kvm performance optimization technologies, part one
In full virtualization the guest OS doesn’t aware of it is running in an VM. If the OS knows it is running in an VM it can do some optimizations to improve the performance. This is called para virtualization(pv). From a generally speaking, Any technology used in the guest OS that it is based the assumption that it is running in a VM can be called a pv technology. For example the virtio is a para framework, and the apf is also a para feature. However in this post, I will not talk about these more complicated feature but some more small performance optimization feature in pv.
One of the most important thing in VM optimization is to reduce the VM-exit as much as possible, the best is there is no VM-exit.
This post contains the following pv optimization:
- Passthrough IPI
- PV Send IPI
- PV TLB Shootdown
- PV sched yield
- PV EOI
Passthrough IPI
Let’s first take an example of a proposed PV feature by bytedance and also a paper. It’s Passthrough IPI.
When the guest issues IPI, it will write the ICR register of LAPIC. This normally causes VM-exit as the LAPIC is emulated by vmm. ‘Passthrough IPI’try to avoid this VM-exit and VM-entry by exposing the guest with posted interrupt capability. Following pic shows the basic idea which from the above paper.
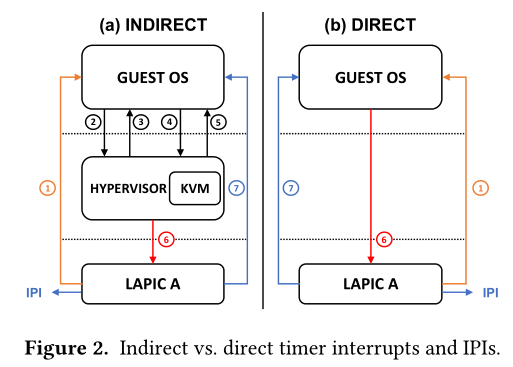
Following pic shows more detailed for this feature.
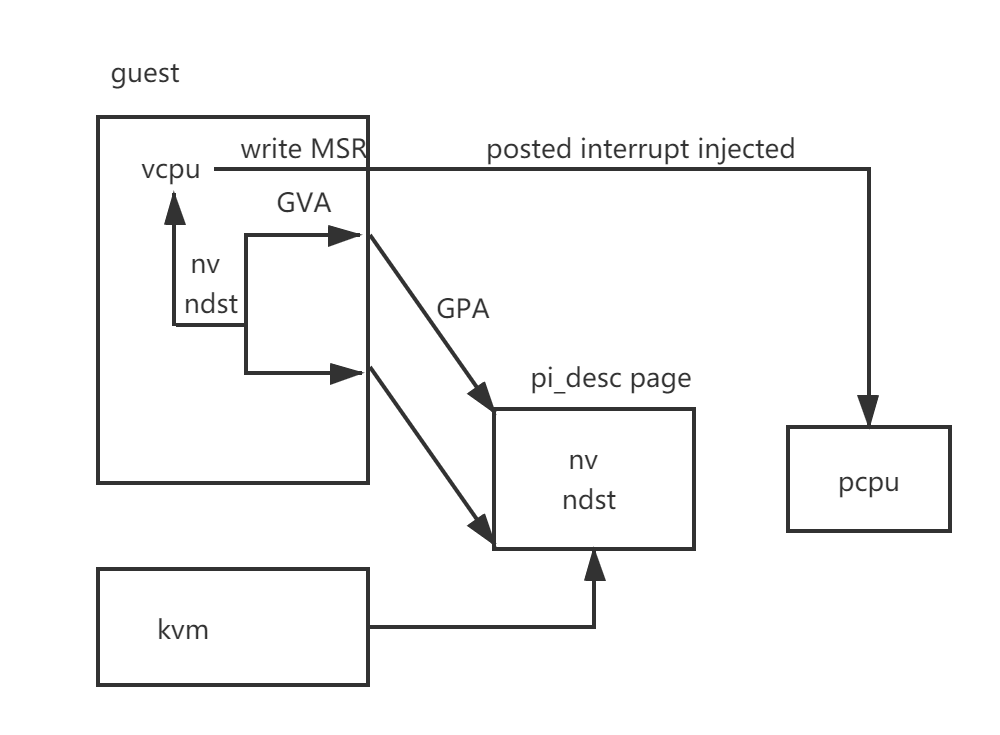
kvm side
When creating VM, the userspace should set the gpa mapping to the pi_desc by ioctl(KVM_SET_PVIPI_ADDR). ‘vmx_set_pvipi_addr’ will set the ept table for this gpa.
