transformer库中的kv cache分析与调试
这篇文章记录了kv cache到底cache的是啥,以及为啥kv cache能够work。在研究kv cache的时候,有两个问题困扰我很久。
- 为什么说只有causal模型能够使用kv cache
- transformer中默认代码里面没有使用causal mask
kv cache原理
我们知道,transformer里面一个重要环节是做self attention,而self attention又是通过qkv实现的。这里暂时不讨论qkv的深层含义,简单理解就是输入的token经过三个线性变化之后变为与原始输入维度相同的三个矩阵qkv。再经过下面的attention计算公式,计算出一个与原始输入维度相同的向量,该向量包含的各个token之间的相互关系。
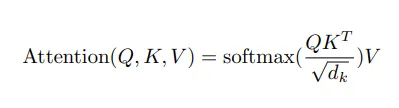
这里我们把这个过程细化一下,来看看为什么可以进行KV cache,除以那个dk和softmax都不是重点,重点是三个矩阵相乘。 首先看,qkv的产生。下面的S矩阵是一个 [3, 4]的矩阵,W是 [4, 4]的矩阵。这个3就是sequence length,表示有多少个token,W矩阵是训练出来的参数,在推理阶段是从safetensors加载上来的。

经过这么计算,我们生成了一个Q矩阵,同样的方法,我们生成了K矩阵和V矩阵。首先看看Q和K转置相乘。

这里我们得到一个[seq_len, seq_len]的矩阵,这个是各个token的自注意力权重矩阵,其中的Q1和K1是Q、K中的一行。接下来再通过乘以V得到最后的自注意力输出。
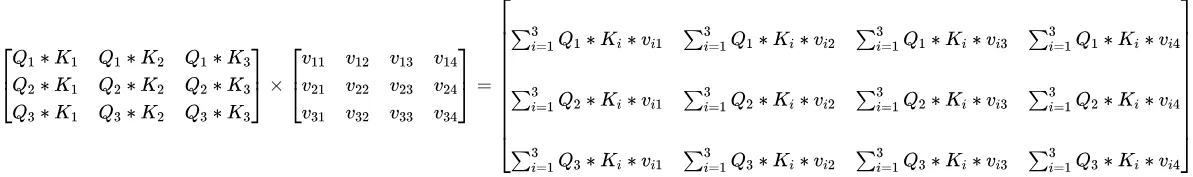
下面我们看看增加一行之后,自注意力权重矩阵的变化以及自注意力输出。当增加一行后,QKV矩阵都会相应增加一行。可以看到自注意力矩阵在在两个末尾都各自增加了一行。

自注意力输出。
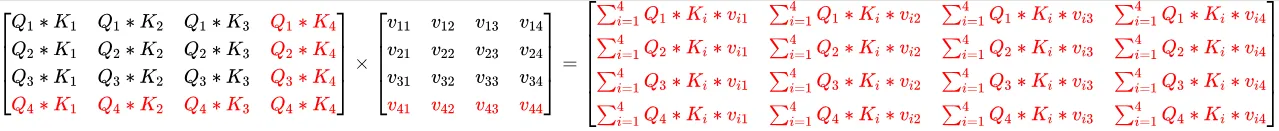
红色表示变化了的。
kv cache本本质上就是保存了每个token计算时候的各层的kv值,然后等下一个token生成的时候能够增量的计算自注意力输出,也就是上面的K V矩阵中的黑色部分(老的K V)。
我在刚看kv cache的时候,大部分的文章都说必须是kv cache只能适用于decoder-only的模型,因为其有一个attention mask或者通常也叫causal mask,这个mask是一个下三角矩阵,用来将自注意力的上三角给mask掉。之所以要mask,是因为decoder-only模型中,每个token只需要关注之前的token,之前的token不用关注之后的token。
我最开始看Q和K转置相乘的时候觉得causal mask没啥用。所以一直在搜kv caches与causal mask的强相关的关系,直到看到这篇文章GLM-4 (6) - KV Cache / Prefill & Decode 之后才理解。Q和K转置相乘虽然能够从增量token计算出增量的QK相乘的矩阵,但是可以看到与V相乘之后,整个自注意力的输出每个元素都会变化。所以整个自注意力全部改变了,其实Q和K转置相乘之后再做一个softmax之后,自注意力权重矩阵已经变了。
来看看有了causal mask之后的。同样,假设首先有三个token,一次性算出了对应的Q K V。
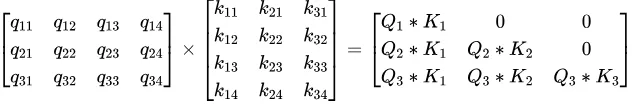
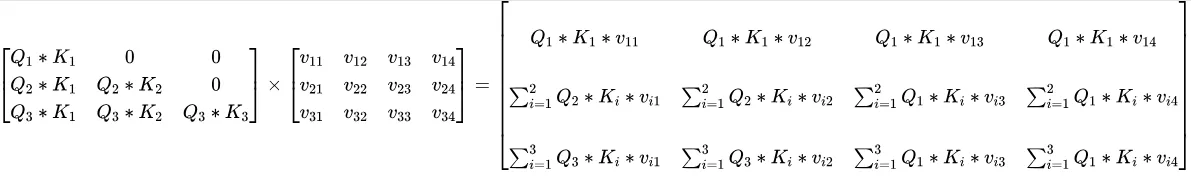
增加一行:

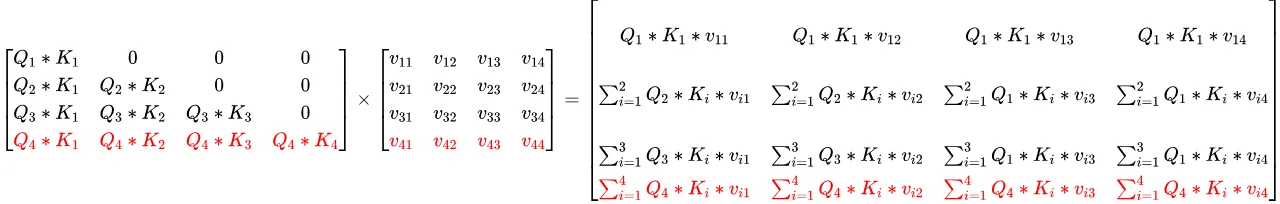
我们看到有了causal mask之后,自注意力的输出也能够增量的根据单个token增加了。增量的自注意力再单独走一遍transformer矩阵,最终输出下一个token。 从上面的矩阵也可以看到,自注意的输出跟历史所有的K V有关,所以我们把历史K和V都存起来,就叫KV cache,其实是两个cache。注意到transformer通常都有很多层,每个层的自注意力是单独算的,所以每个层都有自己的kv cache。
