个过程,我们就把AutoModelForCausalLM.from_pretrained和调用nn.Module.load_state_dict联系到了一起。 整个过程简化如下:
AutoModelForCausalLM.from_pretrained
->_BaseAutoModelClass.from_pretrained
->PreTrainedModel.from_pretrained
->PreTrainedModel._load_pretrained_model
->load_state_dict(加载safetensors中的权重)
->_load_state_dict_into_meta_model
->_load_parameter_into_model
->get_module_from_name(获取nn.Module)
->module.load_state_dict(调用nn.Module.load_state_dict)
模型的整体推理过程
经过_load_state_dict_into_meta_model的循环,我们最终会把safetensors文件中的权重加载到模型中。下一步就是分析输入是如何在模型中进行forward的。
首先看tokenizer。
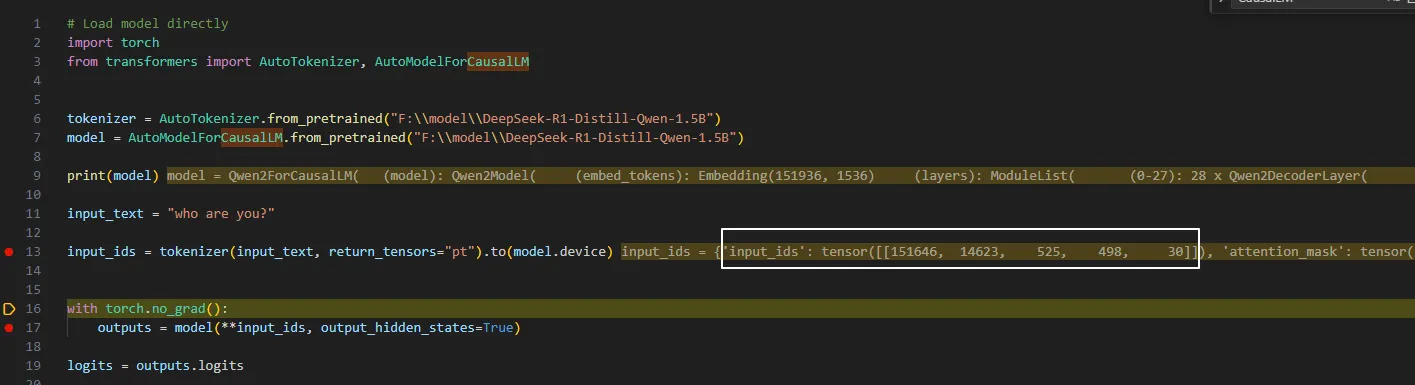
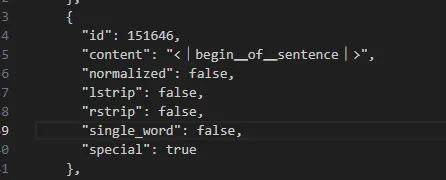
可以在模型文件的tokenizer.json中看到对应的含义。

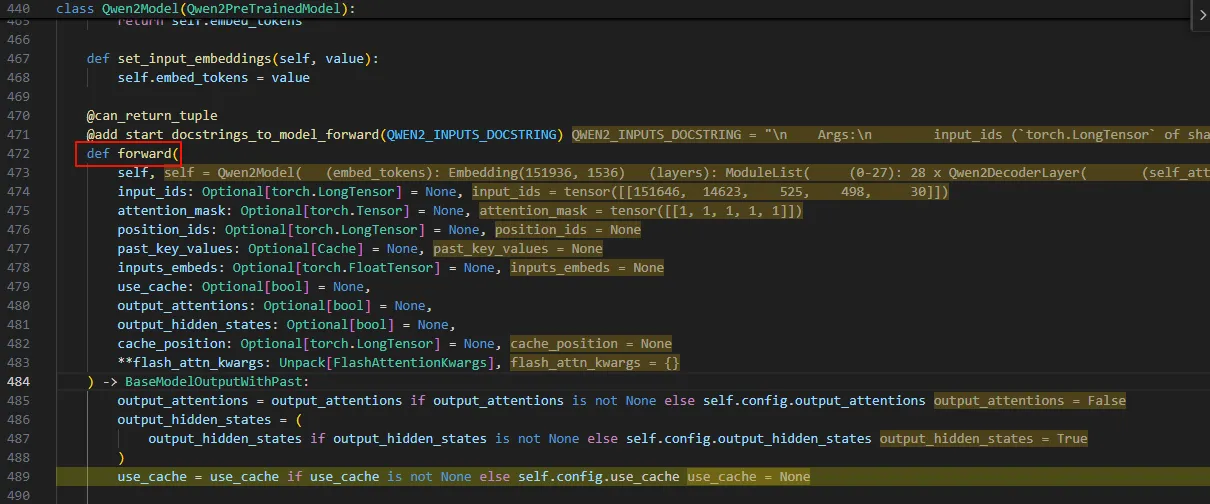
继续单步,走一次model的forward,实际走到了Qwen2Model.forward函数。