+static int vmx_set_pvipi_addr(struct kvm *kvm, unsigned long addr)
+{
+ int ret;
+
+ if (!enable_apicv || !x2apic_enabled())
+ return 0;
+
+ if (!IS_ALIGNED(addr, PAGE_SIZE)) {
+ pr_err("addr is not aligned\n");
+ return 0;
+ }
+
+ ret = x86_set_memory_region(kvm, PVIPI_PAGE_PRIVATE_MEMSLOT, addr,
+ PAGE_SIZE * PI_DESC_PAGES);
+ if (ret)
+ return ret;
+
+ to_kvm_vmx(kvm)->pvipi_gfn = addr >> PAGE_SHIFT;
+ kvm_pvipi_init(kvm, to_kvm_vmx(kvm)->pvipi_gfn);
+
+ return ret;
+
+}
‘kvm_pvipi_init’ will store the pvipi addr.
+void kvm_pvipi_init(struct kvm *kvm, u64 pi_desc_gfn)
+{
+ kvm->arch.pvipi.addr = pi_desc_gfn;
+ kvm->arch.pvipi.count = PI_DESC_PAGES;
+ /* make sure addr and count is visible before set valid bit */
+ smp_wmb();
+ kvm->arch.pvipi.valid = 1;
+}
When creating vcpu, we setup the pi_desc page
+static int pi_desc_setup(struct kvm_vcpu *vcpu)
+{
+ struct kvm_vmx *kvm_vmx = to_kvm_vmx(vcpu->kvm);
+ struct page *page;
+ int page_index, ret = 0;
+
+ page_index = vcpu->vcpu_id / PI_DESC_PER_PAGE;
+
+ /* pin pages in memory */
+ /* TODO: allow to move those page to support memory unplug.
+ * See commtnes in kvm_vcpu_reload_apic_access_page for details.
+ */
+ page = kvm_vcpu_gfn_to_page(vcpu, kvm_vmx->pvipi_gfn + page_index);
+ if (is_error_page(page)) {
+ ret = -EFAULT;
+ goto out;
+ }
+
+ to_vmx(vcpu)->pi_desc = page_address(page)
+ + vcpu->vcpu_id * PI_DESC_SIZE;
+out:
+ return ret;
+}
We can see this pi_desc is shared between the ‘guest’ and the vcpu struct.
The guest can read the ‘MSR_KVM_PV_IPI’ to get this shared pi_desc.
+ case MSR_KVM_PV_IPI:
+ msr_info->data =
+ (vcpu->kvm->arch.pvipi.msr_val & ~(u64)0x1) |
+ vcpu->arch.pvipi_enabled;
+ break;
The guest can write the ‘MSR_KVM_PV_IPI’ to enable/disable this feature. If the guest disable this feature it will intercept ‘X2APIC_MSR(APIC_ICR)’ MSR and the ‘pvipi_enabled’ is fale. If the guest enable this feature it will not intercept the ‘X2APIC_MSR(APIC_ICR)’ MSR and this allow the guest write this MSR directly.
+ case MSR_KVM_PV_IPI:
+ if (!vcpu->kvm->arch.pvipi.valid)
+ break;
+
+ /* Userspace (e.g., QEMU) initiated disabling PV IPI */
+ if (msr_info->host_initiated && !(data & KVM_PV_IPI_ENABLE)) {
+ vmx_enable_intercept_for_msr(vmx->vmcs01.msr_bitmap,
+ X2APIC_MSR(APIC_ICR),
+ MSR_TYPE_RW);
+ vcpu->arch.pvipi_enabled = false;
+ pr_debug("host-initiated disabling PV IPI on vcpu %d\n",
+ vcpu->vcpu_id);
+ break;
+ }
+
+ if (!kvm_x2apic_mode(vcpu))
+ break;
+
+ if (data & KVM_PV_IPI_ENABLE && !vcpu->arch.pvipi_enabled) {
+ vmx_disable_intercept_for_msr(vmx->vmcs01.msr_bitmap,
+ X2APIC_MSR(APIC_ICR), MSR_TYPE_RW);
+ vcpu->arch.pvipi_enabled = true;
+ pr_emerg("enable pv ipi for vcpu %d\n", vcpu->vcpu_id);
+ }
+ break;
guest side
When gust startup it will check ‘KVM_FEATURE_PV_IPI’ feature and if it exists ‘kvm_setup_pv_ipi2’ will be called.