kv cache简单例子
上面是理论部分,本节我们通过一个简单的例子体会下KV cache的作用。 参考这个仓库里面的代码,我们的测试代码如下:
import numpy as np # 导入 numpy 库
def get_attn_subsequent_mask(seq):
#------------------------- 维度信息 --------------------------------
# seq 的维度是 [batch_size, seq_len(Q)=seq_len(K)]
#-----------------------------------------------------------------
# 获取输入序列的形状
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
#------------------------- 维度信息 --------------------------------
# attn_shape 是一个一维张量 [batch_size, seq_len(Q), seq_len(K)]
#-----------------------------------------------------------------
# 使用 numpy 创建一个上三角矩阵(triu = triangle upper)
subsequent_mask = np.triu(np.ones(attn_shape), k=1)
#------------------------- 维度信息 --------------------------------
# subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]
#-----------------------------------------------------------------
# 将 numpy 数组转换为 PyTorch 张量,并将数据类型设置为 byte(布尔值)
subsequent_mask = torch.from_numpy(subsequent_mask).bool()
#------------------------- 维度信息 --------------------------------
# 返回的 subsequent_mask 的维度是 [batch_size, seq_len(Q), seq_len(K)]
#-----------------------------------------------------------------
return subsequent_mask # 返回后续位置的注意力掩码
import torch
import torch.nn.functional as F
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len, feature_dim)
# 定义线性层用于将 x 转换为 Q, K, V 向量
linear_q = torch.nn.Linear(4, 4)
linear_k = torch.nn.Linear(4, 4)
linear_v = torch.nn.Linear(4, 4)
# 通过线性层计算 Q, K, V
Q = linear_q(x) # 形状 (batch_size, seq_len, feature_dim)
K = linear_k(x) # 形状 (batch_size, seq_len, feature_dim)
V = linear_v(x) # 形状 (batch_size, seq_len, feature_dim)
# 计算 Q 和 K 的点积,作为相似度分数 , 也就是自注意力原始权重
raw_weights = torch.bmm(Q, K.transpose(1, 2)) # 形状 (batch_size, seq_len, seq_len)
