VFIO driver analysis
The VFIO driver is a framework for exposing direct device access to userspace. Virtual machine technology uses VFIO to assign physical device to VMs for highest possible IO performance. In this post, I will just focus the driver of VFIO.
VFIO’s basic idea is showing in the following figure. This is from Alex’s talk An Introduction to PCI Device Assignment with VFIO.
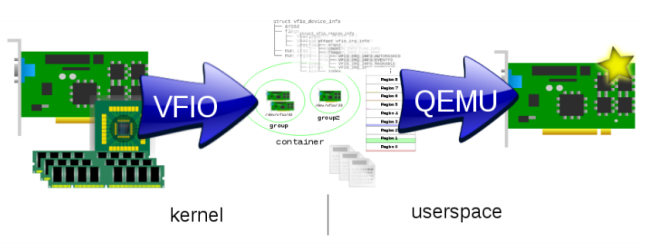
VFIO decomposes the physical device as a set of userspace API and recomposes the physical device’s resource to a virtual device in qemu.
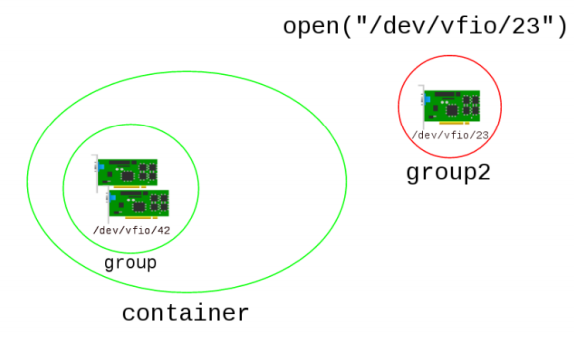
There are three concepts in VFIO: Groups, Devices, and Containers.
Devices create a programming interface made up of IO access, interrupts, and DMA. The userspace(qemu) can utilize this interface to get the device’s information and config the devices.
Groups is a set of devices which is isolatable from all other devices in the system. Group is the minimum granularity that can be assigned to a VM.
Containers is a set of groups. Different groups can be set in the same container.
Following figure shows the relation of container, group and device.
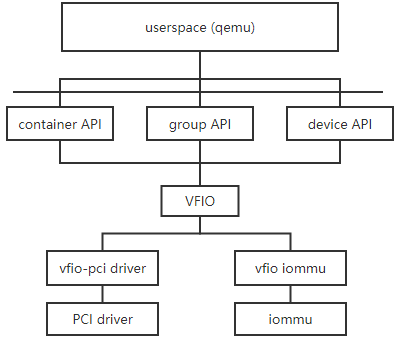
Following figure shows the architecture of VFIO PCI.
Bind device to vifo-pci driver
In the ‘VFIO usage’ post, we know that before assigning the device to VM, we need to unbind its original driver and bind it to vfio-pci driver firstly.
vfio-pci driver just registers ‘vfio_pci_driver’ in ‘vfio_pci_init’ function. When binding the assigned device, the ‘probe’ callback will be called, it’s ‘vfio_pci_probe’.
‘vfio_pci_probe’ first allocates and initializes a ‘vfio_pci_device’ struct, then calls ‘vfio_add_group_dev’ to create and add a ‘vfio_device’ to ‘vfio_group’. If the ‘vfio_group’ is not created, ‘vfio_add_group_dev’ will also create one.
int vfio_add_group_dev(struct device *dev,
const struct vfio_device_ops *ops, void *device_data)
{
struct iommu_group *iommu_group;
struct vfio_group *group;
struct vfio_device *device;
iommu_group = iommu_group_get(dev);
if (!iommu_group)
return -EINVAL;
group = vfio_group_get_from_iommu(iommu_group);
if (!group) {
group = vfio_create_group(iommu_group);
if (IS_ERR(group)) {
iommu_group_put(iommu_group);
return PTR_ERR(group);
}
} else {
/*
* A found vfio_group already holds a reference to the
* iommu_group. A created vfio_group keeps the reference.
*/
iommu_group_put(iommu_group);
}
device = vfio_group_get_device(group, dev);
if (device) {
WARN(1, "Device %s already exists on group %d\n",
dev_name(dev), iommu_group_id(iommu_group));
vfio_device_put(device);
vfio_group_put(group);
return -EBUSY;
}
device = vfio_group_create_device(group, dev, ops, device_data);
if (IS_ERR(device)) {
vfio_group_put(group);
return PTR_ERR(device);
}
/*
* Drop all but the vfio_device reference. The vfio_device holds
* a reference to the vfio_group, which holds a reference to the
* iommu_group.