+static int kvm_setup_pv_ipi2(void)
+{
+ union pvipi_msr msr;
+
+ rdmsrl(MSR_KVM_PV_IPI, msr.msr_val);
+
+ if (msr.valid != 1)
+ return -EINVAL;
+
+ if (msr.enable) {
+ /* set enable bit and read back. */
+ wrmsrl(MSR_KVM_PV_IPI, msr.msr_val | KVM_PV_IPI_ENABLE);
+
+ rdmsrl(MSR_KVM_PV_IPI, msr.msr_val);
+
+ if (!(msr.msr_val & KVM_PV_IPI_ENABLE)) {
+ pr_emerg("pv ipi enable failed\n");
+ iounmap(pi_desc_page);
+ return -EINVAL;
+ }
+
+ goto out;
+ } else {
+
+ pi_desc_page = ioremap_cache(msr.addr << PAGE_SHIFT,
+ PAGE_SIZE << msr.count);
+
+ if (!pi_desc_page)
+ return -ENOMEM;
+
+
+ pr_emerg("pv ipi msr val %lx, pi_desc_page %lx, %lx\n",
+ (unsigned long)msr.msr_val,
+ (unsigned long)pi_desc_page,
+ (unsigned long)&pi_desc_page[1]);
+
+ /* set enable bit and read back. */
+ wrmsrl(MSR_KVM_PV_IPI, msr.msr_val | KVM_PV_IPI_ENABLE);
+
+ rdmsrl(MSR_KVM_PV_IPI, msr.msr_val);
+
+ if (!(msr.msr_val & KVM_PV_IPI_ENABLE)) {
+ pr_emerg("pv ipi enable failed\n");
+ iounmap(pi_desc_page);
+ return -EINVAL;
+ }
+ apic->send_IPI = kvm_send_ipi;
+ apic->send_IPI_mask = kvm_send_ipi_mask2;
+ apic->send_IPI_mask_allbutself = kvm_send_ipi_mask_allbutself2;
+ apic->send_IPI_allbutself = kvm_send_ipi_allbutself2;
+ apic->send_IPI_all = kvm_send_ipi_all2;
+ apic->icr_read = kvm_icr_read;
+ apic->icr_write = kvm_icr_write;
+ pr_emerg("pv ipi enabled\n");
+ }
+out:
+ pr_emerg("pv ipi KVM setup real PV IPIs for cpu %d\n",
+ smp_processor_id());
+
+ return 0;
}
This function get the shared pi_desc’s GPA and if enable case it will map this GPA to GVA by calling ‘ioremap_cache’ and then write the ‘MSR_KVM_PV_IPI’ with enable bit set. This function will also replace the apic callback to its own.
In order the guest will access the LAPIC’s ICR, this feature introduces a ‘MSR_KVM_PV_ICR’ MSR to expose the physical LAPIC’s ICR to the VM.
guest trigger IPI
When the guest send IPI the ‘kvm_send_ipi’.
+static void kvm_send_ipi(int cpu, int vector)
+{
+ /* In x2apic mode, apicid is equal to vcpu id.*/
+ u32 vcpu_id = per_cpu(x86_cpu_to_apicid, cpu);
+ unsigned int nv, dest/* , val */;
+
+ x2apic_wrmsr_fence();
+
+ WARN(vector == NMI_VECTOR, "try to deliver NMI");
+
+ /* TODO: rollback to old approach. */
+ if (vcpu_id >= MAX_PI_DESC)
+ return;
+
+ if (pi_test_and_set_pir(vector, &pi_desc_page[vcpu_id]))
+ return;
+
+ if (pi_test_and_set_on(&pi_desc_page[vcpu_id]))
+ return;
+
+ nv = pi_desc_page[vcpu_id].nv;
+ dest = pi_desc_page[vcpu_id].ndst;
+
+ x2apic_send_IPI_dest(dest, nv, APIC_DEST_PHYSICAL);
+
+}
As we can see it get the ‘nv’ and ‘dest’ from the shared pi_desc page and call ‘x2apic_send_IPI_dest’ to send the pi notification vector to ‘dest’ vcpu. From the LAPIC view, this is just a posted-interrupt. If the guest is running it will trigger virtual interrupt delivery and if the guest is preempted it will be kicked to run.