# 将自注意力原始权重进行缩放
scale_factor = K.size(-1) ** 0.5 # 这里是 4 ** 0.5
scaled_weights = raw_weights / scale_factor # 形状 (batch_size, seq_len, seq_len)
# 对缩放后的权重进行 softmax 归一化,得到注意力权重
scaled_weights.masked_fill_(get_attn_subsequent_mask(x), -1e9)
attn_weights = F.softmax(scaled_weights, dim=2)
# attn_weights = F.softmax(scaled_weights, dim=2) # 形状 (batch_size, seq_len, seq_len)
# 将注意力权重应用于 V 向量,计算加权和,得到加权信息
attn_outputs = torch.bmm(attn_weights, V) # 形状 (batch_size, seq_len, feature_dim)
print("x自注意力矩阵:", attn_weights)
print("x自注意力输出:", attn_outputs)
y = torch.rand(2, 1, 4)
z = torch.cat((x,y), 1)
Qz = linear_q(z)
Kz = linear_k(z)
Vz = linear_v(z)
raw_weights1 = torch.bmm(Qz, Kz.transpose(1, 2))
scale_factor1 = Kz.size(-1) ** 0.5
scaled_weights1 = raw_weights1 / scale_factor1
scaled_weights1.masked_fill_(get_attn_subsequent_mask(z), -1e9)
attn_weights1 = F.softmax(scaled_weights1, dim=2)
attn_outputs1 = torch.bmm(attn_weights1, Vz) # 形状 (batch_size, seq_len, feature_dim)
print("z自注意力矩阵:", attn_weights1)
print("z自注意力输出:", attn_outputs1)
上面的代码随机生成一个batch_size为2,token大小为3, embbed_size为4的矩阵x,随后计算出其自注意力矩阵和自注意力输出,并且使用函数 get_attn_subsequent_mask 得到了causal mask矩阵。
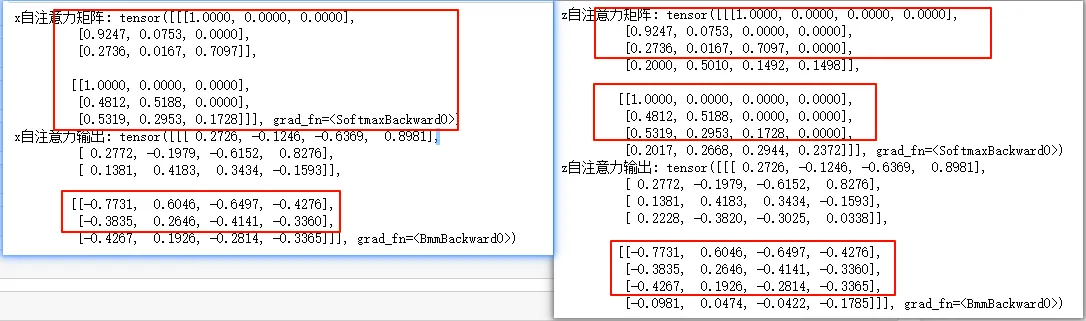
可以看到当增加一个token(y)之后,整个注意力输出只增加了一行,就是新的y的自注意力输出,其余的注意力输出是一样的。
这个例子基本显示了kv cache下token的处理情况,即对于prompt整体作为输入(x),生成kv cache,并且生成第一个token,随后用新的token(y)单独去走transformer,生成下一个token。 下面我们实际调试看看transformer中情况。
transformer中的kv cache分析
本节调试transformer中使用kv cache和不使用kv cache的情况,使用的模型还是 DeepSeek-R1-Distill-Qwen-1.5B。
我们先来看看没有cache的情况,现在transformer都默认使用kv cache,所以需要再调用 AutoModelForCausalLM.from_pretrained 的时候指定 use_cache=False。整个代码如下:
# Load model directly
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B", use_cache=False)
input_text = "who are you?"