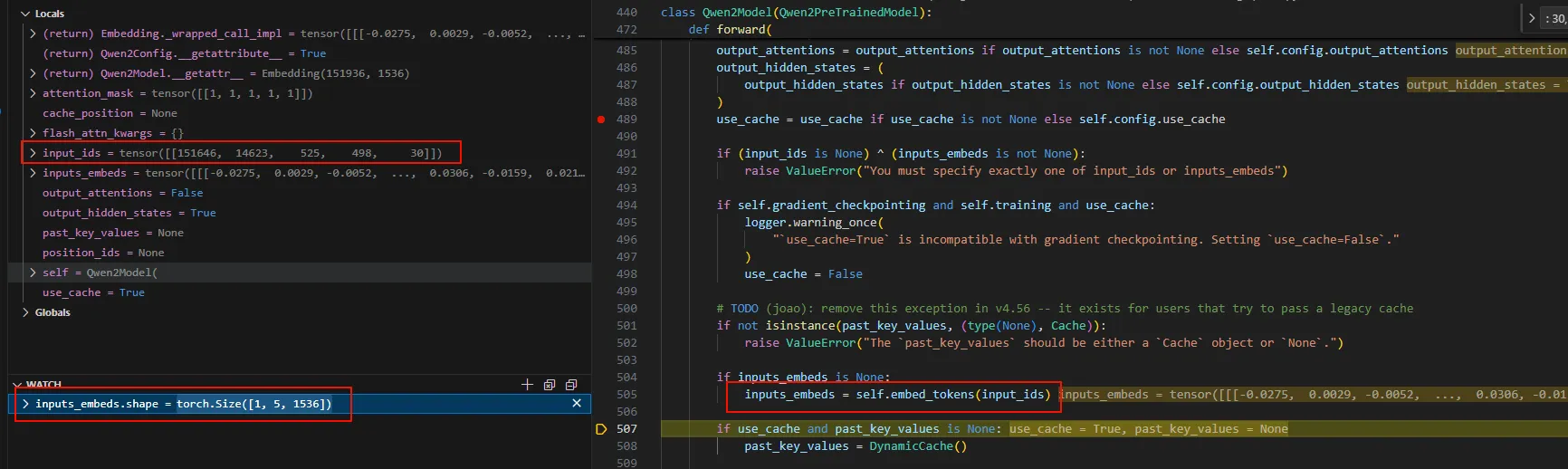
首先调用self.embed_tokens将tokenizer之后的seq进行embedding,下面的截图展示了这个过程。 可以看到seq embedding之后的inputs_embeds.shap为[1, 5, 1536],这1表示batch_size,5表示sequence length,即token数,1536是embedding维度大小。
接着进行position embedding,给seq加上位置信息。

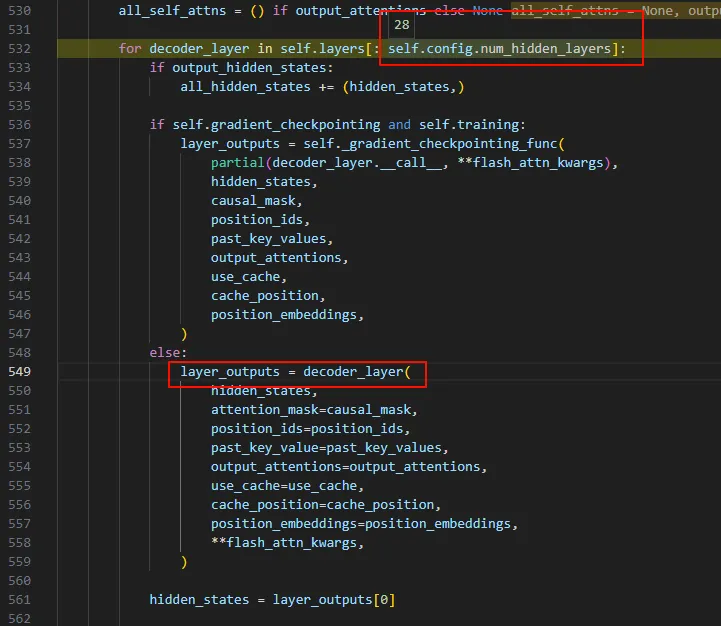
接下来在一个for循环中进入hidden layer,这个模型总共有28个hidden layer,for循环中调用decoder_layer进行输出,并且将上一层的输出(layer_outputs[0])作为下一层的输入(hidden_states)。