PV send IPI
Wanpeng Li from Tencent also proposed a pv ipi feature and was merged into upstream. Following pic shows the idea from Boosting Dedicated Instance via KVM Tax Cut.
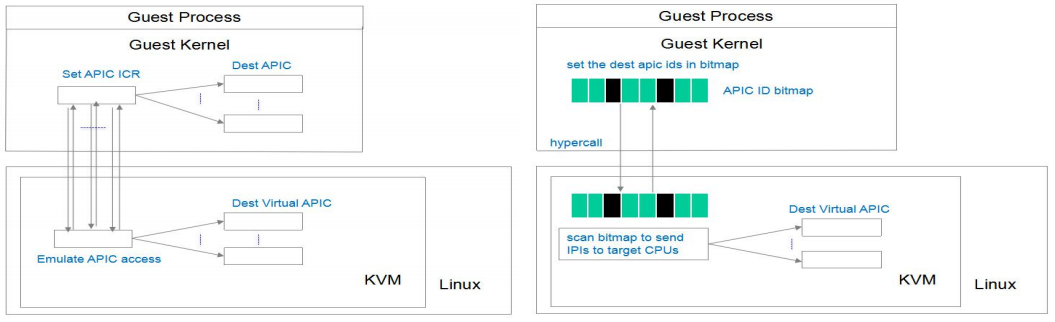
Instead of sending the IPI to vcpu one by one, the pv ipi send uses a bitmap to to record the IPI vcpu and then make a hyper call thus reduce the VM-exit. The patchset is here. Let’s see some detail
kvm side
The kvm should expose the pv send ipi feature.
@@ -621,7 +621,8 @@ static inline int __do_cpuid_ent(struct kvm_cpuid_entry2 *entry, u32 function,
(1 << KVM_FEATURE_CLOCKSOURCE_STABLE_BIT) |
(1 << KVM_FEATURE_PV_UNHALT) |
(1 << KVM_FEATURE_PV_TLB_FLUSH) |
- (1 << KVM_FEATURE_ASYNC_PF_VMEXIT);
+ (1 << KVM_FEATURE_ASYNC_PF_VMEXIT) |
+ (1 << KVM_FEATURE_PV_SEND_IPI);
The kvm side should also implement the hyper call.
+/*
+ * Return 0 if successfully added and 1 if discarded.
+ */
+static int kvm_pv_send_ipi(struct kvm *kvm, unsigned long ipi_bitmap_low,
+ unsigned long ipi_bitmap_high, int min, int vector, int op_64_bit)
+{
+ int i;
+ struct kvm_apic_map *map;
+ struct kvm_vcpu *vcpu;
+ struct kvm_lapic_irq irq = {
+ .delivery_mode = APIC_DM_FIXED,
+ .vector = vector,
+ };
+ int cluster_size = op_64_bit ? 64 : 32;
+
+ rcu_read_lock();
+ map = rcu_dereference(kvm->arch.apic_map);
+
+ for_each_set_bit(i, &ipi_bitmap_low, cluster_size) {
+ vcpu = map->phys_map[min + i]->vcpu;
+ if (!kvm_apic_set_irq(vcpu, &irq, NULL))
+ return 1;
+ }
+
+ for_each_set_bit(i, &ipi_bitmap_high, cluster_size) {
+ vcpu = map->phys_map[min + i + cluster_size]->vcpu;
+ if (!kvm_apic_set_irq(vcpu, &irq, NULL))
+ return 1;
+ }
+
+ rcu_read_unlock();
+ return 0;
+}
+
void kvm_vcpu_deactivate_apicv(struct kvm_vcpu *vcpu)
{
vcpu->arch.apicv_active = false;
@@ -6739,6 +6773,9 @@ int kvm_emulate_hypercall(struct kvm_vcpu *vcpu)
case KVM_HC_CLOCK_PAIRING:
ret = kvm_pv_clock_pairing(vcpu, a0, a1);
break;
+ case KVM_HC_SEND_IPI:
+ ret = kvm_pv_send_ipi(vcpu->kvm, a0, a1, a2, a3, op_64_bit);
+ break;
#endif
As we can see, in the hypercall handler the ‘kvm_pv_send_ipi’ can iterate the bitmap and call ‘kvm_apic_set_irq’ to send interrupt to dest vcpu.
guest side
When the system startup it will check whether the ‘KVM_FEATURE_PV_SEND_IPI’ exists. If it does, ‘kvm_setup_pv_ipi’ will be called and the apic callback will be replaced to the PV IPI.