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(input_ids=input_ids.input_ids, max_length=50, pad_token_id=tokenizer.pad_token_id, use_cache=False)
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)
model.generate开始下断点,进行调试,F11走起。 首先看下面的,根据prompts生成第一个token的过程叫prefill,之后生成token过程叫decode。下面是即将开始首先得prefill过程。
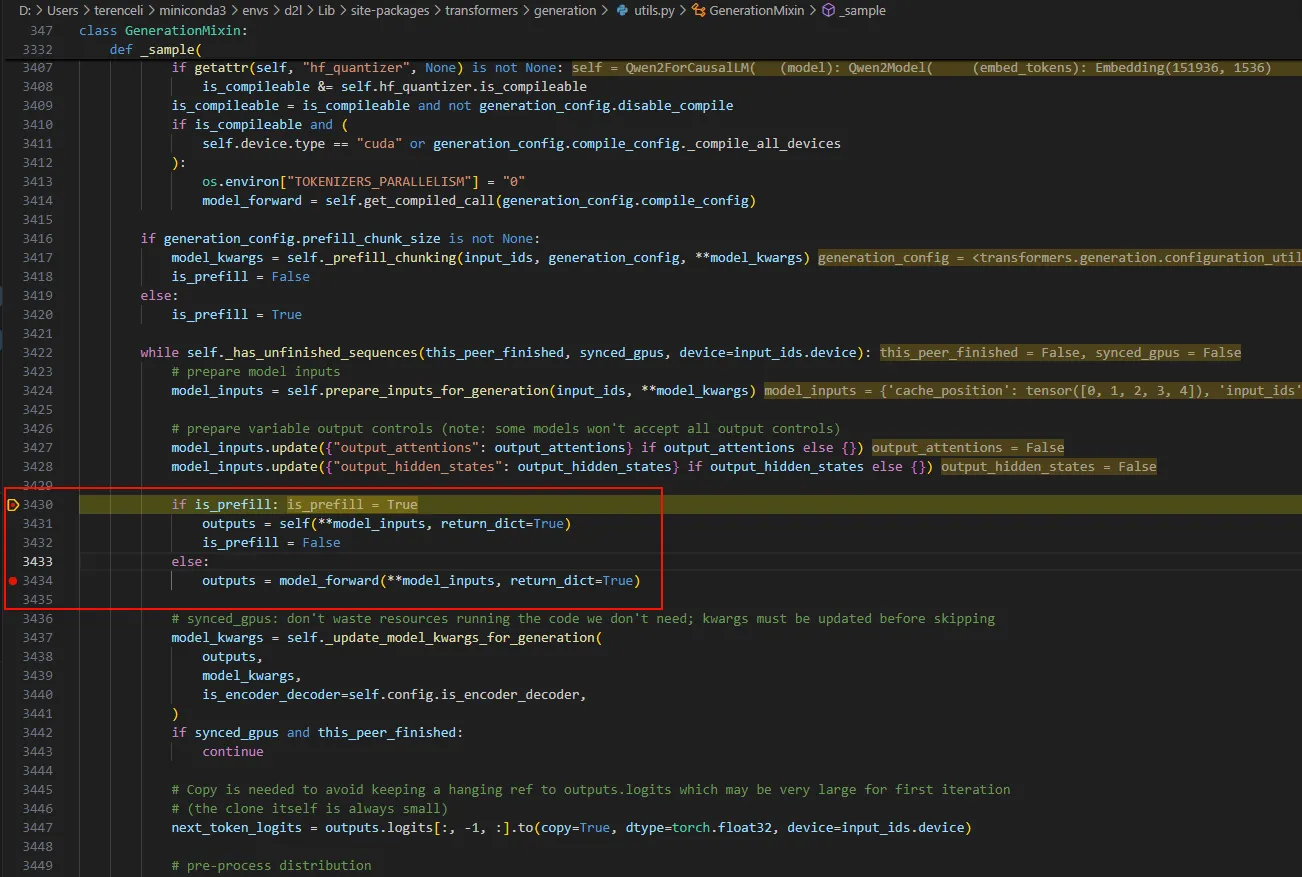
进入Qwen2Model的forward中:可以看到这里输入了5个token。