继续跟进decoder_layer,可以看到进入了Qwen2DecoderLayer.forward函数。这个函数就是transformer的核心部分了。比如norm层、自注意力层、残差层以及最后的全连接层。
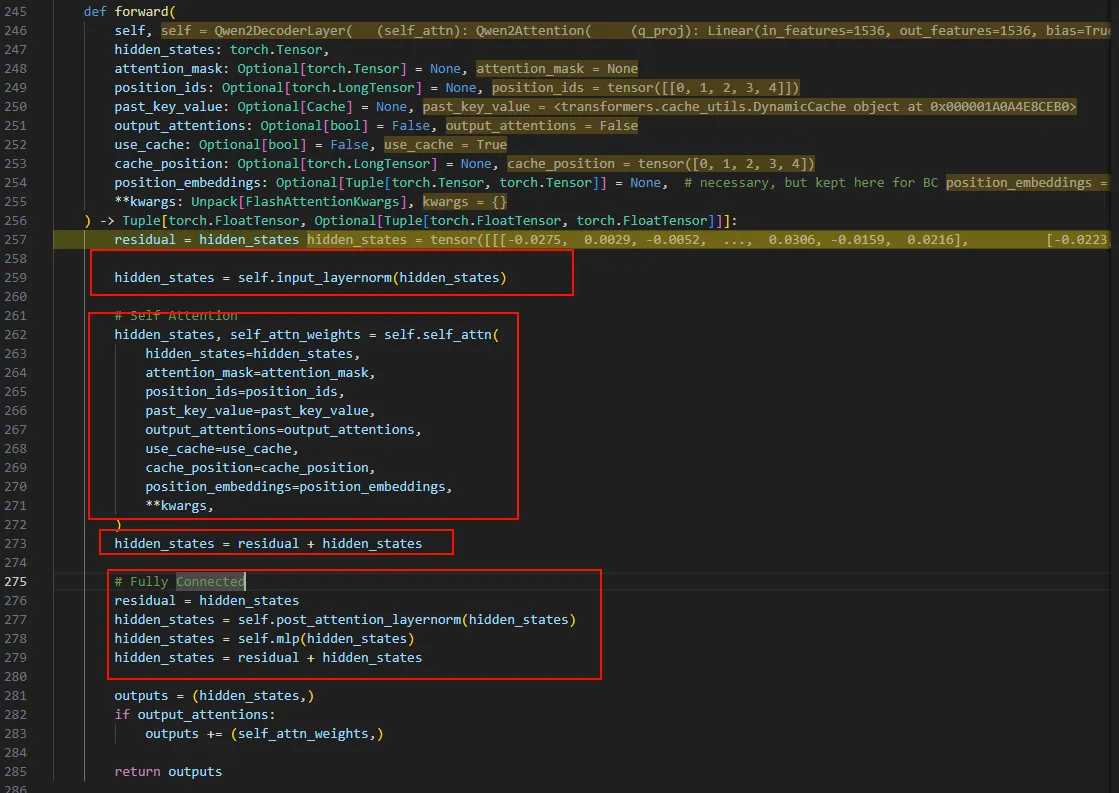
这里无非就是将输入的hidden_states与刚刚加载到模型的参数相乘,最终得到outputs。
这里只简单看看自注意力层。以我目前初浅的理解,自注意力层是用来将输入seq的embedding做一个变形,使得变形后的embedding有同一个seq其他token的信息。所以体现到代码上就是输入一个hidden_states,然后内部计算出qkv矩阵进行计算,输出一个相同维度的hidden_states。