+static void kvm_setup_pv_ipi(void)
+{
+ apic->send_IPI_mask = kvm_send_ipi_mask;
+ apic->send_IPI_mask_allbutself = kvm_send_ipi_mask_allbutself;
+ apic->send_IPI_allbutself = kvm_send_ipi_allbutself;
+ apic->send_IPI_all = kvm_send_ipi_all;
+ pr_info("KVM setup pv IPIs\n");
+}
guest trigger IPI
‘__send_ipi_mask’ is called to send IPI to vcpu.
+static void __send_ipi_mask(const struct cpumask *mask, int vector)
+{
+ unsigned long flags;
+ int cpu, apic_id, min = 0, max = 0;
+#ifdef CONFIG_X86_64
+ __uint128_t ipi_bitmap = 0;
+ int cluster_size = 128;
+#else
+ u64 ipi_bitmap = 0;
+ int cluster_size = 64;
+#endif
+
+ if (cpumask_empty(mask))
+ return;
+
+ local_irq_save(flags);
+
+ for_each_cpu(cpu, mask) {
+ apic_id = per_cpu(x86_cpu_to_apicid, cpu);
+ if (!ipi_bitmap) {
+ min = max = apic_id;
+ } else if (apic_id < min && max - apic_id < cluster_size) {
+ ipi_bitmap <<= min - apic_id;
+ min = apic_id;
+ } else if (apic_id < min + cluster_size) {
+ max = apic_id < max ? max : apic_id;
+ } else {
+ kvm_hypercall4(KVM_HC_SEND_IPI, (unsigned long)ipi_bitmap,
+ (unsigned long)(ipi_bitmap >> BITS_PER_LONG), min, vector);
+ min = max = apic_id;
+ ipi_bitmap = 0;
+ }
+ __set_bit(apic_id - min, (unsigned long *)&ipi_bitmap);
+ }
+
+ if (ipi_bitmap) {
+ kvm_hypercall4(KVM_HC_SEND_IPI, (unsigned long)ipi_bitmap,
+ (unsigned long)(ipi_bitmap >> BITS_PER_LONG), min, vector);
+ }
+
+ local_irq_restore(flags);
+}
It will set the bitmap accross the IPI target vcpu and finally call the kvm_hypercall(KVM_HC_SEND_IPI)
PV TLB Shootdown
This feature is also from Wanpeng Li in tencent.
A TLB(translation Lookside Buffer) is a cache contains the translations from virtul memory address to physical memory address. When one CPU changes the virt-to-physical mappping. It needs to tell other CPUs to invalidate the mapping in their TLB cache. This is called TLB shootdown.
TLB shootdown is performance critical operation. In bare-metal it is implemented by the architecture and can be completed with very low latencies.
However in virtualization environment, the target vCPU can be preempted and blocked. In this scenario, the TLB flush initiator vCPU will end up busy-waiting for a long time to wait for the preempted vCPU come to run. It is unefficient.
In pv TLB shootdown the TLB flush initiator vCPU will not wait the sleeping vCPU instead it just set a flag in the guest-vmm shared area and then kvm will check this flag and do the TLB flush when the sleeping vCPU come to run.
kvm side
First as other pv optimization, we need to expose pv tlb shootdown to guest.