进入Qwen2Attention的forward中,直到sdpa_attention_forward中。
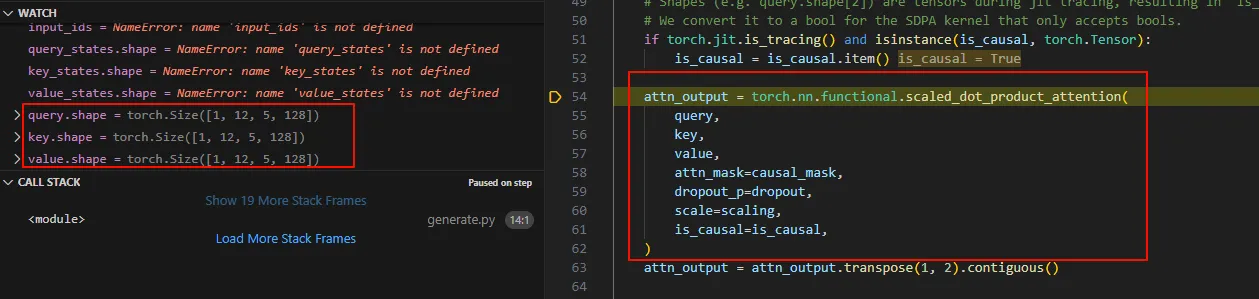
可以看到这里在计算5个token的自注意力,这里用了多头,原理跟单头也是一样的。 下面开始进入decode阶段。

注意看,这里把所有的6个token(prompt的5个)和新生成的一个直接传过来了。 看看自注意力计算:

可以看到,也是6个都过来计算。所以在没有kv cache的情况下,每次的推理过程,都要计算所有token的自注意力。
下面我们看看使用kv cache的情况。 使用代码如下:
# Load model directly
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
input_text = "who are you?"