自注意力层通过Qwen2Attention实现。 可以看到刚进来时候参数hidden_states就是token进行embedding的维度。接下来计算出qkv。
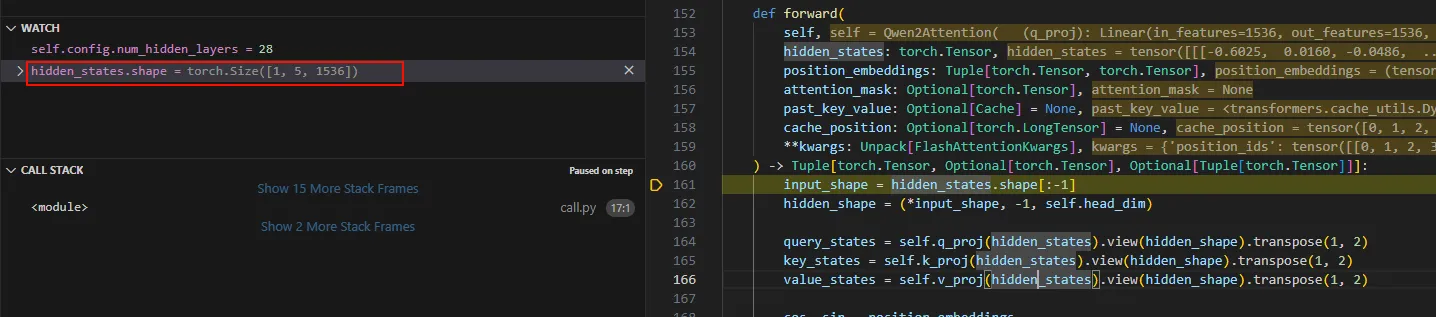
随后调用attention_interface计算自注意力,这个函数是sdpa_attention_forward。

sdpa_attention_forward这里是一个多头自注意力的计算,总共12个头,每个头使用embedding的128维。并且也看到了大名鼎鼎的scaled_dot_product_attention。
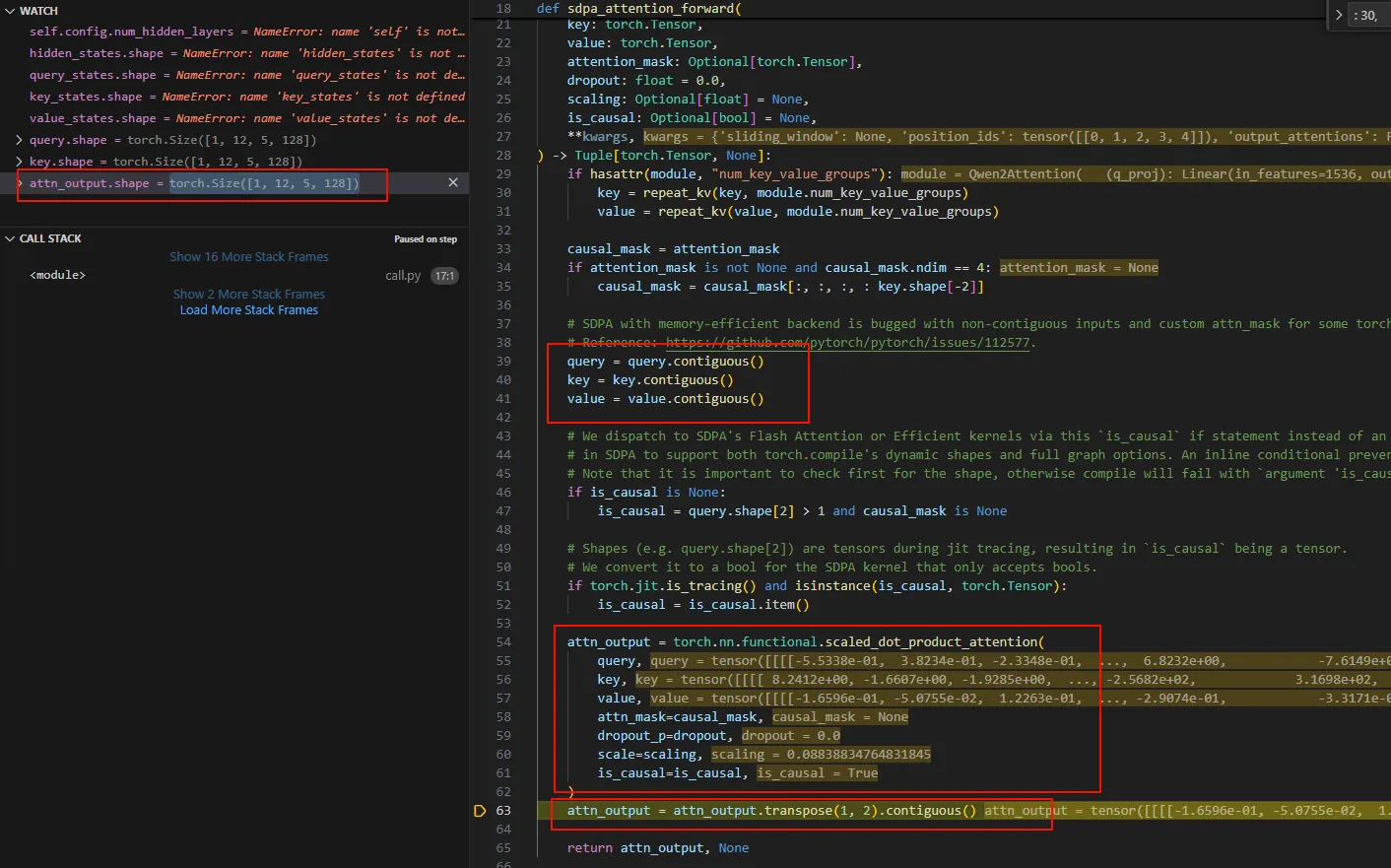
sdpa_attention_forward执行完成之后,attn_output.shape为[1, 5, 12, 128]分别表示batch_size为1, seq len为5,num of heads 为12,每个head dim为128。