case KVM_CPUID_FEATURES:
entry->eax = (1 << KVM_FEATURE_CLOCKSOURCE) |
(1 << KVM_FEATURE_NOP_IO_DELAY) |
(1 << KVM_FEATURE_CLOCKSOURCE2) |
(1 << KVM_FEATURE_ASYNC_PF) |
(1 << KVM_FEATURE_PV_EOI) |
(1 << KVM_FEATURE_CLOCKSOURCE_STABLE_BIT) |
(1 << KVM_FEATURE_PV_UNHALT) |
(1 << KVM_FEATURE_PV_TLB_FLUSH) |
(1 << KVM_FEATURE_ASYNC_PF_VMEXIT) |
PV tlb shootdown resues the preepted field in ‘kvm_steal_time’ to expose the vcpu running/preempted information to the guest. When the vcpu is running from preempted. If it finds the flush flag. It will do the flush.
record_steam_time()
{
if (xchg(&st->preempted, 0) & KVM_VCPU_FLUSH_TLB)
kvm_vcpu_flush_tlb_guest(vcpu);
}
When the vcpu is preempted, ‘KVM_VCPU_PREEMPTED’ will be assigned to ‘st.preempted’.
static void kvm_steal_time_set_preempted(struct kvm_vcpu *vcpu)
{
st->preempted = vcpu->arch.st.preempted = KVM_VCPU_PREEMPTED;
}
guest side
When the guest startup, it will check whether the guest supports ‘KVM_FEATURE_PV_TLB_FLUSH’ feature. If it does the ‘kvm_flush_tlb_others’ will be replaced.
if (pv_tlb_flush_supported()) {
pv_ops.mmu.flush_tlb_others = kvm_flush_tlb_others;
pv_ops.mmu.tlb_remove_table = tlb_remove_table;
pr_info("KVM setup pv remote TLB flush\n");
}
static bool pv_tlb_flush_supported(void)
{
return (kvm_para_has_feature(KVM_FEATURE_PV_TLB_FLUSH) &&
!kvm_para_has_hint(KVM_HINTS_REALTIME) &&
kvm_para_has_feature(KVM_FEATURE_STEAL_TIME));
}
guest TLB flush
When the guest does pv shootdown, ‘kvm_flush_tlb_others’ will be called.
static void kvm_flush_tlb_others(const struct cpumask *cpumask,
const struct flush_tlb_info *info)
{
u8 state;
int cpu;
struct kvm_steal_time *src;
struct cpumask *flushmask = this_cpu_cpumask_var_ptr(__pv_cpu_mask);
cpumask_copy(flushmask, cpumask);
/*
* We have to call flush only on online vCPUs. And
* queue flush_on_enter for pre-empted vCPUs
*/
for_each_cpu(cpu, flushmask) {
src = &per_cpu(steal_time, cpu);
state = READ_ONCE(src->preempted);
if ((state & KVM_VCPU_PREEMPTED)) {
if (try_cmpxchg(&src->preempted, &state,
state | KVM_VCPU_FLUSH_TLB))
__cpumask_clear_cpu(cpu, flushmask);
}
}
native_flush_tlb_others(flushmask, info);
}
Here we can see it will try to read the ‘src->preempted’ it has ‘KVM_VCPU_PREEMPTED’ bit set, the ‘KVM_VCPU_FLUSH_TLB’ will be set in the ‘src->preempted’. Thus when the vcpu is sched in it will does the tlb flush.
PV sched yield
This feature also from Wanpeng Li, he says in the patch this idea is from Xen. When sending a call-function IPI-many to vCPU, yield(by hypercall) if any of the IPI targhet vCPU was preempted.
kvm side
First we need to export this feature to the guest.
case KVM_CPUID_FEATURES:
entry->eax = (1 << KVM_FEATURE_CLOCKSOURCE) |
...
(1 << KVM_FEATURE_PV_SCHED_YIELD) |
Then we need to implement the hypercall handler to process the yield hypercall.
int kvm_emulate_hypercall(struct kvm_vcpu *vcpu)
{
case KVM_HC_SCHED_YIELD:
kvm_sched_yield(vcpu->kvm, a0);
ret = 0;
break;
}
static void kvm_sched_yield(struct kvm *kvm, unsigned long dest_id)
{
struct kvm_vcpu *target = NULL;
struct kvm_apic_map *map;
rcu_read_lock();
map = rcu_dereference(kvm->arch.apic_map);
if (likely(map) && dest_id <= map->max_apic_id && map->phys_map[dest_id])
target = map->phys_map[dest_id]->vcpu;
rcu_read_unlock();
if (target && READ_ONCE(target->ready))
kvm_vcpu_yield_to(target);
}
Find the target vcpu and yield to it.