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(input_ids=input_ids.input_ids, max_length=50, pad_token_id=tokenizer.pad_token_id)
output_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(output_text)
prefill阶段如果使用use_cache,则会在 past_key_value保保存kv cache,每层一个。
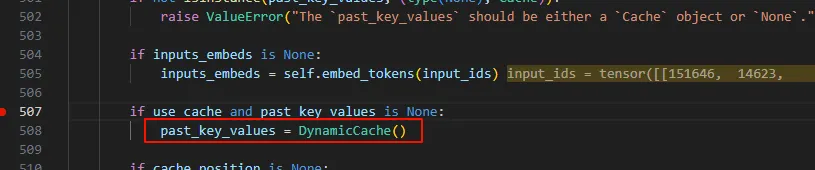
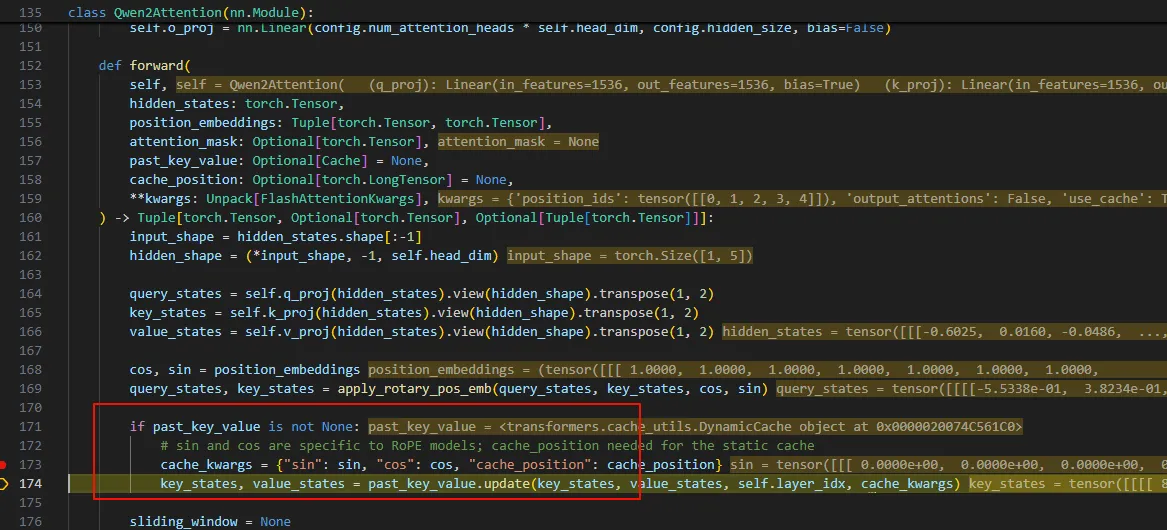
本质就是每层一个key_cache,一个value_cache。
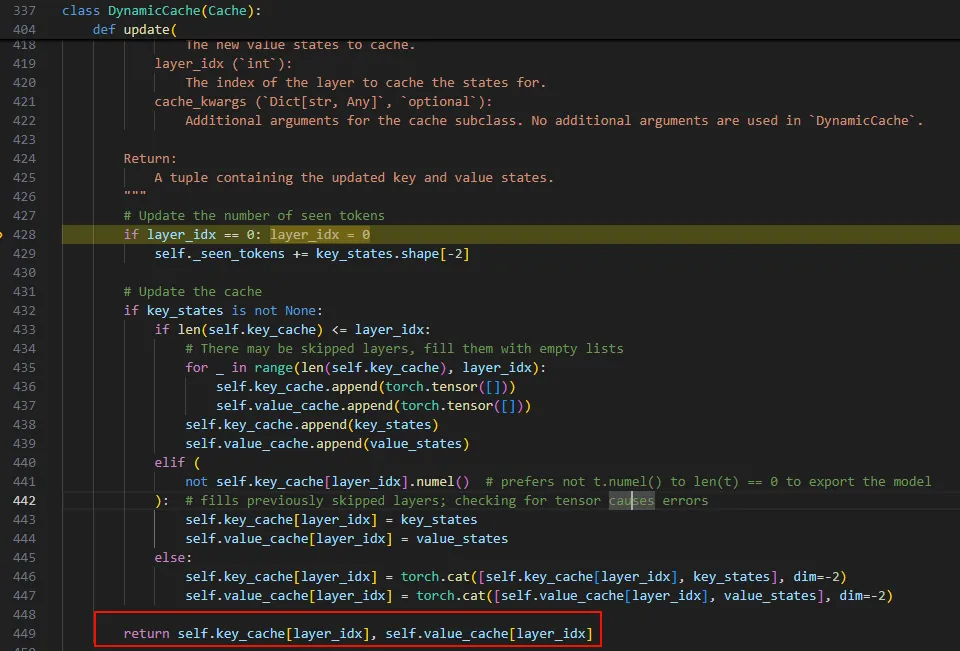
下面进入decode,注意看,下面的decode输入到模型的token只有一个了。

在计算自注意力时,只使用了本次token的Q,以及所有的KV。

而这里的K V是从上次K V和本次的k v 连起来的。所以这里使用了cache的KV矩阵。
到这里我们可能又有一个疑问了,在没有kv cache的时候,decode输入的token长度为seq len,在使用kv cache时候,decode只有一个token,这在整个transformer中运行时会不会缺少信息。其实不会,从下面的结构可以看到,各个层输入的其实都是1536,即token embedding之后的,并且从attention的计算可以看出,这个输入只与当前token的Q以及它之前的KV以及它自己的KV有关系。
在调试过程中,也可以看到,每次推理过程其实是会把所有token的下一个token概率打出来。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B")
model = AutoModelForCausalLM.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B", use_cache=False)
print(model)
input_text = "who are you?"