回到Qwen2Attention.forward,多头自注意计算完成之后,要合并头。然后乘以一个o_proj。
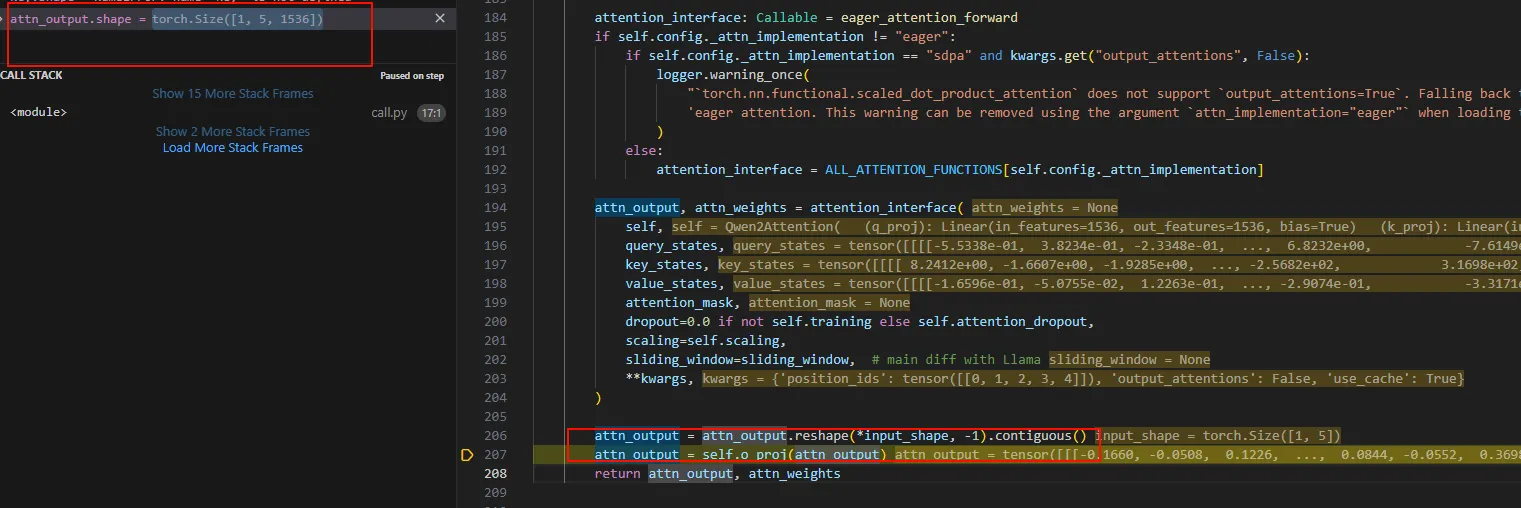
回到Qwen2DecoderLayer.forward,进行完自注意计算self.self_attn之后就是全连接层。
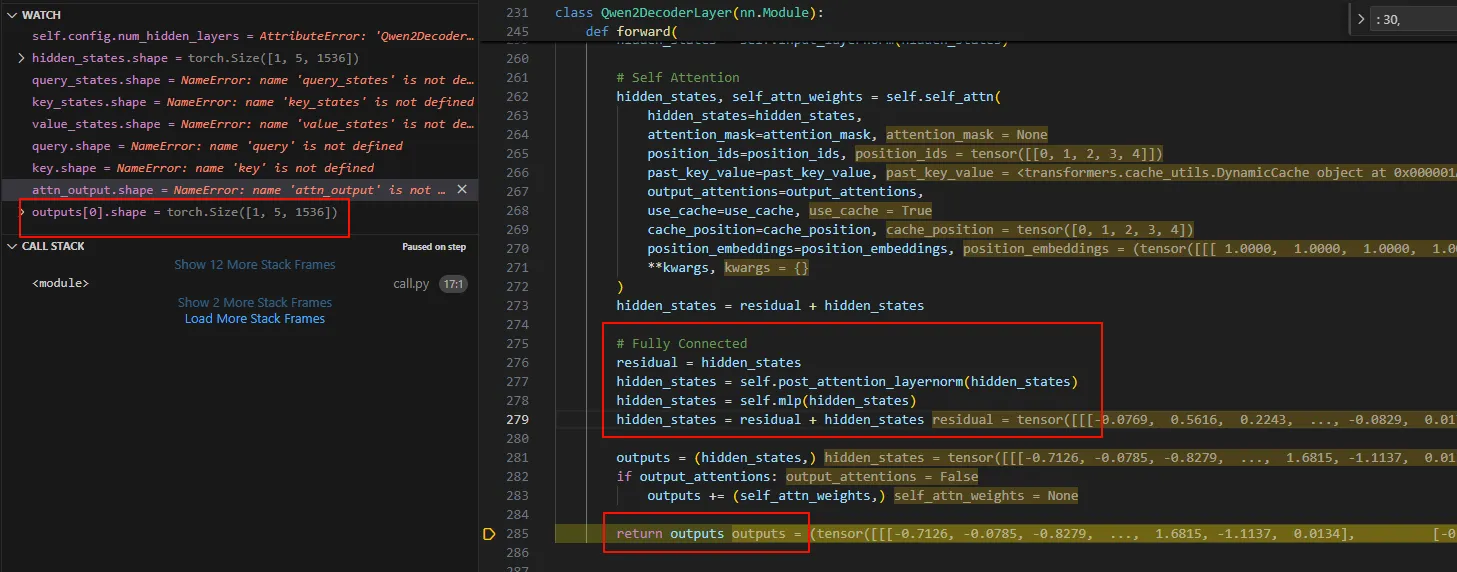
本质还是矩阵相乘,最终输出output,最新的hidden_states放到了oututs[0]。
最终回到Qwen2Model.forward,这就完成了一次decode layer的计算。