*/
vfio_group_put(group);
return 0;
}
‘vfio_group’ is defined as following:
struct vfio_group {
struct kref kref;
int minor;
atomic_t container_users;
struct iommu_group *iommu_group;
struct vfio_container *container;
struct list_head device_list;
struct mutex device_lock;
struct device *dev;
struct notifier_block nb;
struct list_head vfio_next;
struct list_head container_next;
struct list_head unbound_list;
struct mutex unbound_lock;
atomic_t opened;
};
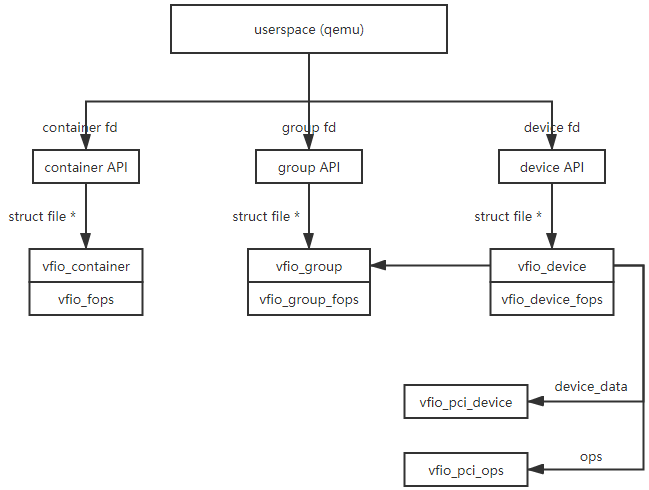
‘vfio_create_group’ creates and initializes a ‘vfio_group’. ‘vfio_create_group’ also create a device file in ‘/dev/vfio/’ directory, it represents the group file, this file’s file_ops is ‘vfio_group_fops’. ‘vfio_group’s dev is for this device. ‘container’ field points the container of which this group attached to. ‘device_list’ links the vfio device’. ‘iommu_group’ points the low level of iommu group, this is the ‘device’s iommu group created when the IOMMU setup. ‘vfio_group’ is like a bridge between the vfio interface and the low level iommu. Once ‘vfio_group’ is created, it will be linked in the global variable ‘vfio’s group_list.
In ‘vfio_add_group_dev’, after get or create a ‘vfio_group’, it will create and add a ‘vfio_device’ to the ‘vfio_group’. This is done by ‘vfio_group_create_device’. ‘vfio_device’ is defined as following:
struct vfio_device {
struct kref kref;
struct device *dev;
const struct vfio_device_ops *ops;
struct vfio_group *group;
struct list_head group_next;
void *device_data;
};
Here ‘dev’ is the physical device. ‘ops’ is ‘vfio_pci_ops’, ‘group’ is get or created right now, ‘group_next’ is used to link this ‘vfio_device’ to ‘vfio_group’s “device_list’ field. ‘device_data’ will be set to ‘vfio_pci_device’ created in ‘vfio_pci_probe’.
When the userspace trigger ioctl(VFIO_GROUP_GET_DEVICE_FD) in group’s fd, the corresponding handler ‘vfio_group_get_device_fd’ will alloc a ‘file’ pointer and a ‘fd’ using the ‘vfio_device’ as the private data. This fd’s file_ops is ‘vfio_device_fops’ which callbacks calls the ‘vfio_pci_ops’s corresponding function in mostly cases.
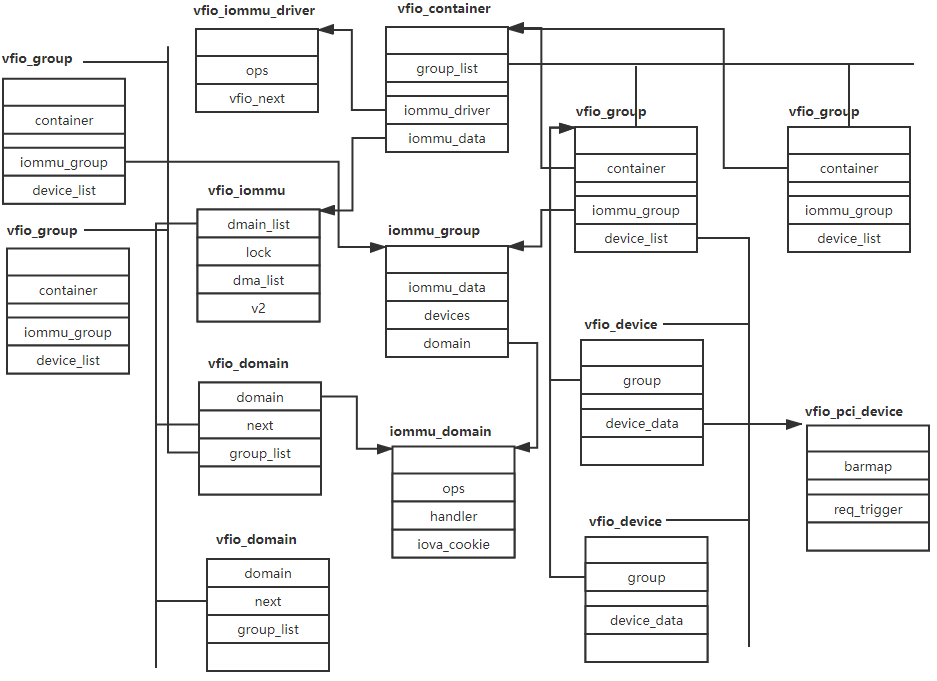
Following figure shows some of the data structure’s relation.