input_ids = tokenizer(input_text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model(**input_ids, output_hidden_states=True)
logits = outputs.logits
logits = logits.squeeze(0) # 形状变为 (sequence_length, vocab_size)
# 对每个位置取概率最高的token ID
predicted_token_ids = torch.argmax(logits, dim=-1) # 形状 (sequence_length,)
# 解码所有预测的token
predicted_tokens = tokenizer.batch_decode(predicted_token_ids, skip_special_tokens=True)
# 打印每个位置的预测结果
for idx, token in enumerate(predicted_tokens):
print(f"Position {idx}: {token}")
可以看到输入如下:
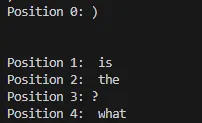
这个意思是说,最开始的token(start_of_sentence)下一个概率最大的是”)\n\n”,而第二个token ‘[sos] who’的下一个token是’is’,最终,’[sos] who are you?”这5个token下一个最大的就是’what’。每计算一个token,就会看看该token跟前面所有token注意力,通过这个主意来获取传统RNN的token之间的关系。
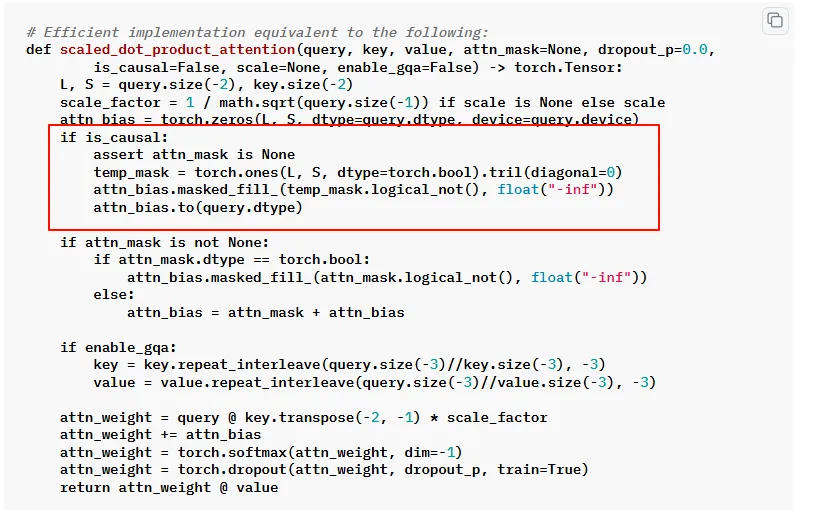