经过28次的decode计算,我们的Qwen2Model.forward也走到最后一步,BaseModelOutputWithPast,单步跟进该函数会最终会进入到Qwen2ForCausalLM.forward。
Qwen2ForCausalLM.forward中,会走一次lm_head这个Linear层,最终输出一个151936的大小的logits。
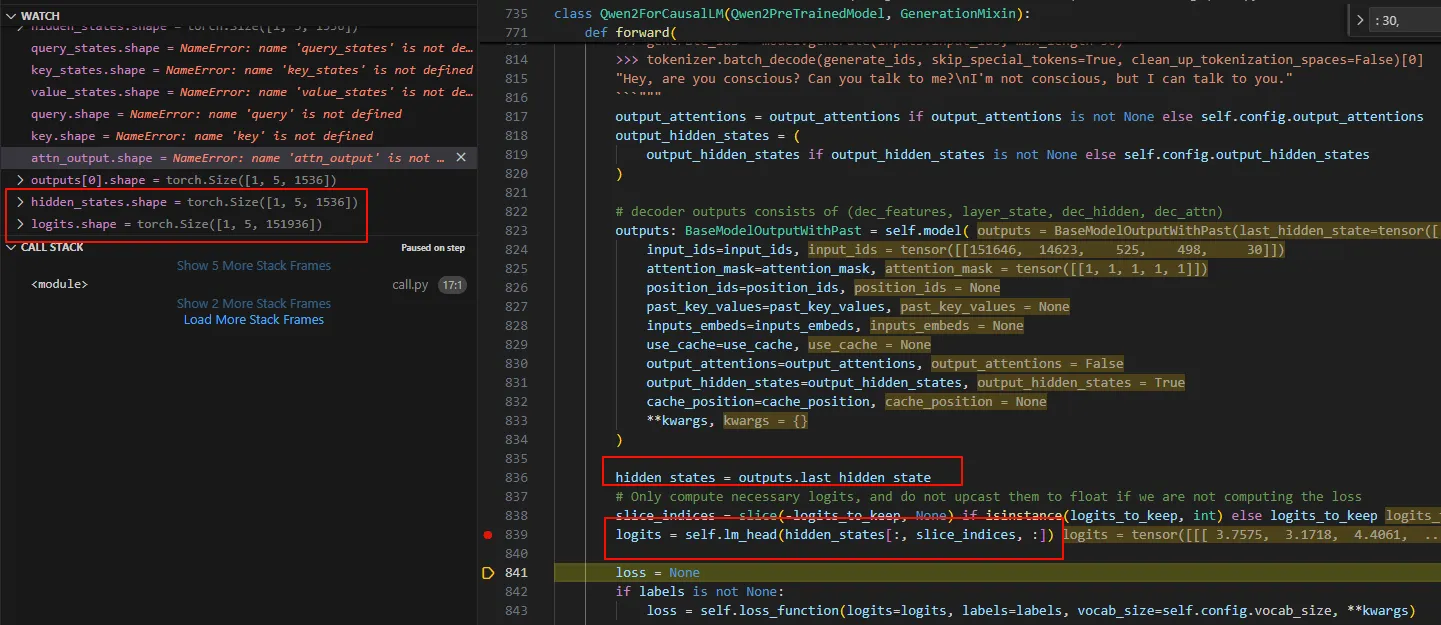
Qwen2ForCausalLM.forward最终返回CausalLMOutputWithPast对象。具体如下:
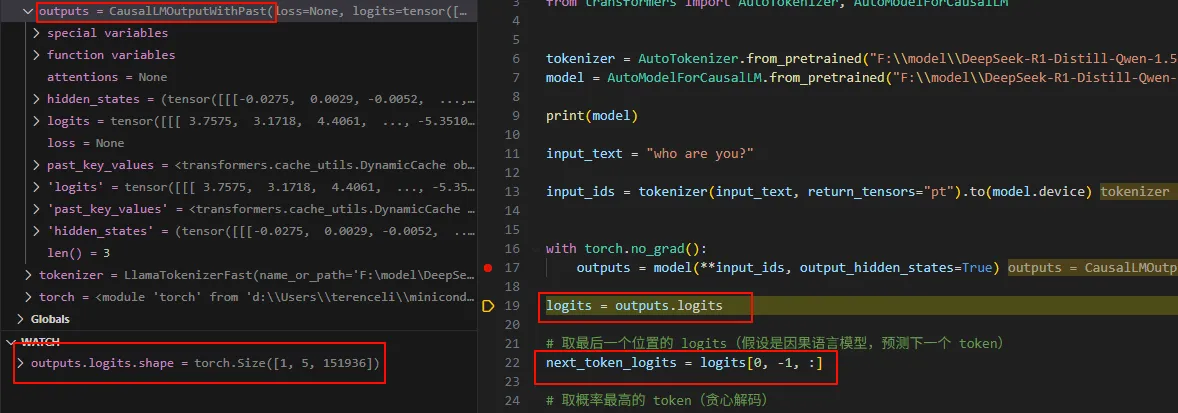
总结
本文是对学习推理过程的一些调试分析记录。通过这个过程从整体上了解了推理的流程。本质上推理框架就是将这个过程进行优化,尽可能的的快的进行预测。
blog comments powered by Disqus