VFIO kernel module initialization
VFIO driver creates the ‘/dev/vfio/vfio’ device and manages the whole system’s VFIO. VFIO driver defines a ‘vfio’ global variable to store the vfio iommu driver and iommu group.
static struct vfio {
struct class *class;
struct list_head iommu_drivers_list;
struct mutex iommu_drivers_lock;
struct list_head group_list;
struct idr group_idr;
struct mutex group_lock;
struct cdev group_cdev;
dev_t group_devt;
wait_queue_head_t release_q;
} vfio;
All vfio iommu drivers will be linked in ‘iommu_drivers_list’. All vfio group will be linke in ‘group_list’.
In ‘vfio_init’, it initialize this ‘vfio’ struct and register a misc device named ‘vfio_dev’. It creates a ‘vfio’ device class and allocates the device numbers for the group node in ‘/dev/vfio/$group_id’.
‘/dev/vfio/vfio’s file_ops is ‘vfio_fops’, the ‘open’ callback is ‘vfio_fops_open’. We can see a ‘vfio_container’ is set to the ‘/dev/vfio/vfio/’s fd ‘private_data’.
static int vfio_fops_open(struct inode *inode, struct file *filep)
{
struct vfio_container *container;
container = kzalloc(sizeof(*container), GFP_KERNEL);
if (!container)
return -ENOMEM;
INIT_LIST_HEAD(&container->group_list);
init_rwsem(&container->group_lock);
kref_init(&container->kref);
filep->private_data = container;
return 0;
}
Attach the group to container and Allocate IOMMU
We now has a container fd(by opening the ‘/dev/vfio/vfio’ device) and group fd(by opening the ‘/dev/vfio/$gid’). We need to attach this group to container, this is done by calling ioctl(VFIO_GROUP_SET_CONTAINER) in group fd. The handle for this ioctl is ‘vfio_group_set_container’.
static int vfio_group_set_container(struct vfio_group *group, int container_fd)
{
struct fd f;
struct vfio_container *container;
struct vfio_iommu_driver *driver;
int ret = 0;
...
f = fdget(container_fd);
...
container = f.file->private_data;
WARN_ON(!container); /* fget ensures we don't race vfio_release */
down_write(&container->group_lock);
driver = container->iommu_driver;
if (driver) {
ret = driver->ops->attach_group(container->iommu_data,
group->iommu_group);
if (ret)
goto unlock_out;
}
group->container = container;
list_add(&group->container_next, &container->group_list);
/* Get a reference on the container and mark a user within the group */
vfio_container_get(container);
atomic_inc(&group->container_users);
unlock_out:
up_write(&container->group_lock);
fdput(f);
return ret;
}
The most important work here is to add the group to the container’s ‘group_list’. Also if the container has been set to a iommu driver, ‘vfio_group_set_container’ will attach this group to the iommu driver.
The userspace can set the container’s iommu by calling ioctl(VFIO_SET_IOMMU) on container fd. The handler for this ioctl is ‘vfio_ioctl_set_iommu’.
static long vfio_ioctl_set_iommu(struct vfio_container *container,
unsigned long arg)
{
struct vfio_iommu_driver *driver;
long ret = -ENODEV;
down_write(&container->group_lock);
/*
* The container is designed to be an unprivileged interface while
* the group can be assigned to specific users. Therefore, only by
* adding a group to a container does the user get the privilege of
* enabling the iommu, which may allocate finite resources. There
* is no unset_iommu, but by removing all the groups from a container,
* the container is deprivileged and returns to an unset state.