guest side
When the guest startup it will replace the ‘smp_ops.send_call_func_ipi’ with ‘kvm_smp_send_call_func_ipi’ if the PV sched yield feature supported.
static void __init kvm_guest_init(void)
{
if (pv_sched_yield_supported()) {
smp_ops.send_call_func_ipi = kvm_smp_send_call_func_ipi;
pr_info("KVM setup pv sched yield\n");
}
}
static bool pv_sched_yield_supported(void)
{
return (kvm_para_has_feature(KVM_FEATURE_PV_SCHED_YIELD) &&
!kvm_para_has_hint(KVM_HINTS_REALTIME) &&
kvm_para_has_feature(KVM_FEATURE_STEAL_TIME));
}
guest trigger call-function IPI-many
When the guest send call func IPI, first the current vcpu will call ‘native_send_call_func_ipi’ to send IPI to the target vcpu. If the target vCPU is preempted, it will issue a hypercall ‘ KVM_HC_SCHED_YIELD’. Notice we just do this for the first vcpu as the target vcpu’s state can be changed underneath.
static void kvm_smp_send_call_func_ipi(const struct cpumask *mask)
{
int cpu;
native_send_call_func_ipi(mask);
/* Make sure other vCPUs get a chance to run if they need to. */
for_each_cpu(cpu, mask) {
if (vcpu_is_preempted(cpu)) {
kvm_hypercall1(KVM_HC_SCHED_YIELD, per_cpu(x86_cpu_to_apicid, cpu));
break;
}
}
}
PV EOI
PV EOI is another (old) pv optimization. The idea behind pv eoi is to avoid the EOI write in APIC. This exit is expensive. PV EOI uses a shared memory just like many of the optimization above. The VMM set a flag in this shared memory before injecting the interrupt, when the guest process the interrupt and write an EOI, if it finds this flag it will clear it and just return.
kvm side
First of all the kvm should expose this feature to the guest.
case KVM_CPUID_FEATURES:
entry->eax = (1 << KVM_FEATURE_CLOCKSOURCE) |
...
(1 << KVM_FEATURE_PV_EOI) |
The guest will write write the ‘MSR_KVM_PV_EOI_EN’ to set the gpa of the shared memroy and set the enable bit.
case MSR_KVM_PV_EOI_EN:
if (kvm_lapic_enable_pv_eoi(vcpu, data, sizeof(u8)))
return 1;
int kvm_lapic_enable_pv_eoi(struct kvm_vcpu *vcpu, u64 data, unsigned long len)
{
u64 addr = data & ~KVM_MSR_ENABLED;
struct gfn_to_hva_cache *ghc = &vcpu->arch.pv_eoi.data;
unsigned long new_len;
if (!IS_ALIGNED(addr, 4))
return 1;
vcpu->arch.pv_eoi.msr_val = data;
if (!pv_eoi_enabled(vcpu))
return 0;
if (addr == ghc->gpa && len <= ghc->len)
new_len = ghc->len;
else
new_len = len;
return kvm_gfn_to_hva_cache_init(vcpu->kvm, ghc, addr, new_len);
}
The ‘apic_sync_pv_eoi_to_guest’ will be called when vmentry.
static void apic_sync_pv_eoi_to_guest(struct kvm_vcpu *vcpu,
struct kvm_lapic *apic)
{
if (!pv_eoi_enabled(vcpu) ||
/* IRR set or many bits in ISR: could be nested. */
apic->irr_pending ||
/* Cache not set: could be safe but we don't bother. */
apic->highest_isr_cache == -1 ||
/* Need EOI to update ioapic. */
kvm_ioapic_handles_vector(apic, apic->highest_isr_cache)) {
/*
* PV EOI was disabled by apic_sync_pv_eoi_from_guest
* so we need not do anything here.