在研究causal mask的过程中,我发现进行在进行自注意力计算的时候attn_mask总是为空,例如下图,这不符合预期啊。

研究半天,后来总算找到其他人也有这个疑问 ,最终发现,torch.nn.functional.scaled_dot_product_attention 的参数 is_causal为True是,该函数会自己处理causal mask。代码参考这里,看到了熟悉的代码。
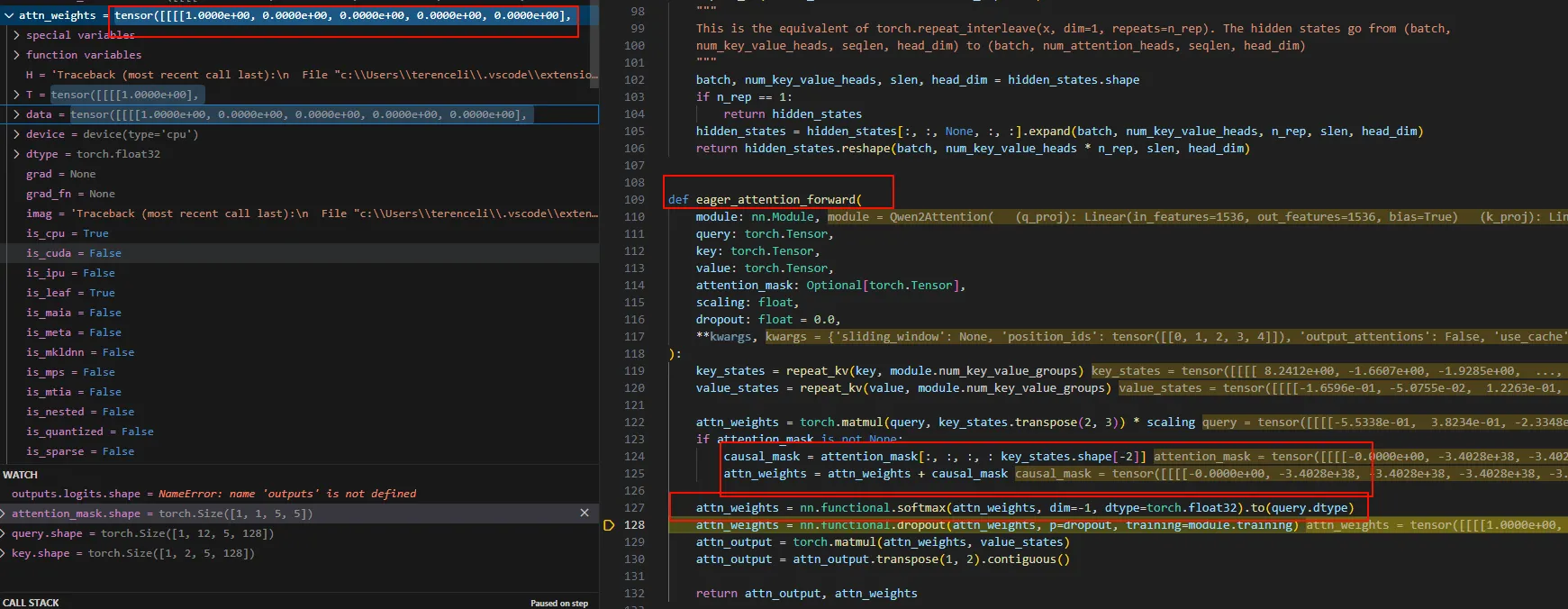
当我们将attention的实现切换为eager时,可以看到这个causal mask的计算。
model = AutoModelForCausalLM.from_pretrained("F:\\model\\DeepSeek-R1-Distill-Qwen-1.5B", use_cache=False, attn_implementation='eager')
在 eager_attention_forward 中可以看到,attn_weght在经过softmax之后,呈现了下三角的样子。
总结
transformer中kv cache的简单分析就差不多结束了,这里以几个问题进行总结。
-
为什么说只有 Causal 模型能够使用 KV Cache
因为 Causal 模型中,有 sequence 的 attention mask,使得新 token 的注意力只依赖自身的 QKV 以及历史 token 的 KV。
-
为什么没有 Q Cache
从上面分析可以看到,历史的 Q 并没有使用,存起来没有意义。
-
Transformer 中默认代码里面没有使用 Causal Mask
使用了,是在 PyTorch 框架函数里面使用的。
Ref
GLM-4 (6) - KV Cache / Prefill & Decode
blog comments powered by Disqus