*/
if (list_empty(&container->group_list) || container->iommu_driver) {
up_write(&container->group_lock);
return -EINVAL;
}
mutex_lock(&vfio.iommu_drivers_lock);
list_for_each_entry(driver, &vfio.iommu_drivers_list, vfio_next) {
void *data;
if (!try_module_get(driver->ops->owner))
continue;
/*
* The arg magic for SET_IOMMU is the same as CHECK_EXTENSION,
* so test which iommu driver reported support for this
* extension and call open on them. We also pass them the
* magic, allowing a single driver to support multiple
* interfaces if they'd like.
*/
if (driver->ops->ioctl(NULL, VFIO_CHECK_EXTENSION, arg) <= 0) {
module_put(driver->ops->owner);
continue;
}
/* module reference holds the driver we're working on */
mutex_unlock(&vfio.iommu_drivers_lock);
data = driver->ops->open(arg);
if (IS_ERR(data)) {
ret = PTR_ERR(data);
module_put(driver->ops->owner);
goto skip_drivers_unlock;
}
ret = __vfio_container_attach_groups(container, driver, data);
if (!ret) {
container->iommu_driver = driver;
container->iommu_data = data;
} else {
driver->ops->release(data);
module_put(driver->ops->owner);
}
goto skip_drivers_unlock;
}
mutex_unlock(&vfio.iommu_drivers_lock);
skip_drivers_unlock:
up_write(&container->group_lock);
return ret;
}
The vfio iommu driver supported by system is registered in ‘vfio.iommu_drivers_list’. vfio iommu driver is the layer between vfio and iommu hardware. We will take the version 2 of type1 vfio iommu as an example. ‘vfio_ioctl_set_iommu’ first calls the ‘open’ callback of vfio iommu driver, and get a driver-specific data. Then use this driver-specific data call ‘__vfio_container_attach_groups’, this function iterate the groups in this container and calls the ‘attach_group’ callback of vfio iommu driver.
‘vfio_iommu_driver_ops_type1’ is defined as following:
static const struct vfio_iommu_driver_ops vfio_iommu_driver_ops_type1 = {
.name = "vfio-iommu-type1",
.owner = THIS_MODULE,
.open = vfio_iommu_type1_open,
.release = vfio_iommu_type1_release,
.ioctl = vfio_iommu_type1_ioctl,
.attach_group = vfio_iommu_type1_attach_group,
.detach_group = vfio_iommu_type1_detach_group,
};
‘vfio_iommu_type1_open’ allocates and initializes a ‘vfio_iommu’ strut and return it. ‘vfio_iommu’ is defined as following:
struct vfio_iommu {
struct list_head domain_list;
struct mutex lock;
struct rb_root dma_list;
bool v2;
bool nesting;
};
‘domain_list’ links the ‘vfio_domain’ attached to the container. ‘dma_list’ is used to record the IOVA information.
‘vfio_iommu_type1_attach_group’ is used to attach a iommu_group to the vfio iommu. ‘vfio_iommu_type1_attach_group’ will allocate a new ‘vfio_group’ and ‘vfio_domain’. ‘vfio_domain’ has a ‘iommu_domain’ which is used to store the hardware iommu information. Then this function calls ‘iommu_attach_group’ to attach the iommu group to iommu domain. This finally calls ‘intel_iommu_attach_device’. After ‘domain_add_dev_info’->’dmar_insert_one_dev_info’->’domain_context_mapping’…->’domain_context_mapping_one’. The device’s info was written to the context table. Notice, in ‘vfio_iommu_type1_attach_group’, if two vfio_domain has the same iommu, then different group will be attached to the same ‘vfio_domain’.
Following figure shows some of the data structure’s relation.
IOVA map
The userspace can set the iova(GPA)->HPA mapping by calling ioctl(VFIO_IOMMU_MAP_DMA) on container fd. The ‘VFIO_IOMMU_MAP_DMA’s argument is ‘vfio_iommu_type1_dma_map’. It is defined as following:
struct vfio_iommu_type1_dma_map {
__u32 argsz;
__u32 flags;
#define VFIO_DMA_MAP_FLAG_READ (1 << 0) /* readable from device */
#define VFIO_DMA_MAP_FLAG_WRITE (1 << 1) /* writable from device */
__u64 vaddr; /* Process virtual address */
__u64 iova; /* IO virtual address */
__u64 size; /* Size of mapping (bytes) */
};
The ‘vaddr’ is the virtual adress of qemu process, the iova is the iova of device’s view. This ioctl handler is ‘vfio_dma_do_map’. ‘vfio_dma_do_map’ will pin the physical pages of virtual address of qemu’s and then calls ‘vfio_iommu_map’ to do the iova to hpa’s mapping. It calls ‘iommu_map’ and finally calls the ‘iommu_ops’s map function, this is ‘intel_iommu_map’ to complete the mapping work.
blog comments powered by Disqus