*/
return;
}
pv_eoi_set_pending(apic->vcpu);
}
‘pv_eoi_set_pending’ will set the ‘KVM_PV_EOI_ENABLED’ flag in shared memory.
static void pv_eoi_set_pending(struct kvm_vcpu *vcpu)
{
if (pv_eoi_put_user(vcpu, KVM_PV_EOI_ENABLED) < 0) {
printk(KERN_WARNING "Can't set EOI MSR value: 0x%llx\n",
(unsigned long long)vcpu->arch.pv_eoi.msr_val);
return;
}
__set_bit(KVM_APIC_PV_EOI_PENDING, &vcpu->arch.apic_attention);
}
The ‘apic_sync_pv_eoi_from_guest’ will be called when vmexit or cancel interrupt.
static void apic_sync_pv_eoi_from_guest(struct kvm_vcpu *vcpu,
struct kvm_lapic *apic)
{
bool pending;
int vector;
/*
* PV EOI state is derived from KVM_APIC_PV_EOI_PENDING in host
* and KVM_PV_EOI_ENABLED in guest memory as follows:
*
* KVM_APIC_PV_EOI_PENDING is unset:
* -> host disabled PV EOI.
* KVM_APIC_PV_EOI_PENDING is set, KVM_PV_EOI_ENABLED is set:
* -> host enabled PV EOI, guest did not execute EOI yet.
* KVM_APIC_PV_EOI_PENDING is set, KVM_PV_EOI_ENABLED is unset:
* -> host enabled PV EOI, guest executed EOI.
*/
BUG_ON(!pv_eoi_enabled(vcpu));
pending = pv_eoi_get_pending(vcpu);
/*
* Clear pending bit in any case: it will be set again on vmentry.
* While this might not be ideal from performance point of view,
* this makes sure pv eoi is only enabled when we know it's safe.
*/
pv_eoi_clr_pending(vcpu);
if (pending)
return;
vector = apic_set_eoi(apic);
trace_kvm_pv_eoi(apic, vector);
}
‘pv_eoi_get_pending’ will get the status of the shared flag. If it is still pending, it means the no guest trigger the EOI write, nothing to do. If the guest trigger the EOI here will call ‘apic_set_eoi’ set the EOI of APIC. Note the ‘apic->irr_pending’ will always be true with virtual interrupt delivery enabled. So pv eoi today I think is little used as the APICv is very common.
guest side
When the guest startup, it will write the ‘MSR_KVM_PV_EOI_EN’ with the ‘kvm_apic_eoi’ address and ‘KVM_MSR_ENABLED’ bit.
static void kvm_guest_cpu_init(void)
{
...
if (kvm_para_has_feature(KVM_FEATURE_PV_EOI)) {
unsigned long pa;
/* Size alignment is implied but just to make it explicit. */
BUILD_BUG_ON(__alignof__(kvm_apic_eoi) < 4);
__this_cpu_write(kvm_apic_eoi, 0);
pa = slow_virt_to_phys(this_cpu_ptr(&kvm_apic_eoi))
| KVM_MSR_ENABLED;
wrmsrl(MSR_KVM_PV_EOI_EN, pa);
}
...
}
Also it will set the ‘eoi_write’ callback with ‘kvm_guest_apic_eoi_write’.
void kvm_guest_init(void)
{
if (kvm_para_has_feature(KVM_FEATURE_PV_EOI))
apic_set_eoi_write(kvm_guest_apic_eoi_write);
}
void __init apic_set_eoi_write(void (*eoi_write)(u32 reg, u32 v))
{
struct apic **drv;
for (drv = __apicdrivers; drv < __apicdrivers_end; drv++) {
/* Should happen once for each apic */
WARN_ON((*drv)->eoi_write == eoi_write);
(*drv)->native_eoi_write = (*drv)->eoi_write;
(*drv)->eoi_write = eoi_write;
}
}
guest trigger EOI
When the guest write EOI,’kvm_guest_apic_eoi_write’ will be called. It first check whether ‘KVM_PV_EOI_BIT’ is set. If it is, it will clear it and return. Avoid the VM-exit.
static notrace void kvm_guest_apic_eoi_write(u32 reg, u32 val)
{
/**
* This relies on __test_and_clear_bit to modify the memory
* in a way that is atomic with respect to the local CPU.
* The hypervisor only accesses this memory from the local CPU so
* there's no need for lock or memory barriers.
* An optimization barrier is implied in apic write.
*/
if (__test_and_clear_bit(KVM_PV_EOI_BIT, this_cpu_ptr(&kvm_apic_eoi)))
return;
apic->native_eoi_write(APIC_EOI, APIC_EOI_ACK);
}
blog comments powered by Disqus